Embedding API 向量化完全指南:RAG 开发必备的模型选型与实战(2026)
摘要
- Embedding API 是 RAG(检索增强生成)的核心组件,负责将文本转为向量用于语义检索
- 2026 年四大主流模型:OpenAI text-embedding-3(性价比王)、Cohere Embed v4(多模态)、BGE-M3(开源全能)、Qwen3-Embedding(中文最强)
- 国内开发者通过 API 聚合平台可直接调用所有模型,无需额外配置
- 本文提供完整的 Python 代码示例,从单条文本向量化到完整 RAG 管道搭建
目录
- 什么是 Embedding?为什么 RAG 离不开它
- 四大 Embedding 模型横评
- Python 实战:5 分钟调通 Embedding API
- 搭建完整 RAG 检索管道
- 成本优化:省 80% 的实战技巧
- 常见踩坑与排错
- FAQ
- 总结与行动建议
什么是 Embedding?为什么 RAG 离不开它
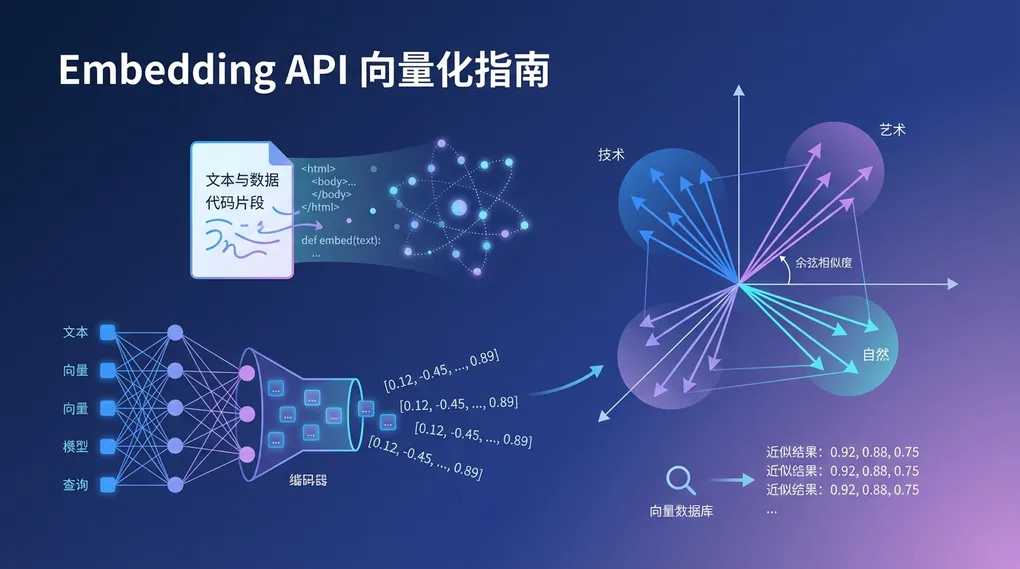
你让 GPT 回答一个关于公司内部文档的问题,它回答不了——因为它没见过你的数据。RAG(Retrieval-Augmented Generation)就是解决这个问题的标准方案:先从知识库里检索相关文档片段,再把片段塞进 prompt 让大模型生成回答。
检索的关键就是 Embedding。
传统关键词搜索靠字面匹配,搜「如何降低 API 成本」找不到「省钱技巧」。Embedding 则把文本映射到高维向量空间,语义相近的文本在向量空间中距离相近。这意味着:
"如何降低 API 成本" → [0.12, -0.45, ..., 0.89] (1536维)
"省钱技巧" → [0.11, -0.44, ..., 0.88] (1536维)
余弦相似度: 0.95 ✅ 语义匹配一个典型的 RAG 流程:
用户提问 → Embedding API 向量化 → 向量数据库检索 Top-K → 拼接 Prompt → LLM 生成回答Embedding API 就是这条链路的第一环,选错模型,后面全白搭。
四大 Embedding 模型横评(2026)
| 模型 | 厂商 | 维度 | 最大 Token | MTEB 得分 | 价格(/百万 token) | 亮点 |
|---|---|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | 8192 | 62.3 | $0.02 | 性价比之王 |
| text-embedding-3-large | OpenAI | 3072 | 8192 | 64.6 | $0.13 | 高精度场景 |
| Embed v4 | Cohere | 1536 | 128K | 65.2 | $0.12 | 多模态、超长上下文 |
| BGE-M3 | BAAI | 1024 | 8192 | 63.0 | 免费(开源) | 100+ 语言、混合检索 |
| Qwen3-Embedding-8B | 阿里巴巴 | 4096 | 32768 | 70.58 | 免费(开源) | MTEB 多语言第一 |
OpenAI text-embedding-3:标杆级产品
OpenAI 在 2024 年初发布的第三代 Embedding 模型,目前仍是 API 调用量最大的 Embedding 服务。两个版本:
- small:1536 维,$0.02/百万 token,适合 90% 的 RAG 场景
- large:3072 维,$0.13/百万 token,需要更高精度时使用
支持 Matryoshka Embedding(俄罗斯套娃嵌入),可以截断维度而不大幅损失性能。比如 large 模型截断到 1024 维,MTEB 得分仍高于 small 的 1536 维,但存储成本降低 66%。
Cohere Embed v4:多模态新王
2025 年发布的 Embed v4 是第一个真正实用的多模态 Embedding 模型:
- 文本 + 图片混合输入:一个请求同时处理文档文字和插图
- 128K 超长上下文:直接处理整篇论文、合同,不用分块
- 多种量化格式:float、int8、binary,存储成本可压缩 32 倍
适合文档理解、多模态搜索等企业级场景,但价格是 OpenAI small 的 6 倍。
BGE-M3:开源全能选手
北京智源研究院(BAAI)的开源模型,名字里的三个 M:
- Multi-Lingual:支持 100+ 语言
- Multi-Granularity:处理短句到 8192 token 长文
- Multi-Functionality:同时支持密集检索、稀疏检索、多向量检索
一个模型三种检索方式,混合使用效果通常优于单一方式。可以本地部署,零 API 成本。
Qwen3-Embedding:中文最强
阿里巴巴的 Qwen3-Embedding-8B 目前在 MTEB 多语言排行榜上排名第一(得分 70.58),中文场景表现尤其突出。
- 4096 维向量,32K 上下文窗口
- 开源可本地部署,也可通过 DashScope API 调用
- 8B 参数量,需要 GPU 推理
如果你的 RAG 应用主要面向中文用户,Qwen3-Embedding 是当前最佳选择。
怎么选?一张决策图
你的场景是什么?
├── 纯中文 RAG → Qwen3-Embedding(精度最高)
├── 多语言 / 跨语言 → BGE-M3(100+ 语言)
├── 图文混合检索 → Cohere Embed v4(多模态)
├── 快速验证 / 预算有限 → text-embedding-3-small(最便宜)
└── 高精度 + API 便捷 → text-embedding-3-large(均衡之选)Python 实战:5 分钟调通 Embedding API
方案一:直接调用 OpenAI Embedding API
from openai import OpenAI
# 国内开发者:通过 API 聚合平台调用,无需额外网络配置
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1" # 兼容 OpenAI 协议
)
# 单条文本向量化
response = client.embeddings.create(
model="text-embedding-3-small",
input="如何用 Python 搭建 RAG 应用?"
)
embedding = response.data[0].embedding
print(f"维度: {len(embedding)}") # 1536
print(f"前5维: {embedding[:5]}")方案二:批量向量化
实际项目中,你需要一次处理大量文档:
import time
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
def batch_embed(texts: list[str], model="text-embedding-3-small", batch_size=100):
"""批量向量化,自动分批处理"""
all_embeddings = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
response = client.embeddings.create(model=model, input=batch)
# 按原始顺序排列(API 返回顺序可能不同)
batch_embeddings = [None] * len(batch)
for item in response.data:
batch_embeddings[item.index] = item.embedding
all_embeddings.extend(batch_embeddings)
# 避免触发速率限制
if i + batch_size < len(texts):
time.sleep(0.1)
return all_embeddings
# 使用示例
documents = [
"Python 是一门通用编程语言",
"RAG 通过检索增强大模型的回答质量",
"向量数据库存储和检索高维向量",
# ... 更多文档
]
embeddings = batch_embed(documents)
print(f"处理了 {len(embeddings)} 条文档,每条 {len(embeddings[0])} 维")方案三:计算语义相似度
import numpy as np
def cosine_similarity(a, b):
"""计算两个向量的余弦相似度"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 向量化三段文本
texts = [
"如何降低 AI API 的调用成本?",
"大模型 API 省钱的实用技巧",
"今天北京天气怎么样?"
]
response = client.embeddings.create(
model="text-embedding-3-small",
input=texts
)
emb = [item.embedding for item in response.data]
print(f"语义相近: {cosine_similarity(emb[0], emb[1]):.4f}") # ~0.85
print(f"语义无关: {cosine_similarity(emb[0], emb[2]):.4f}") # ~0.15搭建完整 RAG 检索管道
下面用 100 行代码搭建一个可用的 RAG 管道,不依赖向量数据库,纯 Python 实现:
import json
import numpy as np
from openai import OpenAI
from pathlib import Path
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
class SimpleRAG:
def __init__(self, embedding_model="text-embedding-3-small"):
self.model = embedding_model
self.documents = [] # 原始文档
self.embeddings = [] # 对应向量
def add_documents(self, docs: list[str]):
"""添加文档到知识库"""
response = client.embeddings.create(model=self.model, input=docs)
for i, item in enumerate(response.data):
self.documents.append(docs[item.index])
self.embeddings.append(item.embedding)
print(f"已索引 {len(docs)} 条文档,总计 {len(self.documents)} 条")
def search(self, query: str, top_k=3) -> list[dict]:
"""语义检索 Top-K 相关文档"""
q_resp = client.embeddings.create(model=self.model, input=[query])
q_emb = np.array(q_resp.data[0].embedding)
# 计算余弦相似度
doc_embs = np.array(self.embeddings)
similarities = np.dot(doc_embs, q_emb) / (
np.linalg.norm(doc_embs, axis=1) * np.linalg.norm(q_emb)
)
# 取 Top-K
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [
{"text": self.documents[i], "score": float(similarities[i])}
for i in top_indices
]
def ask(self, question: str, top_k=3) -> str:
"""RAG 问答:检索 + 生成"""
# Step 1: 检索相关文档
results = self.search(question, top_k=top_k)
context = "\n\n".join(
f"[文档{i+1}] (相关度: {r['score']:.2f})\n{r['text']}"
for i, r in enumerate(results)
)
# Step 2: 构造 Prompt 让 LLM 回答
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4-6", # 或其他模型
messages=[
{"role": "system", "content": "基于以下参考文档回答用户问题。如果文档中没有相关信息,请如实说明。"},
{"role": "user", "content": f"参考文档:\n{context}\n\n问题:{question}"}
]
)
return response.choices[0].message.content
# 使用示例
rag = SimpleRAG()
# 添加知识库文档
rag.add_documents([
"Ofox 支持 100+ AI 模型,包括 GPT、Claude、Gemini、DeepSeek 等,统一 OpenAI 兼容接口。",
"text-embedding-3-small 价格为 $0.02/百万 token,是目前性价比最高的 Embedding 模型。",
"RAG 的检索质量直接决定最终回答质量,Embedding 模型的选择至关重要。",
"BGE-M3 支持密集检索、稀疏检索和多向量检索三种模式,混合使用效果最佳。",
"Batch API 可以将 Embedding 成本降低 50%,适合离线批量处理场景。",
])
# 语义搜索
results = rag.search("哪个 Embedding 模型最便宜?")
for r in results:
print(f"[{r['score']:.2f}] {r['text'][:60]}...")
# RAG 问答
answer = rag.ask("如何降低 Embedding 的使用成本?")
print(answer)这个极简实现用 numpy 做向量检索,适合文档量 < 10 万条的场景。超过这个量级,建议接入向量数据库(Milvus、Qdrant、Pinecone 等)。
成本优化:省 80% 的实战技巧
Embedding API 已经很便宜了,但大规模使用时成本依然可观。以下是实测有效的优化策略:
1. 选对模型,别上来就用 large
| 场景 | 推荐模型 | 成本 |
|---|---|---|
| 快速原型 / MVP | text-embedding-3-small | $0.02/M |
| 生产环境(英文) | text-embedding-3-large | $0.13/M |
| 生产环境(中文) | Qwen3-Embedding(自部署) | 仅 GPU 成本 |
| 多模态检索 | Cohere Embed v4 | $0.12/M |
大多数 RAG 场景,small 模型就够了。先用 small 跑通全流程,有数据证明精度不够再升级。
2. 用 Batch API 省 50%
OpenAI 的 Batch API 允许异步处理请求,价格直接减半:
# Batch API 示例(异步处理,24 小时内返回结果)
batch_input = {
"custom_id": "doc-001",
"method": "POST",
"url": "/v1/embeddings",
"body": {
"model": "text-embedding-3-small",
"input": "你的文本内容"
}
}适合知识库初始化、定期全量更新等不需要实时结果的场景。
3. 文本预处理降低 Token 数
import re
def preprocess_for_embedding(text: str) -> str:
"""清洗文本,减少无效 token"""
# 移除多余空白
text = re.sub(r'\s+', ' ', text).strip()
# 移除 HTML 标签
text = re.sub(r'<[^>]+>', '', text)
# 移除重复标点
text = re.sub(r'[。!?,]{2,}', '。', text)
return text实测清洗后 token 数平均减少 15-25%,直接省钱。
4. 缓存 Embedding 结果
同一段文本不要重复调用 API:
import hashlib
import json
from pathlib import Path
class EmbeddingCache:
def __init__(self, cache_dir="./embedding_cache"):
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(exist_ok=True)
def _key(self, text: str, model: str) -> str:
return hashlib.md5(f"{model}:{text}".encode()).hexdigest()
def get(self, text: str, model: str):
path = self.cache_dir / f"{self._key(text, model)}.json"
if path.exists():
return json.loads(path.read_text())
return None
def set(self, text: str, model: str, embedding: list):
path = self.cache_dir / f"{self._key(text, model)}.json"
path.write_text(json.dumps(embedding))5. Matryoshka 降维
text-embedding-3 系列支持维度截断,大幅节省存储和检索成本:
response = client.embeddings.create(
model="text-embedding-3-large",
input="你的文本",
dimensions=1024 # 从 3072 降到 1024,存储省 66%
)| 维度 | 存储(单条) | MTEB 得分 | 省存储 |
|---|---|---|---|
| 3072(默认) | 12 KB | 64.6 | - |
| 1024 | 4 KB | 63.8 | 66% |
| 512 | 2 KB | 62.5 | 83% |
| 256 | 1 KB | 60.1 | 92% |
常见踩坑与排错
踩坑 1:不同模型的向量不能混用
# ❌ 错误:用 small 模型建索引,用 large 模型查询
index_emb = embed("文档", model="text-embedding-3-small") # 1536维
query_emb = embed("查询", model="text-embedding-3-large") # 3072维
# 维度不同,无法计算相似度!解决:索引和查询必须用同一个模型。换模型 = 全量重新向量化。
踩坑 2:超长文本被静默截断
Embedding API 有最大 token 限制(text-embedding-3 为 8192 token),超出部分会被静默截断,不报错但丢信息。
import tiktoken
def safe_embed(text: str, model="text-embedding-3-small", max_tokens=8000):
"""安全向量化,超长文本自动分块"""
enc = tiktoken.encoding_for_model(model)
tokens = enc.encode(text)
if len(tokens) <= max_tokens:
return embed(text, model)
# 分块处理
chunks = []
for i in range(0, len(tokens), max_tokens):
chunk_text = enc.decode(tokens[i:i + max_tokens])
chunks.append(chunk_text)
# 返回各块向量的平均值(简单方案)
embeddings = [embed(c, model) for c in chunks]
return np.mean(embeddings, axis=0).tolist()踩坑 3:429 限流错误
高并发调用时容易触发速率限制:
from tenacity import retry, wait_exponential, stop_after_attempt
@retry(wait=wait_exponential(min=1, max=60), stop=stop_after_attempt(5))
def embed_with_retry(text, model="text-embedding-3-small"):
return client.embeddings.create(model=model, input=text)也可以通过 API 聚合平台获得更高的速率限制。在 Ofox 文档 中可以查看各模型的具体限额。
踩坑 4:中文分块策略
英文按句子分块效果不错,但中文句子边界不明显。推荐按段落 + 滑动窗口:
def chinese_chunk(text: str, chunk_size=500, overlap=50):
"""中文文本分块,按字符数 + 重叠"""
paragraphs = text.split('\n')
chunks = []
current = ""
for para in paragraphs:
if len(current) + len(para) > chunk_size:
if current:
chunks.append(current.strip())
# 保留尾部作为下一块的开头
current = current[-overlap:] + para
else:
chunks.append(para[:chunk_size])
current = para[chunk_size - overlap:]
else:
current += "\n" + para
if current.strip():
chunks.append(current.strip())
return chunksFAQ
Q: Embedding API 是什么?和大模型 Chat API 有什么区别?
Embedding API 将文本转换为高维向量(如 1536 维浮点数数组),用于语义搜索、相似度计算和 RAG 检索。Chat API 生成文本回复,Embedding API 生成数值向量。两者配合使用:先用 Embedding 检索相关文档,再用 Chat 模型生成回答。
Q: 国内开发者怎么调用 OpenAI 的 Embedding API?
OpenAI 官方 API 在国内无法直连。推荐使用兼容 OpenAI 协议的 API 聚合平台(如 Ofox),只需修改 base_url 即可用 OpenAI SDK 调用 text-embedding-3-small/large,国内阿里云节点直连延迟低。
Q: RAG 应用选哪个 Embedding 模型最好?
取决于场景:纯中文用 Qwen3-Embedding(MTEB 中文第一),多语言用 BGE-M3(支持 100+ 语言),追求性价比用 text-embedding-3-small($0.02/百万 token),企业级多模态用 Cohere Embed v4。建议在自己的数据集上做 A/B 测试。
Q: Embedding 向量维度越高越好吗?
不一定。text-embedding-3-large 的 3072 维在基准测试上优于 small 的 1536 维,但实际 RAG 场景中差距通常在 1-3% 以内。高维度意味着更大的存储成本和更慢的检索速度。推荐先用 small 模型验证,性能不够再升级。
Q: Embedding API 调用成本高吗?
Embedding 是所有 AI API 中最便宜的。text-embedding-3-small 仅 $0.02/百万 token,100 万字中文文档的向量化成本不到 $0.1。通过 Batch API 还能再降 50%。
Q: 换 Embedding 模型需要重新向量化所有数据吗?
是的。不同模型生成的向量维度和语义空间不同,不能混用。换模型意味着全量数据重新 embedding,这也是选型阶段要慎重的原因。建议在小数据集上充分测试后再大规模部署。
总结与行动建议
2026 年的 Embedding 生态已经非常成熟。对于大多数开发者,建议的行动路径:
- 快速开始:用
text-embedding-3-small+ numpy,10 分钟跑通一个 RAG demo - 评估精度:在你的实际数据上对比 2-3 个模型,看检索准确率
- 优化成本:上缓存、用 Batch API、做文本预处理
- 规模化:超过 10 万条文档接入向量数据库(Milvus / Qdrant)
国内开发者可以通过 Ofox 等 API 聚合平台,用统一的 OpenAI 兼容接口调用上述所有 Embedding 模型,一个 API Key 搞定,无需逐个对接各家 API。