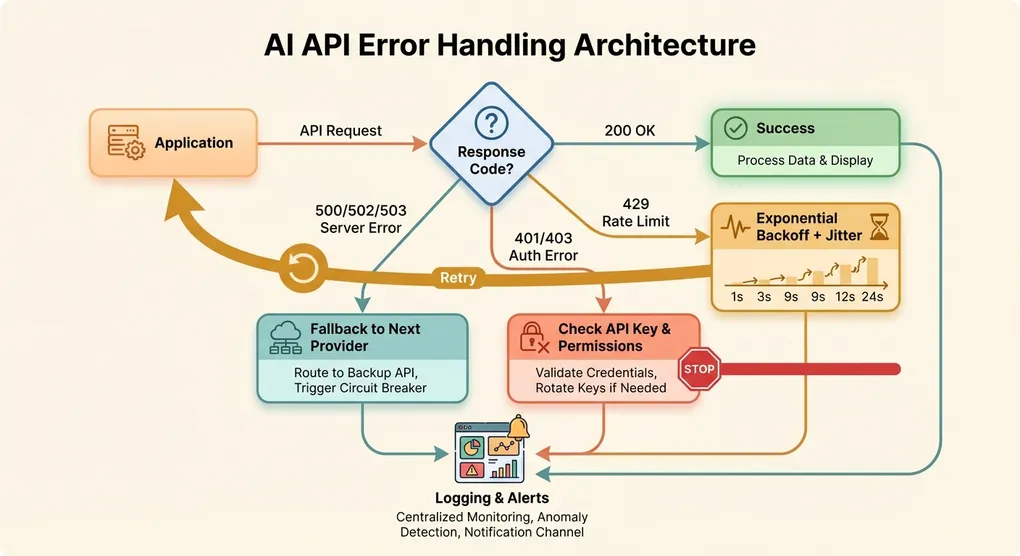
AI API Error Handling: Fix 429, 401, 500 Errors & Build Resilient Apps (2026)
TL;DR
AI API errors are inevitable in production. This guide covers every major error code you will encounter when working with OpenAI, Anthropic, and Google APIs — from 429 rate limits to 500 server failures. You will get production-ready Python code for exponential backoff with jitter, a multi-model fallback system that automatically switches providers on failure, and a circuit breaker pattern that prevents cascading failures. Stop guessing at error handling and build genuinely resilient AI applications.
Common AI API Error Codes: The Complete Reference
Before diving into solutions, here is a comprehensive overview of every HTTP error code you are likely to encounter across major AI API providers, what each one means, and whether you should retry.
| Code | Name | Meaning | Retryable? | Typical Cause |
|---|---|---|---|---|
| 400 | Bad Request | Your request is malformed or invalid | No | Exceeded context window, invalid model name, malformed JSON |
| 401 | Unauthorized | Authentication failed | No | Invalid API key, expired key, wrong endpoint |
| 403 | Forbidden | Valid key but insufficient permissions | No | Organization restrictions, model access not granted, region block |
| 408 | Request Timeout | Server didn’t receive complete request in time | Yes | Network issues, very large request payload |
| 429 | Too Many Requests | Rate limit or quota exceeded | Yes (with backoff) | Too many requests per minute, token quota exhausted |
| 500 | Internal Server Error | Something broke on the provider’s side | Yes (with backoff) | Provider infrastructure issue |
| 502 | Bad Gateway | Provider’s upstream service failed | Yes (with backoff) | Provider deployment in progress, infrastructure issue |
| 503 | Service Unavailable | Provider is temporarily overloaded | Yes (with backoff) | High demand, maintenance window |
| 504 | Gateway Timeout | Request took too long on the provider’s side | Yes (with caution) | Complex prompt, overloaded servers |
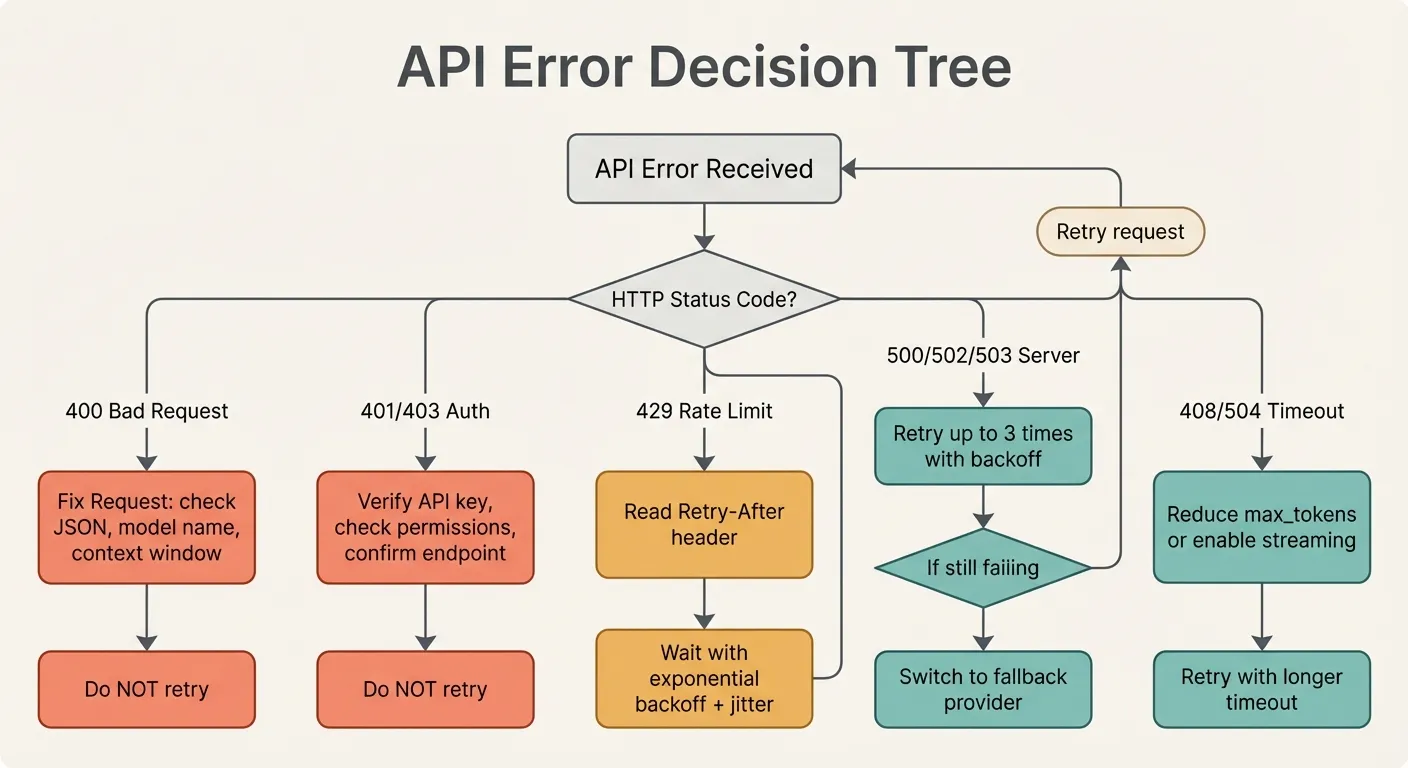
The critical distinction: 4xx errors (except 429 and 408) are your fault and require code changes. 5xx errors and 429 are the provider’s constraint and can be retried. Understanding this distinction saves you from wasting retries on requests that will never succeed.
429 Rate Limit Errors: Understanding and Handling Limits
The 429 error is the single most common error in production AI applications. Every provider imposes rate limits, and understanding how they work is essential.
How Rate Limits Work Across Providers
Rate limits come in multiple dimensions that are enforced simultaneously:
Requests per minute (RPM): The number of API calls you can make in a rolling 60-second window. For OpenAI, free tier gets 3 RPM on GPT-4-class models; paid tiers range from 500 to 10,000 RPM depending on your usage tier.
Tokens per minute (TPM): The total number of input plus output tokens processed per minute. This catches scenarios where you make few requests but each one processes massive context windows. Typical limits range from 40,000 TPM (free tier) to 2,000,000 TPM (enterprise tier).
Tokens per day (TPD): Some providers also enforce daily token budgets, particularly on free or trial plans.
Concurrent requests: Anthropic in particular limits the number of simultaneous in-flight requests, separate from per-minute limits.
Reading Rate Limit Headers
Every provider returns headers that tell you exactly where you stand:
# OpenAI headers
x-ratelimit-limit-requests: 500
x-ratelimit-remaining-requests: 487
x-ratelimit-reset-requests: 12s
x-ratelimit-limit-tokens: 200000
x-ratelimit-remaining-tokens: 182432
x-ratelimit-reset-tokens: 8s
# Anthropic headers
anthropic-ratelimit-requests-limit: 1000
anthropic-ratelimit-requests-remaining: 998
anthropic-ratelimit-requests-reset: 2026-03-09T10:00:00Z
retry-after: 30The retry-after header is your best friend. When present, it tells you exactly how many seconds to wait before retrying. Always honor this value — retrying sooner will just get you another 429.
Proactive Rate Limit Management
Rather than waiting for 429 errors, track your usage proactively:
import time
import threading
from dataclasses import dataclass, field
@dataclass
class RateLimitTracker:
"""Track API usage to avoid hitting rate limits."""
max_rpm: int = 500
max_tpm: int = 200_000
window_seconds: int = 60
_request_timestamps: list = field(default_factory=list)
_token_log: list = field(default_factory=list)
_lock: threading.Lock = field(default_factory=threading.Lock)
def _cleanup_window(self):
cutoff = time.time() - self.window_seconds
self._request_timestamps = [
t for t in self._request_timestamps if t > cutoff
]
self._token_log = [
(t, n) for t, n in self._token_log if t > cutoff
]
def can_send(self, estimated_tokens: int = 1000) -> bool:
with self._lock:
self._cleanup_window()
current_rpm = len(self._request_timestamps)
current_tpm = sum(n for _, n in self._token_log)
return (
current_rpm < self.max_rpm
and current_tpm + estimated_tokens < self.max_tpm
)
def record_request(self, tokens_used: int):
with self._lock:
now = time.time()
self._request_timestamps.append(now)
self._token_log.append((now, tokens_used))
def wait_time(self) -> float:
"""Return seconds to wait before the next request is safe."""
with self._lock:
self._cleanup_window()
if not self._request_timestamps:
return 0.0
oldest = min(self._request_timestamps)
return max(0.0, self.window_seconds - (time.time() - oldest))This approach prevents 429 errors rather than reacting to them. In high-throughput applications, proactive tracking reduces wasted latency significantly.
401/403 Authentication Errors: Diagnosing API Key Issues
Authentication errors are frustrating because they feel like they should be simple, yet they account for a disproportionate amount of debugging time.
Common 401 Causes and Fixes
Whitespace in the API key. This is the number one cause. When you copy an API key from a web dashboard, it often picks up a trailing newline or space. Always strip your keys:
import os
# Wrong — may include trailing newline from .env file
api_key = os.environ.get("OPENAI_API_KEY")
# Right — strip whitespace
api_key = os.environ.get("OPENAI_API_KEY", "").strip()Using the wrong key for the wrong provider. If you work with multiple providers, it is easy to mix up keys. OpenAI keys start with sk-, Anthropic keys start with sk-ant-, and Google keys have their own format. Add a validation check at startup:
def validate_api_key(key: str, provider: str) -> bool:
"""Quick format check for API keys."""
patterns = {
"openai": key.startswith("sk-") and not key.startswith("sk-ant-"),
"anthropic": key.startswith("sk-ant-"),
"google": len(key) == 39 and key.isalnum(),
}
if provider not in patterns:
return True # Unknown provider, skip check
return patterns[provider]Key rotation happened without updating your deployment. API keys have lifecycles. If you rotated a key in the dashboard but your server still uses the old one, you will get 401 errors. Use a secrets manager (AWS Secrets Manager, HashiCorp Vault, Doppler) instead of hardcoded environment variables.
Understanding 403 Forbidden
A 403 means your key is valid but lacks permission. Common scenarios:
- Model access not granted. Some models require explicit access approval. OpenAI’s latest models sometimes require you to be on a specific usage tier. Anthropic may require accepting additional terms for certain Claude models.
- Organization or project restrictions. If your API key is scoped to a specific project, it may not have access to all models. Check your organization settings in the provider dashboard.
- Region restrictions. Some API features or models are not available in all regions. If you are calling from a restricted geography, you may get 403 errors on specific endpoints.
- Billing issues. An expired credit card or exhausted prepaid balance can manifest as 403 rather than a more descriptive error on some providers.
Defensive Key Configuration
import sys
import os
def load_provider_config():
"""Load and validate all API keys at startup. Fail fast if misconfigured."""
required_keys = {
"OPENAI_API_KEY": "OpenAI",
"ANTHROPIC_API_KEY": "Anthropic",
}
config = {}
errors = []
for env_var, provider in required_keys.items():
value = os.environ.get(env_var, "").strip()
if not value:
errors.append(f"Missing {env_var} for {provider}")
elif not validate_api_key(value, provider.lower()):
errors.append(
f"{env_var} doesn't match expected format for {provider}"
)
else:
config[provider.lower()] = value
if errors:
for error in errors:
print(f"CONFIG ERROR: {error}", file=sys.stderr)
# Decide: fail hard or continue with available providers
if not config:
raise RuntimeError("No valid API keys configured")
return configAlways validate your configuration at application startup, not when the first request comes in. Failing fast saves debugging time.
500/502/503 Server Errors: When the Provider Is Down
Server errors mean the problem is on the provider’s side. You cannot fix the root cause, but you can handle these failures gracefully.
The Reality of Provider Outages
Every major AI API provider experiences outages. OpenAI has had multiple multi-hour outages. Anthropic has experienced rate limiting cascades that manifested as 500 errors. Google’s Vertex AI has had regional outages. These are not hypothetical risks — they are operational certainties.
The question is not whether your provider will go down, but whether your application will handle it gracefully when it does.
Distinguishing Between Transient and Extended Outages
A transient error lasts seconds to minutes. An extended outage lasts minutes to hours. Your strategy should differ:
Transient (seconds): Retry with exponential backoff. Most 500/502 errors resolve within 2-3 retries.
Extended (minutes): Switch to a fallback provider. If retries have failed 3-5 times over 30+ seconds, stop hitting the failing provider and route traffic elsewhere.
Prolonged (hours): Activate your degraded mode. Queue non-critical requests, serve cached responses where possible, and show meaningful error messages to users.
import time
from enum import Enum
class OutageSeverity(Enum):
TRANSIENT = "transient"
EXTENDED = "extended"
PROLONGED = "prolonged"
class OutageDetector:
def __init__(
self,
extended_threshold: int = 5,
prolonged_threshold: int = 20,
window_seconds: int = 300,
):
self.failures: list[float] = []
self.extended_threshold = extended_threshold
self.prolonged_threshold = prolonged_threshold
self.window_seconds = window_seconds
def record_failure(self):
self.failures.append(time.time())
self._cleanup()
def record_success(self):
self.failures.clear()
def _cleanup(self):
cutoff = time.time() - self.window_seconds
self.failures = [t for t in self.failures if t > cutoff]
def severity(self) -> OutageSeverity | None:
self._cleanup()
count = len(self.failures)
if count >= self.prolonged_threshold:
return OutageSeverity.PROLONGED
if count >= self.extended_threshold:
return OutageSeverity.EXTENDED
if count > 0:
return OutageSeverity.TRANSIENT
return NoneProvider Status Pages to Monitor
Bookmark these and integrate them into your monitoring:
- OpenAI: status.openai.com
- Anthropic: status.anthropic.com
- Google AI: status.cloud.google.com (look for Vertex AI)
- AWS Bedrock: health.aws.amazon.com
You can also subscribe to status updates via RSS, webhook, or email to get early warnings.
408/504 Timeout Errors: Handling Long-Running Requests
Timeout errors sit at the intersection of client configuration and server load. They require a nuanced approach because the request might actually be succeeding — just slowly.
Why AI API Requests Time Out
AI model inference is computationally expensive. A complex prompt with a large context window and high max_tokens setting can legitimately take 30-60 seconds. Factors that increase latency:
- Context window size. More input tokens means more processing time. A 100K-token context takes significantly longer than a 1K-token context.
- Output length. Generating 4,000 tokens takes roughly 4x as long as generating 1,000 tokens, since generation is sequential.
- Model size. Frontier models (GPT-5.4, Claude Opus 4.6) are slower than their smaller variants.
- Server load. During peak hours, inference queues build up and requests take longer.
- Reasoning models. Models with extended thinking (like Claude’s extended thinking or OpenAI’s o-series) can take significantly longer as they “think” before responding.
Setting Appropriate Timeouts
Do not use a single timeout for all requests. Match your timeout to the expected workload:
import httpx
def get_timeout_for_request(
model: str,
max_tokens: int,
input_tokens_estimate: int,
) -> float:
"""Calculate an appropriate timeout based on request parameters."""
base_timeout = 30.0 # seconds
# Larger output = more time needed
output_factor = max(1.0, max_tokens / 1000)
# Large context = more processing
context_factor = max(1.0, input_tokens_estimate / 10_000)
# Reasoning models need much more time
reasoning_models = {"o3", "o4-mini", "claude-opus"}
is_reasoning = any(r in model.lower() for r in reasoning_models)
reasoning_factor = 4.0 if is_reasoning else 1.0
timeout = base_timeout * output_factor * context_factor * reasoning_factor
return min(timeout, 300.0) # Cap at 5 minutes
# Usage
timeout = get_timeout_for_request(
model="claude-sonnet-4-6-20250514",
max_tokens=4000,
input_tokens_estimate=50_000,
)
client = httpx.Client(timeout=httpx.Timeout(timeout, connect=10.0))Streaming as a Timeout Mitigation
Streaming changes the timeout equation fundamentally. Instead of waiting for the entire response, you receive tokens as they are generated. This means:
- You get a fast initial response (first token typically arrives in 0.5-2 seconds).
- You can detect stalls — if no tokens arrive for 15 seconds mid-stream, something is wrong.
- You have partial results even if the connection drops.
from openai import OpenAI
def stream_with_stall_detection(
client: OpenAI,
messages: list[dict],
model: str = "gpt-4o",
stall_timeout: float = 15.0,
):
"""Stream a completion and detect stalls."""
import time
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
)
collected_content = []
last_chunk_time = time.time()
for chunk in stream:
now = time.time()
if now - last_chunk_time > stall_timeout:
print(f"WARNING: Stream stalled for {stall_timeout}s")
break
delta = chunk.choices[0].delta if chunk.choices else None
if delta and delta.content:
collected_content.append(delta.content)
last_chunk_time = now
return "".join(collected_content)Implementing Exponential Backoff with Jitter
This is the foundational retry pattern for any API integration. Get this right and half your error handling problems are solved.
Why Simple Retries Fail
Consider 1,000 clients all hitting a rate limit at the same instant. If they all retry after exactly 1 second, they all hit the server again simultaneously. The server rate-limits them all again. They retry after 2 seconds. Same thing. This is the thundering herd problem and it can turn a minor rate limit event into a sustained outage.
Exponential backoff spreads retries over time. Jitter adds randomness so clients do not synchronize.
Production-Ready Implementation
import time
import random
import logging
from functools import wraps
from typing import Callable, Any
import httpx
logger = logging.getLogger(__name__)
class RetryConfig:
def __init__(
self,
max_retries: int = 5,
base_delay: float = 1.0,
max_delay: float = 60.0,
exponential_base: float = 2.0,
jitter_mode: str = "full",
retryable_status_codes: tuple[int, ...] = (429, 500, 502, 503, 504),
):
self.max_retries = max_retries
self.base_delay = base_delay
self.max_delay = max_delay
self.exponential_base = exponential_base
self.jitter_mode = jitter_mode
self.retryable_status_codes = retryable_status_codes
def calculate_delay(
attempt: int,
config: RetryConfig,
retry_after: float | None = None,
) -> float:
"""Calculate delay with exponential backoff and jitter.
Supports three jitter strategies:
- full: uniform random between 0 and exponential delay
- equal: half exponential + half random
- decorrelated: delay based on previous delay with randomness
"""
if retry_after is not None:
# Provider told us exactly when to retry — respect it
return retry_after
exp_delay = config.base_delay * (config.exponential_base ** attempt)
exp_delay = min(exp_delay, config.max_delay)
if config.jitter_mode == "full":
return random.uniform(0, exp_delay)
elif config.jitter_mode == "equal":
return exp_delay / 2 + random.uniform(0, exp_delay / 2)
else:
# decorrelated jitter
return random.uniform(config.base_delay, exp_delay)
def retry_with_backoff(config: RetryConfig | None = None):
"""Decorator that adds exponential backoff retry logic to any function."""
if config is None:
config = RetryConfig()
def decorator(func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
last_exception = None
for attempt in range(config.max_retries + 1):
try:
return func(*args, **kwargs)
except httpx.HTTPStatusError as e:
status = e.response.status_code
last_exception = e
if status not in config.retryable_status_codes:
logger.error(
"Non-retryable error %d: %s",
status,
e.response.text[:200],
)
raise
if attempt == config.max_retries:
logger.error(
"Max retries (%d) exhausted for status %d",
config.max_retries,
status,
)
raise
# Check for Retry-After header
retry_after = e.response.headers.get("retry-after")
retry_after_seconds = (
float(retry_after) if retry_after else None
)
delay = calculate_delay(
attempt, config, retry_after_seconds
)
logger.warning(
"Attempt %d/%d failed with %d. "
"Retrying in %.2fs...",
attempt + 1,
config.max_retries,
status,
delay,
)
time.sleep(delay)
except httpx.TimeoutException as e:
last_exception = e
if attempt == config.max_retries:
raise
delay = calculate_delay(attempt, config)
logger.warning(
"Attempt %d/%d timed out. Retrying in %.2fs...",
attempt + 1,
config.max_retries,
delay,
)
time.sleep(delay)
raise last_exception # type: ignore[misc]
return wrapper
return decorator
# Usage example
@retry_with_backoff(RetryConfig(max_retries=4, base_delay=1.0))
def call_ai_api(prompt: str, model: str = "gpt-4o") -> str:
client = httpx.Client(timeout=60.0)
response = client.post(
"https://api.openai.com/v1/chat/completions",
headers={"Authorization": f"Bearer {api_key}"},
json={
"model": model,
"messages": [{"role": "user", "content": prompt}],
},
)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"]Choosing a Jitter Strategy
The three jitter modes produce different retry distributions:
- Full jitter (
random.uniform(0, exp_delay)) provides the widest spread and works best when you have many clients. - Equal jitter (
exp_delay/2 + random.uniform(0, exp_delay/2)) guarantees at least half the exponential wait, providing a floor. - Decorrelated jitter (
random.uniform(base, exp_delay)) produces the most uniform spread across the delay range.
AWS’s research shows that full jitter produces the lowest total completion time when many clients contend for the same resource. Use full jitter as your default.
Multi-Model Fallback Architecture
Retrying the same provider works for transient errors. For extended outages, you need to fail over to a different model or provider entirely.
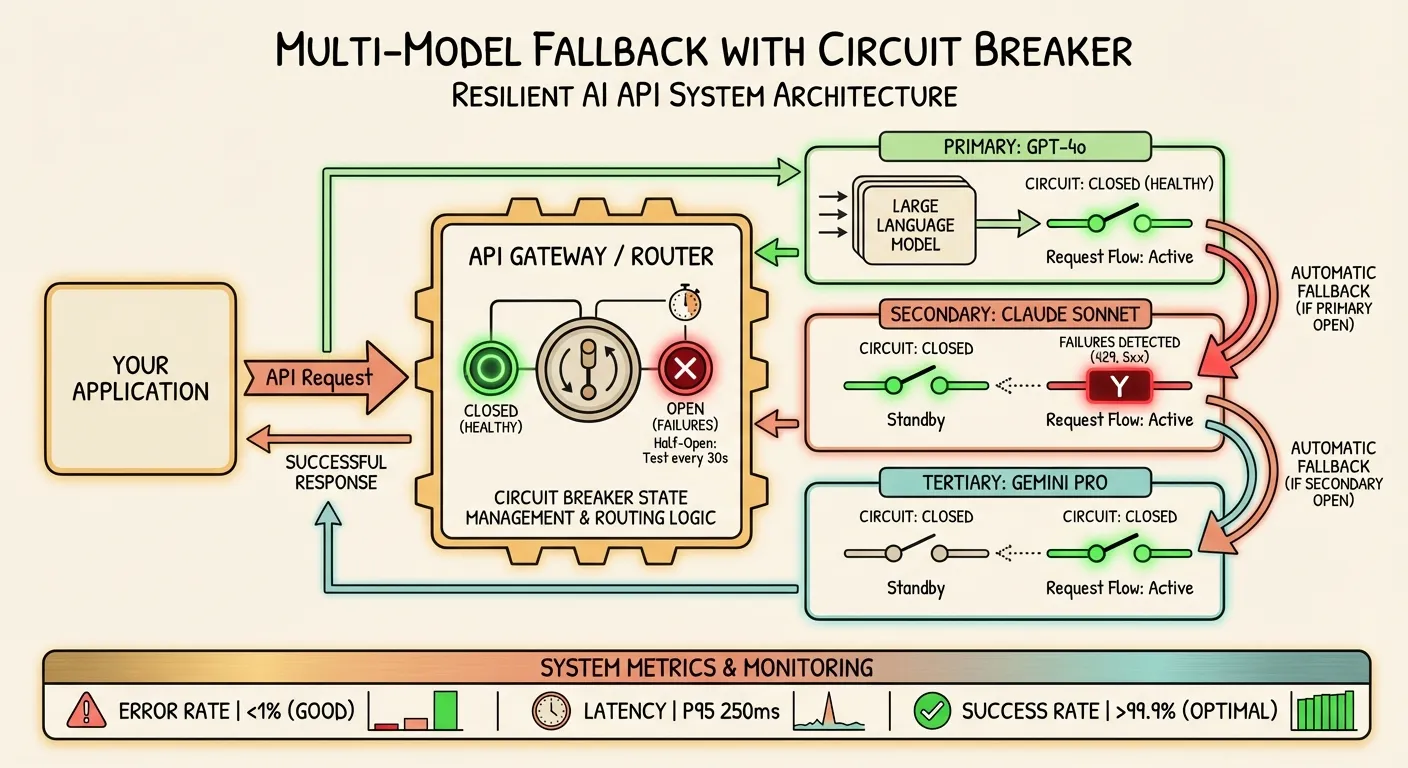
The Fallback Chain Pattern
import time
import logging
from dataclasses import dataclass
from openai import OpenAI, APIError, APITimeoutError, RateLimitError
logger = logging.getLogger(__name__)
@dataclass
class ModelEndpoint:
"""Represents one model endpoint in the fallback chain."""
name: str
model: str
base_url: str
api_key: str
timeout: float = 60.0
max_retries: int = 2
class FallbackChain:
"""Try multiple models in order, falling back on failure."""
def __init__(self, endpoints: list[ModelEndpoint]):
self.endpoints = endpoints
self._clients: dict[str, OpenAI] = {}
def _get_client(self, endpoint: ModelEndpoint) -> OpenAI:
if endpoint.name not in self._clients:
self._clients[endpoint.name] = OpenAI(
api_key=endpoint.api_key,
base_url=endpoint.base_url,
timeout=endpoint.timeout,
max_retries=endpoint.max_retries,
)
return self._clients[endpoint.name]
def complete(
self,
messages: list[dict],
max_tokens: int = 1024,
temperature: float = 0.7,
) -> dict:
"""Try each endpoint in order until one succeeds.
Returns a dict with 'content', 'model', 'provider', and 'attempts'.
"""
errors = []
for i, endpoint in enumerate(self.endpoints):
try:
logger.info(
"Attempting %s (%s) [%d/%d]",
endpoint.name,
endpoint.model,
i + 1,
len(self.endpoints),
)
start = time.time()
client = self._get_client(endpoint)
response = client.chat.completions.create(
model=endpoint.model,
messages=messages,
max_tokens=max_tokens,
temperature=temperature,
)
elapsed = time.time() - start
content = response.choices[0].message.content
logger.info(
"Success with %s in %.2fs (%d tokens)",
endpoint.name,
elapsed,
response.usage.total_tokens if response.usage else 0,
)
return {
"content": content,
"model": endpoint.model,
"provider": endpoint.name,
"attempts": i + 1,
"latency": elapsed,
}
except (APIError, APITimeoutError, RateLimitError) as e:
logger.warning(
"Failed on %s: %s",
endpoint.name,
str(e)[:200],
)
errors.append((endpoint.name, str(e)))
continue
# All endpoints failed
error_summary = "; ".join(
f"{name}: {err[:100]}" for name, err in errors
)
raise RuntimeError(
f"All {len(self.endpoints)} endpoints failed: {error_summary}"
)
# Production configuration example
fallback = FallbackChain([
ModelEndpoint(
name="openai-primary",
model="gpt-4o",
base_url="https://api.openai.com/v1",
api_key="sk-...",
),
ModelEndpoint(
name="anthropic",
model="claude-sonnet-4-6-20250514",
base_url="https://api.anthropic.com/v1",
api_key="sk-ant-...",
),
ModelEndpoint(
name="aggregator",
model="gpt-4o",
base_url="https://api.ofox.ai/v1",
api_key="ofox-...",
timeout=90.0,
),
])
result = fallback.complete(
messages=[{"role": "user", "content": "Explain quantum computing"}],
)
print(f"Answered by {result['provider']} using {result['model']}")Why an Aggregation Platform Simplifies Fallback
One approach that reduces the complexity of multi-provider fallback is using an API aggregation platform. Services like Ofox.ai, OpenRouter, or similar platforms provide a single endpoint with access to models from multiple providers. Instead of managing separate API keys and base URLs for each provider, you configure one endpoint and change only the model name.
This does not eliminate the need for fallback logic — any single endpoint can fail — but it consolidates your provider management and often provides built-in routing between models. The trade-off is a slight increase in latency (one extra network hop) and dependence on an additional service.
Circuit Breaker Pattern for API Calls
The circuit breaker pattern prevents your application from repeatedly calling a failing service, wasting time and resources.
How It Works
A circuit breaker has three states:
- Closed (normal): Requests pass through normally. Failures are counted.
- Open (failing): Requests are immediately rejected without calling the service. This prevents wasting time on a known-failing provider.
- Half-open (testing): After a cooldown period, a limited number of test requests are allowed through. If they succeed, the circuit closes. If they fail, it opens again.
Implementation
import time
import threading
import logging
from enum import Enum
logger = logging.getLogger(__name__)
class CircuitState(Enum):
CLOSED = "closed"
OPEN = "open"
HALF_OPEN = "half_open"
class CircuitBreaker:
"""Circuit breaker for API endpoints.
Args:
name: Identifier for this circuit (e.g., provider name).
failure_threshold: Number of failures before opening the circuit.
recovery_timeout: Seconds to wait before trying half-open.
half_open_max_calls: Max test calls in half-open state.
success_threshold: Successes needed in half-open to close circuit.
window_seconds: Rolling window for counting failures.
"""
def __init__(
self,
name: str,
failure_threshold: int = 5,
recovery_timeout: float = 60.0,
half_open_max_calls: int = 3,
success_threshold: int = 2,
window_seconds: float = 120.0,
):
self.name = name
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.half_open_max_calls = half_open_max_calls
self.success_threshold = success_threshold
self.window_seconds = window_seconds
self._state = CircuitState.CLOSED
self._failures: list[float] = []
self._last_failure_time: float = 0
self._half_open_successes = 0
self._half_open_calls = 0
self._lock = threading.Lock()
@property
def state(self) -> CircuitState:
with self._lock:
if self._state == CircuitState.OPEN:
if time.time() - self._last_failure_time > self.recovery_timeout:
self._state = CircuitState.HALF_OPEN
self._half_open_successes = 0
self._half_open_calls = 0
logger.info(
"Circuit %s transitioning to HALF_OPEN", self.name
)
return self._state
def allow_request(self) -> bool:
"""Check if a request should be allowed through."""
current_state = self.state
if current_state == CircuitState.CLOSED:
return True
elif current_state == CircuitState.OPEN:
return False
else: # HALF_OPEN
with self._lock:
if self._half_open_calls < self.half_open_max_calls:
self._half_open_calls += 1
return True
return False
def record_success(self):
"""Record a successful call."""
with self._lock:
if self._state == CircuitState.HALF_OPEN:
self._half_open_successes += 1
if self._half_open_successes >= self.success_threshold:
self._state = CircuitState.CLOSED
self._failures.clear()
logger.info("Circuit %s CLOSED (recovered)", self.name)
# In closed state, just continue normally
def record_failure(self):
"""Record a failed call."""
with self._lock:
now = time.time()
self._failures.append(now)
self._last_failure_time = now
# Clean old failures outside the window
cutoff = now - self.window_seconds
self._failures = [t for t in self._failures if t > cutoff]
if self._state == CircuitState.HALF_OPEN:
self._state = CircuitState.OPEN
logger.warning(
"Circuit %s OPEN (half-open test failed)", self.name
)
elif len(self._failures) >= self.failure_threshold:
self._state = CircuitState.OPEN
logger.warning(
"Circuit %s OPEN (%d failures in %ds)",
self.name,
len(self._failures),
self.window_seconds,
)
class ResilientAPIClient:
"""API client combining circuit breakers with fallback."""
def __init__(self, endpoints: list[ModelEndpoint]):
self.endpoints = endpoints
self.breakers = {
ep.name: CircuitBreaker(ep.name) for ep in endpoints
}
self._fallback = FallbackChain(endpoints)
def complete(self, messages: list[dict], **kwargs) -> dict:
"""Route request through circuit breakers with fallback."""
for endpoint in self.endpoints:
breaker = self.breakers[endpoint.name]
if not breaker.allow_request():
logger.info(
"Circuit open for %s, skipping", endpoint.name
)
continue
try:
# Use the endpoint directly
client = self._fallback._get_client(endpoint)
response = client.chat.completions.create(
model=endpoint.model,
messages=messages,
**kwargs,
)
breaker.record_success()
return {
"content": response.choices[0].message.content,
"model": endpoint.model,
"provider": endpoint.name,
}
except Exception as e:
breaker.record_failure()
logger.warning(
"Circuit %s recorded failure: %s",
endpoint.name,
str(e)[:100],
)
continue
raise RuntimeError("All circuits open or all endpoints failed")Tuning Circuit Breaker Parameters
Getting the parameters right matters. Too sensitive and the circuit trips on transient errors. Too lenient and requests pile up against a dead provider.
Recommended starting values:
| Parameter | Value | Rationale |
|---|---|---|
failure_threshold | 5 | Allows for occasional errors without tripping |
recovery_timeout | 60s | Long enough for most transient issues to resolve |
window_seconds | 120s | Captures recent failure patterns without over-penalizing historical errors |
half_open_max_calls | 3 | Enough to test recovery without overwhelming a fragile service |
success_threshold | 2 | Requires consistent success before fully trusting the service again |
Monitoring and Alerting Best Practices
Error handling code is only useful if you know it is being triggered. Monitoring turns reactive debugging into proactive incident response.
What to Track
For every AI API call, log these fields:
import time
import json
import logging
from dataclasses import dataclass, asdict
logger = logging.getLogger("api_metrics")
@dataclass
class APICallMetric:
timestamp: float
provider: str
model: str
status_code: int
latency_ms: float
input_tokens: int
output_tokens: int
is_retry: bool
retry_count: int
error_type: str | None = None
error_message: str | None = None
circuit_state: str | None = None
def log(self):
logger.info(json.dumps(asdict(self)))
# After each API call
metric = APICallMetric(
timestamp=time.time(),
provider="openai",
model="gpt-4o",
status_code=200,
latency_ms=1523.4,
input_tokens=1200,
output_tokens=450,
is_retry=False,
retry_count=0,
)
metric.log()Alert Thresholds
Set up alerts for these conditions:
| Metric | Warning Threshold | Critical Threshold |
|---|---|---|
| Error rate | >2% over 5 min | >10% over 5 min |
| P95 latency | >10s | >30s |
| 429 rate | >5/min | >20/min |
| Circuit opens | Any | Multiple circuits open |
| Fallback usage | >10% of requests | >50% of requests |
| Daily cost | >120% of budget | >150% of budget |
Recommended Monitoring Stack
For production AI applications, consider these monitoring approaches:
Lightweight (startup): Structured JSON logs with a log aggregator like Loki or CloudWatch Logs. Query for error patterns manually.
Mid-scale: Prometheus metrics exported from your application, with Grafana dashboards. Create counters for each status code per provider and histograms for latency.
Enterprise: Dedicated AI observability tools like Helicone, LangSmith, or Langfuse. These are purpose-built for LLM applications and track tokens, costs, latency, and error rates with minimal setup.
Whichever approach you choose, the critical thing is that you have visibility. Flying blind with AI APIs in production is a recipe for surprise bills and silent failures.
Provider-Specific Quirks and Tips
Each AI API provider has unique behaviors that can trip you up if you only read the generic HTTP specification.
OpenAI
- Streaming and errors. When streaming, OpenAI may return a 200 status code initially and then send an error mid-stream as a JSON object in the event stream. Your streaming parser must handle this case.
- Organization headers. If your key belongs to multiple organizations, you must include the
OpenAI-Organizationheader. Missing this header can cause unexpected 401 errors or charges to the wrong organization. - Deprecated model names. OpenAI frequently deprecates model aliases.
gpt-4-turbomay stop working without notice as they update model routing. Pin to specific model versions (e.g.,gpt-4-turbo-2024-04-09) in production. - Batch API timeouts. Batch API jobs can silently fail if the batch is too large. Monitor batch job status rather than assuming completion.
Anthropic (Claude)
- Different error format. Anthropic returns
{"type": "error", "error": {"type": "overloaded_error", "message": "..."}}rather than the OpenAI-style format. If you are using a generic error parser, handle both formats. - Overloaded vs. rate limited. Anthropic distinguishes between 429 (rate limited — you are sending too fast) and 529 (overloaded — their servers are at capacity). The 529 status code is non-standard and some HTTP libraries may not handle it gracefully.
- Message ordering. Claude requires strict alternating user/assistant messages. A 400 error with
messages: roles must alternatemeans you have consecutive messages from the same role. - Streaming format. Anthropic uses Server-Sent Events (SSE) but with a different event structure than OpenAI. The event types (
message_start,content_block_delta,message_stop) require specific parsing.
Google (Gemini)
- Authentication model. Google uses OAuth2 or API keys depending on whether you are using the Gemini API directly or through Vertex AI. Vertex AI requires a service account and project ID, not a simple API key.
- Region-specific endpoints. Vertex AI endpoints are regional. Using the wrong region can cause 404 errors or increased latency.
- Safety filters. Gemini has aggressive default safety filters that can block requests with a 400-like response even for benign content. You may need to adjust
safetySettingsin your request. - Rate limit structure. Google’s rate limits are per-project and per-region, not per-key. Two different API keys in the same project share the same rate limit.
Cross-Provider Normalization
If you are building applications that work across providers, normalize error responses:
from dataclasses import dataclass
@dataclass
class NormalizedError:
provider: str
status_code: int
error_type: str
message: str
retryable: bool
retry_after: float | None = None
def normalize_error(
provider: str,
status_code: int,
response_body: dict,
) -> NormalizedError:
"""Normalize error responses from different providers."""
retryable_codes = {429, 500, 502, 503, 504, 529}
if provider == "openai":
error = response_body.get("error", {})
return NormalizedError(
provider=provider,
status_code=status_code,
error_type=error.get("type", "unknown"),
message=error.get("message", "Unknown error"),
retryable=status_code in retryable_codes,
)
elif provider == "anthropic":
error = response_body.get("error", {})
return NormalizedError(
provider=provider,
status_code=status_code,
error_type=error.get("type", "unknown"),
message=error.get("message", "Unknown error"),
retryable=status_code in retryable_codes,
)
elif provider == "google":
error = response_body.get("error", {})
return NormalizedError(
provider=provider,
status_code=error.get("code", status_code),
error_type=error.get("status", "UNKNOWN"),
message=error.get("message", "Unknown error"),
retryable=status_code in retryable_codes,
)
else:
return NormalizedError(
provider=provider,
status_code=status_code,
error_type="unknown",
message=str(response_body),
retryable=status_code in retryable_codes,
)Putting It All Together: A Production Error Handling Template
Here is a complete, production-ready template that combines everything in this guide:
"""
Production AI API client with comprehensive error handling.
Features:
- Exponential backoff with jitter
- Multi-model fallback
- Circuit breakers per provider
- Structured logging
- Timeout management
"""
import os
import time
import random
import logging
import threading
from dataclasses import dataclass
from enum import Enum
from openai import OpenAI, APIError, APITimeoutError, RateLimitError
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("ai_client")
@dataclass
class ProviderConfig:
name: str
model: str
base_url: str
api_key: str
timeout: float = 60.0
max_retries: int = 2
priority: int = 0 # Lower = higher priority
class ProductionAIClient:
"""Full-featured AI client with resilience patterns."""
def __init__(self, providers: list[ProviderConfig]):
self.providers = sorted(providers, key=lambda p: p.priority)
self._clients: dict[str, OpenAI] = {}
self._breakers: dict[str, CircuitBreaker] = {
p.name: CircuitBreaker(
name=p.name,
failure_threshold=5,
recovery_timeout=60.0,
)
for p in providers
}
def _get_client(self, config: ProviderConfig) -> OpenAI:
if config.name not in self._clients:
self._clients[config.name] = OpenAI(
api_key=config.api_key,
base_url=config.base_url,
timeout=config.timeout,
max_retries=0, # We handle retries ourselves
)
return self._clients[config.name]
def _attempt_with_retry(
self,
config: ProviderConfig,
messages: list[dict],
max_tokens: int,
temperature: float,
) -> dict | None:
"""Attempt a request with retries on a single provider."""
client = self._get_client(config)
breaker = self._breakers[config.name]
for attempt in range(config.max_retries + 1):
if not breaker.allow_request():
return None
try:
start = time.time()
response = client.chat.completions.create(
model=config.model,
messages=messages,
max_tokens=max_tokens,
temperature=temperature,
)
latency = time.time() - start
breaker.record_success()
logger.info(
"Success: provider=%s model=%s latency=%.2fs tokens=%d",
config.name,
config.model,
latency,
response.usage.total_tokens if response.usage else 0,
)
return {
"content": response.choices[0].message.content,
"model": config.model,
"provider": config.name,
"latency": latency,
"tokens": (
response.usage.total_tokens
if response.usage
else None
),
}
except RateLimitError as e:
breaker.record_failure()
retry_after = getattr(e, "retry_after", None)
delay = retry_after or (2 ** attempt + random.random())
logger.warning(
"Rate limited on %s, attempt %d, waiting %.1fs",
config.name,
attempt + 1,
delay,
)
if attempt < config.max_retries:
time.sleep(delay)
except APITimeoutError:
breaker.record_failure()
logger.warning(
"Timeout on %s, attempt %d", config.name, attempt + 1
)
except APIError as e:
breaker.record_failure()
status = getattr(e, "status_code", 0)
if status in (400, 401, 403):
logger.error(
"Non-retryable error %d on %s: %s",
status,
config.name,
str(e)[:200],
)
break # Don't retry client errors
logger.warning(
"API error %d on %s, attempt %d",
status,
config.name,
attempt + 1,
)
if attempt < config.max_retries:
time.sleep(2 ** attempt + random.random())
return None
def complete(
self,
messages: list[dict],
max_tokens: int = 1024,
temperature: float = 0.7,
) -> dict:
"""Send a completion request with full resilience.
Tries each provider in priority order with retries and
circuit breakers.
"""
for config in self.providers:
result = self._attempt_with_retry(
config, messages, max_tokens, temperature
)
if result is not None:
return result
raise RuntimeError(
"All providers exhausted. Check circuit breaker states: "
+ ", ".join(
f"{name}={b.state.value}"
for name, b in self._breakers.items()
)
)
# Example usage
if __name__ == "__main__":
client = ProductionAIClient([
ProviderConfig(
name="openai",
model="gpt-4o",
base_url="https://api.openai.com/v1",
api_key=os.environ.get("OPENAI_API_KEY", ""),
priority=0,
),
ProviderConfig(
name="anthropic",
model="claude-sonnet-4-6-20250514",
base_url="https://api.anthropic.com/v1",
api_key=os.environ.get("ANTHROPIC_API_KEY", ""),
priority=1,
),
ProviderConfig(
name="google",
model="gemini-3-pro",
base_url="https://generativelanguage.googleapis.com/v1beta",
api_key=os.environ.get("GOOGLE_API_KEY", ""),
priority=2,
),
])
response = client.complete(
messages=[{"role": "user", "content": "Hello, world!"}],
)
print(f"Response from {response['provider']}: {response['content']}")This template gives you a solid foundation. Adapt the provider list, timeout values, and circuit breaker parameters to your specific workload.
Key Takeaways
- Categorize errors immediately. Is it retryable (429, 5xx) or a client bug (400, 401, 403)? This determines your entire response strategy.
- Always use exponential backoff with full jitter. Simple fixed-delay retries cause thundering herd problems at scale.
- Build multi-provider fallback from day one. It is vastly easier to add before your first outage than during one. Using an OpenAI-compatible aggregation service like Ofox.ai or similar platforms can simplify this by providing access to multiple models through a single endpoint.
- Implement circuit breakers for production traffic. They prevent cascading failures and reduce wasted latency against failing providers.
- Monitor everything. Log status codes, latency, token counts, and retry counts. Set alerts before things break, not after.
- Validate configuration at startup. Catch missing or malformed API keys before they cause runtime 401 errors.
- Use streaming for long requests. It mitigates timeout issues and gives you partial results on failure.
- Respect Retry-After headers. The provider is telling you exactly when it is safe to retry. Ignoring it wastes resources and may get your key temporarily banned.
Error handling is not glamorous work, but it is the difference between a demo and a production application. Build these patterns in early and you will save yourself from 3 a.m. pages when a provider goes down.