GPT-5.5 API, Four Days In: Benchmarks vs Claude Opus 4.7 and Gemini 3.1 Pro
GPT-5.5 launched April 24, 2026. Real benchmark numbers across coding, reasoning, math, and long-context retrieval — plus API pricing comparison with Claude Opus 4.7 and Gemini 3.1 Pro.

TL;DR: GPT-5.5 dropped on April 24 and leads on math (FrontierMath 52.4%) and ultra-long context retrieval (MRCR 74% vs Claude’s 32.2%). Claude Opus 4.7 still owns coding (SWE-bench Pro 64.3% vs 58.6%) and reasoning (HLE 46.9% vs 41.4%). Gemini 3.1 Pro undercuts both on price by more than half. Here is exactly how to decide which one to call.
OpenAI’s four-day-old flagship costs six times more per output token than Gemini 3.1 Pro — and still loses on the two benchmarks developers run most.
Four days since GPT-5.5 shipped. The launch-week hype has been loud. The numbers are more interesting.
What GPT-5.5 Actually Changed
GPT-5.5 is a full-generation improvement over GPT-5.4, not a point release. The three headline changes: a 1-million-token context window (matching Gemini 3.1 Pro for the first time), better token efficiency at similar latency compared to GPT-5.4, and improved multimodal reasoning. OpenAI describes it as their “smartest and most intuitive model yet.”
That framing overstates things in some areas and understates it in others. The benchmarks clarify where.
Benchmark Head-to-Head: Four Categories
The three models split across task types. Picking a winner by headline number misses the point — each model has a genuine lead somewhere.
Coding (SWE-bench Pro)
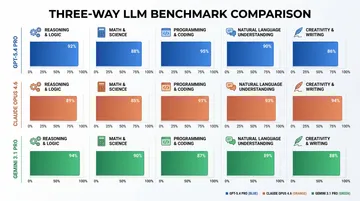
Claude Opus 4.7 leads with 64.3%, GPT-5.5 scores 58.6%. SWE-bench Pro is the harder variant — real-world GitHub issues rather than the easier Verified tier — so a 5.7-point gap carries weight. If your workload involves code generation, code review, or autonomous agents modifying a codebase, Claude Opus 4.7 is still the benchmark leader. Best AI Model for Coding 2026 breaks down where those gains show up in practice.
Reasoning (HLE — Humanity’s Last Exam)
Claude Opus 4.7 again at 46.9%. Gemini 3.1 Pro is close at 44.4%. GPT-5.5 trails at 41.4%. HLE is calibrated so that top human experts score under 10%, making the 5-point spread between Opus 4.7 and GPT-5.5 real signal rather than noise. For complex multi-step reasoning tasks, GPT-5.5 is third of three.
Math (FrontierMath)
GPT-5.5 Pro wins clearly at 52.4% on Tiers 1–3. Comparable FrontierMath scores for Claude and Gemini are not yet public. If your application involves mathematical reasoning — financial modeling, scientific computation, formal verification — GPT-5.5 Pro is the current leader by the available data.
Long-Context Retrieval (MRCR @ 512K–1M tokens)
GPT-5.5’s clearest win: 74.0% versus Claude Opus 4.7’s 32.2% on OpenAI’s MRCR v2 benchmark at ultra-long contexts. For summarizing large codebases, processing lengthy document corpora, or multi-document retrieval beyond 512K tokens, GPT-5.5 is in a different category.
Pricing: The Numbers That Drive Real Decisions
| Model | Input ($/M tokens) | Output ($/M tokens) | Context Window |
|---|---|---|---|
| GPT-5.5 Standard | $5.00 | $30.00 | 1M |
| GPT-5.5 Pro | $30.00 | $180.00 | 1M |
| Claude Opus 4.7 | $5.00 | $25.00 | 1M |
| Gemini 3.1 Pro (≤200K) | $2.00 | $12.00 | 1M |
| Gemini 3.1 Pro (>200K) | $4.00 | $18.00 | 1M |
GPT-5.5 Standard and Claude Opus 4.7 start at the same input price, but Claude is 17% cheaper on output ($25 vs $30 per million tokens). A high-volume pipeline generating 100M output tokens per month saves $500 per month by routing to Claude instead of GPT-5.5 Standard — while getting better coding and reasoning results.
GPT-5.5 Pro at $180/M output is a specialized tier. A single 10,000-token response costs $1.80. That number makes sense only for workloads where math accuracy is worth the premium — and most teams do not have those workloads.
Gemini 3.1 Pro at $12/M output is 60% cheaper than Claude and 75% cheaper than GPT-5.5 Standard. Given that Gemini 3.1 Pro scores 44.4% on HLE (within 2.5 points of Claude Opus 4.7’s 46.9%) and 54.2% on SWE-bench Pro, it earns its place as the rational default for cost-sensitive production workloads.
Which Model for Which Task
This is not a “pick one forever” decision. The pricing spread is large enough that mixing models by task type saves real money.
Claude Opus 4.7: Code generation, code review, autonomous coding agents, complex multi-step reasoning. The Claude Opus 4.7 API review covers what changed from 4.6 and migration paths.
GPT-5.5 Standard: Long-document processing beyond 512K tokens, multi-document retrieval, mathematical reasoning. Worth benchmarking against your own prompts before committing — the LLM Leaderboard has broader coverage of model-specific strengths.
GPT-5.5 Pro: Math-intensive applications where FrontierMath-level accuracy is required and cost is secondary. Narrow use case.
Gemini 3.1 Pro: High-volume production workloads, RAG pipelines, summarization, classification, anything where Gemini’s near-parity on reasoning is sufficient and the cost savings compound. Full setup details in the Gemini 3.1 Pro API guide.
API Access via ofox
ofox carries GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro via a single OpenAI-compatible endpoint. All three are accessible with one API key:
from openai import OpenAI
client = OpenAI(
api_key="your-ofox-api-key",
base_url="https://api.ofox.ai/v1"
)
response = client.chat.completions.create(
model="google/gemini-3.1-pro-preview", # or "anthropic/claude-opus-4.7" / "openai/gpt-5.5"
messages=[{"role": "user", "content": "Explain this codebase"}]
)Switching models is a one-line change. That matters when benchmarking model families against your actual workload — you can run the same prompt set against all three without touching auth or SDK code. The AI API aggregation guide covers the full setup and how to handle routing logic.
For a broader framework on choosing between these model families across use cases, the model comparison guide covers the decision tree in depth.
Verdict
GPT-5.5 earned its flagship label on math and long-context retrieval. Those are real wins, not benchmark cherry-picking. But it did not displace Claude Opus 4.7 on coding or reasoning, and the price premium over Gemini 3.1 Pro is steep enough to require justification.
The practical default for most production teams: Gemini 3.1 Pro as the volume tier, Claude Opus 4.7 for anything touching code or complex reasoning, GPT-5.5 Standard when you specifically need best-in-class long-context retrieval quality (MRCR 74% vs Claude’s 32.2%) or strong math. That split is cheaper than routing everything to GPT-5.5 Standard — and the benchmarks support it.
Routing all traffic to GPT-5.5 Standard because it is “the latest” costs 2.5× more per output token than using Gemini 3.1 Pro for the tasks where they perform within 2.5 HLE points of each other.
Pricing from OpenAI API Pricing, Anthropic Pricing, and Google AI Pricing. Benchmark data from OpenAI’s GPT-5.5 announcement (April 2026), Anthropic’s Opus 4.7 model card, and Lushbinary’s April 2026 comparison.