Полное руководство по устранению ошибок AI API: 429, 401, 500 — решение за одну статью (2026)
Кратко
Ошибки при вызове AI API — обычное дело: 429 (ограничение частоты), 401 (ошибка аутентификации), 500 (сервер упал) — каждая может заблокировать вас на полдня. В этой статье систематически разобраны типичные ошибки трёх основных AI API — OpenAI GPT-5.4, Anthropic Claude, Google Gemini. Для каждой даны пошаговые инструкции по диагностике и готовый код продакшен-уровня. Главное: 90% ошибок 429 можно полностью решить экспоненциальным откатом + очередью запросов, оставшиеся 10% — вопрос квот. Если вы используете Cursor, Claude Code и другие AI-инструменты для программирования или создаёте AI Agent, решения из этой статьи также применимы.
Содержание
- Предпосылки: почему AI API так часто выдают ошибки?
- 429 Too Many Requests: диагностика ошибки ограничения частоты
- 401/403: ошибки аутентификации и прав доступа
- 400: ошибки параметров запроса
- 500/502/503: серверные ошибки
- 408/504: ошибки таймаута — что делать, когда API медленный
- Лучшие практики для продакшена: обработка ошибок раз и навсегда
- Таблица кодов ошибок по платформам
- Часто задаваемые вопросы (FAQ)
- Итоги и план действий
- Справочные материалы
Предпосылки: почему AI API так часто выдают ошибки?
Если вы пользовались API от OpenAI, Claude или Gemini, то наверняка сталкивались с разнообразными ошибками. То 429 (ограничение частоты), то 500 (сбой), а иногда 401, заставляющий усомниться во всём. В марте 2026 года, с выходом GPT-5.4 и Gemini 3.1 Flash-Lite, экосистема API стала ещё богаче, но и разнообразие ошибок увеличилось.
Это не ваша проблема. У AI API частота ошибок объективно выше, чем у традиционных API, по трём причинам:
- Ресурсоёмкость: каждый запрос требует GPU-ресурсов, сервер крайне чувствителен к параллельной нагрузке
- Многоуровневое ограничение: RPM (запросы в минуту), TPM (токены в минуту), RPD (запросы в день) — тройное наложение лимитов
- Нестабильность сервиса: доступность инференс-сервисов обычно 99.5%-99.9%, что на порядок ниже 99.99% у традиционных API
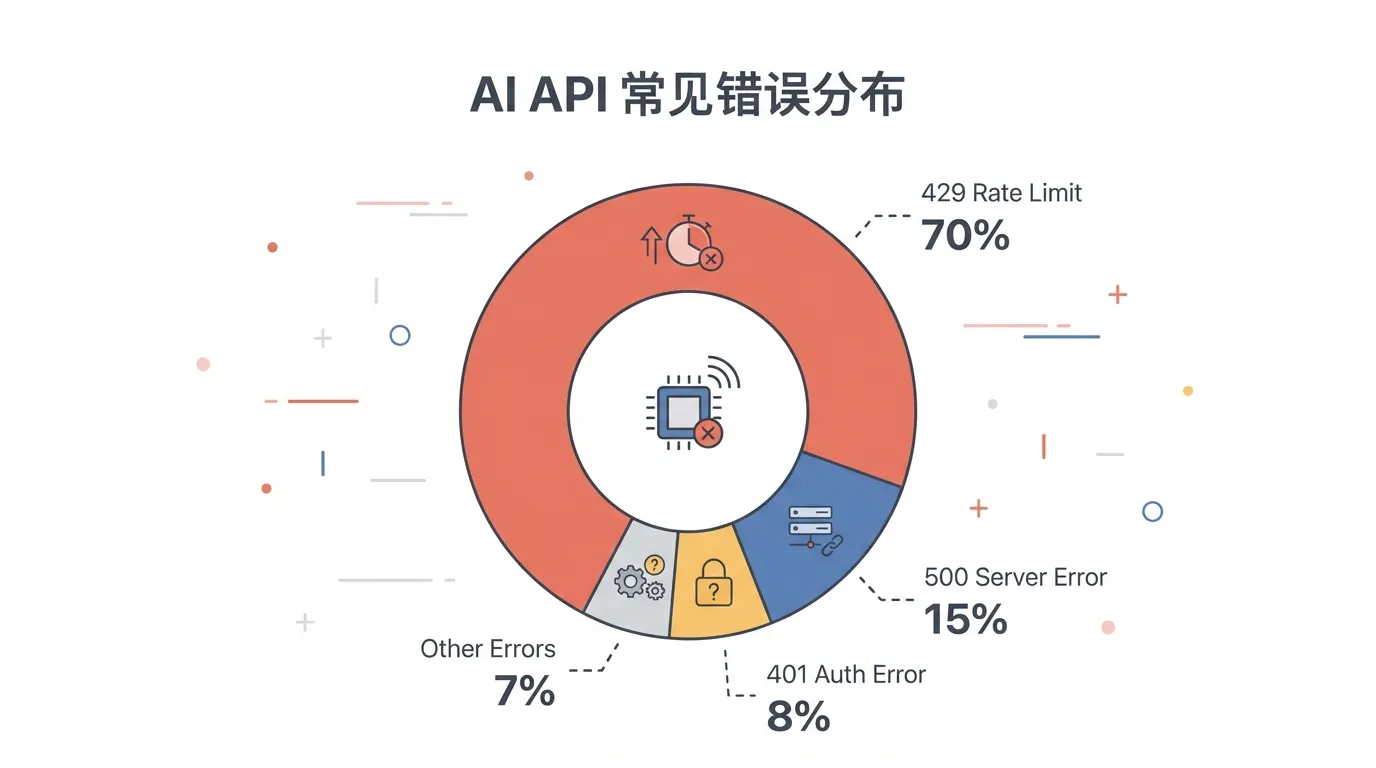
По статистике сообщества, среди ошибок AI API 429 (ограничение частоты) составляет 70%, серверные ошибки 500-й серии — 15%, проблемы аутентификации — 8%, ошибки параметров — 7%.
Разберём по порядку — от самых частых к редким.
429 Too Many Requests: диагностика ошибки ограничения частоты
429 — «старый друг» разработчика AI API: ваши запросы превысили лимит платформы.
Почему срабатывает 429?
| Причина | Описание | Типичный сценарий |
|---|---|---|
| Превышение RPM | Число запросов в минуту выше квоты | Массовые вызовы, нагрузочное тестирование |
| Превышение TPM | Потребление токенов в минуту выше квоты | Обработка длинных текстов, большой контекст |
| Исчерпание дневной квоты | Достигнут суточный лимит | Пользователи бесплатного уровня |
| Недостаточный баланс | Предоплаченные средства закончились | Забыли пополнить |
| Ограничение на уровне организации | Несколько проектов делят квоту | Командная работа |
Три шага диагностики
Шаг 1: Определите тип ограничения
Тело ответа 429 от OpenAI указывает конкретную причину:
{
"error": {
"message": "Rate limit reached for gpt-4o on tokens per min (TPM): Limit 30000, Used 28000, Requested 5000.",
"type": "tokens",
"code": "rate_limit_exceeded"
}
}Обратите внимание на поле type — tokens означает превышение TPM, requests — превышение RPM. Также проверьте заголовок Retry-After в ответе 429 — он указывает, сколько секунд ждать до следующего запроса.
Шаг 2: Проверьте текущую квоту
Где посмотреть квоту по платформам:
- OpenAI: platform.openai.com/account/limits
- Anthropic: console.anthropic.com/settings/limits
- Google: aistudio.google.com/apikey
Шаг 3: Применяйте решение по ситуации
Решение 1: Экспоненциальный откат (обязательно)
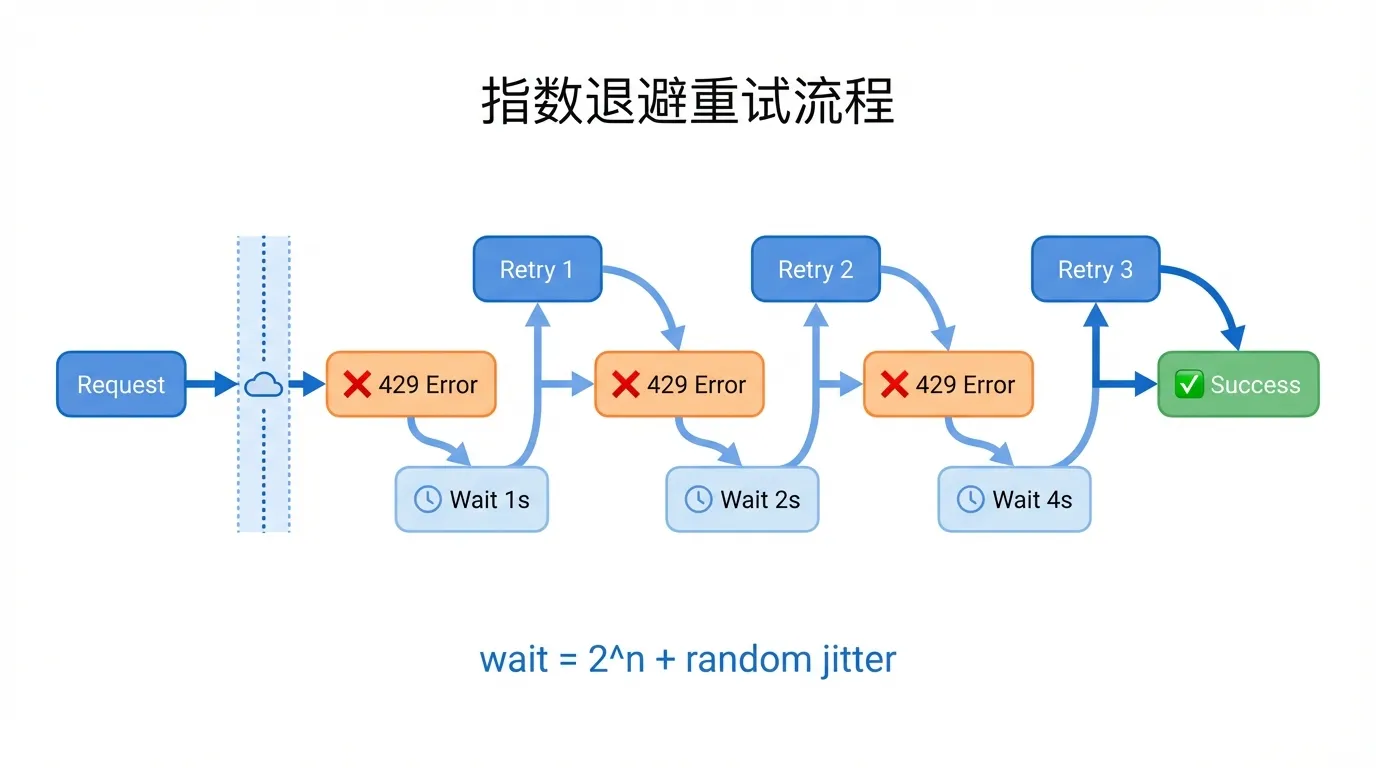
Это стандартный подход к обработке 429 — обязателен в любом продакшен-окружении:
import time
import random
from openai import OpenAI
client = OpenAI()
def call_with_retry(messages, max_retries=5):
"""Экспоненциальный откат для обработки ограничения частоты 429"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gpt-4o",
messages=messages
)
return response
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# Экспоненциальный откат + случайное отклонение
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"Ограничение частоты, ожидание {wait:.1f}с (попытка {attempt+1})")
time.sleep(wait)
else:
raiseРешение 2: Очередь запросов + ограничитель токенного бакета
Для массовой обработки активное ограничение частоты элегантнее, чем пассивные повторы:
import asyncio
from asyncio import Semaphore
class RateLimiter:
"""Ограничитель на основе токенного бакета"""
def __init__(self, rpm=50, tpm=40000):
self.rpm_semaphore = Semaphore(rpm)
self.tpm_limit = tpm
self.tpm_used = 0
async def acquire(self, estimated_tokens=500):
await self.rpm_semaphore.acquire()
while self.tpm_used + estimated_tokens > self.tpm_limit:
await asyncio.sleep(1)
self.tpm_used += estimated_tokens
def release(self):
self.rpm_semaphore.release()
# TPM сбрасывается каждую минуту (упрощённая реализация)
limiter = RateLimiter(rpm=50, tpm=40000)
async def rate_limited_call(messages):
await limiter.acquire()
try:
response = await aclient.chat.completions.create(
model="gpt-4o",
messages=messages
)
return response
finally:
limiter.release()Решение 3: Повышение Usage Tier
Если бизнесу действительно нужна более высокая квота, самый прямой способ — повышение:
| OpenAI Tier | Порог месячных расходов | GPT-4o RPM | GPT-4o TPM |
|---|---|---|---|
| Free | $0 | 3 | 40 000 |
| Tier 1 | $5 | 500 | 30 000 |
| Tier 2 | $50 | 5 000 | 450 000 |
| Tier 3 | $100 | 5 000 | 800 000 |
| Tier 4 | $250 | 10 000 | 2 000 000 |
| Tier 5 | $1 000 | 10 000 | 30 000 000 |
Решение 4: Мультимодельная балансировка нагрузки
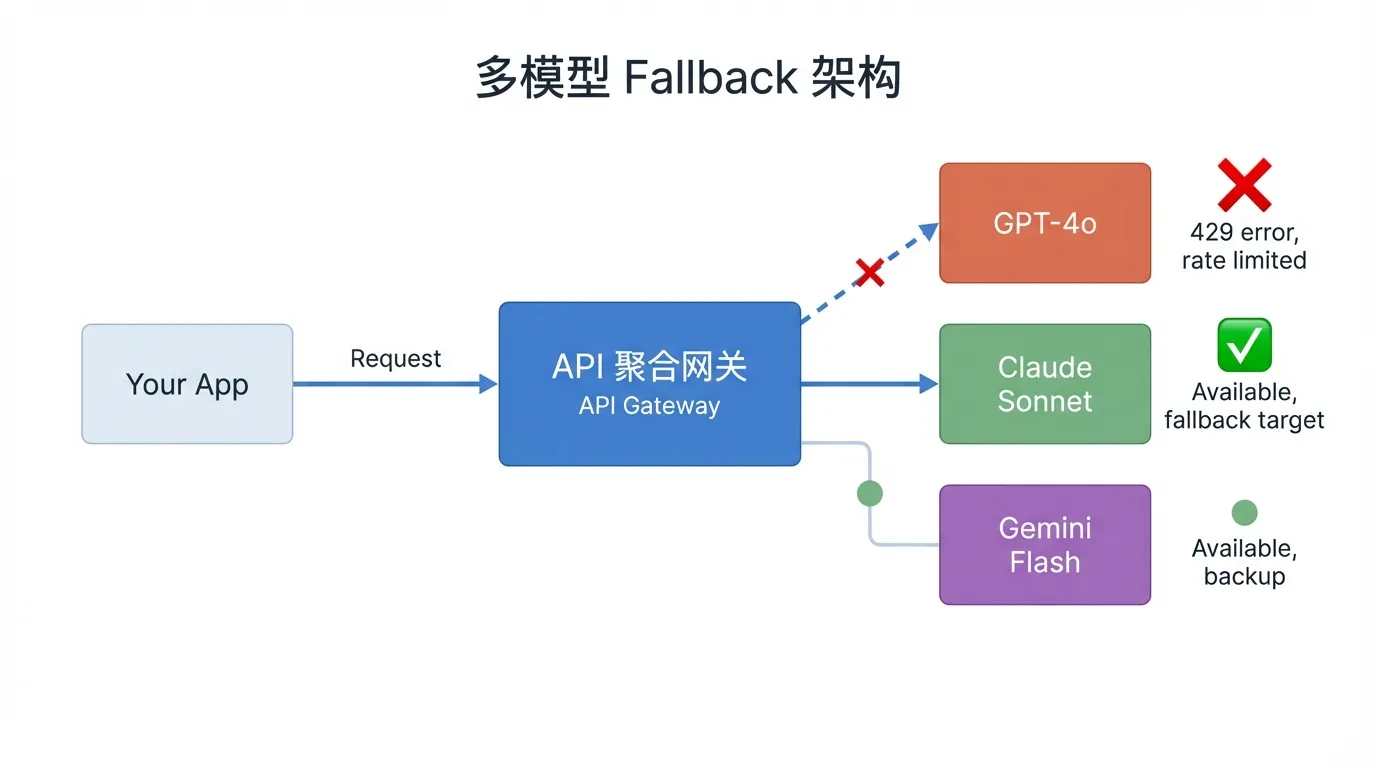
Когда квоты одного API недостаточно, можно распределить нагрузку через несколько моделей. Например, через API-шлюз-агрегатор Ofox.ai — один интерфейс для GPT, Claude, Gemini и более 50 моделей с автоматической балансировкой между провайдерами:
from openai import OpenAI
# Совместим с OpenAI SDK — достаточно сменить base_url
client = OpenAI(
api_key="your-ofox-key",
base_url="https://api.ofox.ai/v1"
)
# Автоматический fallback на резервную модель при ограничении основной
models = ["gpt-5.4", "claude-sonnet-4-20250514", "gemini-2.5-flash"]
def call_with_fallback(messages):
for model in models:
try:
return client.chat.completions.create(
model=model,
messages=messages
)
except Exception as e:
if "429" in str(e):
continue
raise
raise Exception("Все модели ограничены")Для Китая есть дополнительное преимущество — через узлы ускорения Alibaba Cloud / Volcano Cloud задержка на 50% и более ниже, чем при прямом подключении к зарубежным API.
401/403: ошибки аутентификации и прав доступа
401 Unauthorized
Три самые частые причины:
- Ошибка в API Key: лишний пробел при копировании, пропущен символ
- Ключ аннулирован: утёк на GitHub — платформа автоматически заблокировала
- Ключ истёк: некоторые платформы устанавливают срок действия
Быстрая диагностика:
# Проверка валидности ключа OpenAI
curl https://api.openai.com/v1/models \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-s | head -20
# Проверка ключа Anthropic
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "content-type: application/json" \
-H "anthropic-version: 2023-06-01" \
-d '{"model":"claude-sonnet-4-20250514","max_tokens":10,"messages":[{"role":"user","content":"hi"}]}' \
-s | head -20403 Forbidden
Разница между 403 и 401: 401 — «кто вы?», 403 — «я знаю, кто вы, но у вас нет доступа».
Частые причины:
- Недостаточные права на модель: например, GPT-4 требует Tier 1 и выше
- Региональные ограничения: некоторые модели недоступны в определённых регионах
- Права организации: организация, к которой привязан ключ, не подключила нужный сервис
Решение: проверьте настройки прав организации, к которой привязан API Key, и убедитесь в наличии доступа к модели. Если вы используете Claude API, обратитесь к руководству по использованию Claude API для полной настройки прав доступа.
400: ошибки параметров запроса
Ошибка 400 означает проблему с форматом запроса. Типичные подводные камни:
Проблемы с форматом JSON
# Неправильно: формат messages неверный
response = client.chat.completions.create(
model="gpt-4o",
messages="Помоги написать код" # Должен быть список
)
# Правильно
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Помоги написать код"}]
)Ошибка в названии модели
# Все эти варианты вызовут 400
model = "gpt4o" # Пропущен дефис
model = "gpt-4-o" # Лишний дефис
model = "claude-3.5" # Неверный формат версии
# Правильные названия моделей (март 2026)
model = "gpt-4o"
model = "gpt-5.4" # Последняя на март 2026
model = "claude-sonnet-4-20250514"
model = "gemini-2.5-flash"
model = "gemini-3.1-flash-lite" # Последняя на март 2026Превышение лимита токенов
Каждая модель имеет максимальную длину контекста. Когда input + max_tokens превышает лимит — ошибка 400:
| Модель | Макс. контекст | Макс. вывод |
|---|---|---|
| GPT-4o | 128K | 16K |
| GPT-5.4 Thinking | 1M | 32K |
| Claude Sonnet 4 | 200K | 64K |
| Gemini 2.5 Flash | 1M | 65K |
| Gemini 3.1 Flash-Lite | 1M | 65K |
Решение: оценивайте количество токенов перед отправкой и при необходимости обрезайте контекст.
500/502/503: серверные ошибки
Серверные ошибки — не ваша проблема, но обрабатывать их нужно корректно.
500 Internal Server Error
Внутренняя ошибка сервера, обычно временная. Стратегия обработки:
import time
def handle_server_error(func, max_retries=3):
"""Повтор при серверной ошибке (без длительного отката — это не ограничение частоты)"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
error_code = getattr(e, 'status_code', 0)
if error_code in (500, 502, 503) and attempt < max_retries - 1:
time.sleep(2 * (attempt + 1)) # Линейный откат
continue
raise502 Bad Gateway
Обычно перегрузка upstream-сервера. Особенно часто случается в пиковые периоды (например, после выпуска новой версии GPT).
503 Service Unavailable
Модель на обслуживании или перегружена. Anthropic Claude при высокой нагрузке возвращает 529 Overloaded (нестандартный код) — обрабатывается аналогично 503.
Полезный совет: следите за страницами статуса платформ:
- OpenAI: status.openai.com
- Anthropic: status.anthropic.com
- Google AI: status.cloud.google.com
408/504: ошибки таймаута — что делать, когда API медленный
Медленные вызовы AI API — одна из главных головных болей разработчиков. Один запрос к GPT-4o в среднем занимает 3-8 секунд, а сложные задачи могут затянуться на 30+ секунд.
Шесть способов оптимизации задержки
1. Включите Streaming (самый эффективный)
Streaming не сокращает общее время генерации, но снижает задержку первого байта (TTFT) до менее 1 секунды:
stream = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Напиши код"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")2. Контролируйте длину вывода
Каждый output-токен добавляет от нескольких до десятков миллисекунд задержки. Явно ограничивайте длину вывода:
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
max_tokens=500, # Ограничение вывода
temperature=0 # Детерминированный вывод, чуть снижает задержку
)3. Используйте лёгкую модель вместо тяжёлой
Не все задачи требуют самой мощной модели:
| Сценарий | Рекомендуемая модель | Средняя задержка |
|---|---|---|
| Простая классификация/извлечение | GPT-4o-mini / Gemini 3.1 Flash-Lite | <1с |
| Генерация кода | Claude Sonnet 4 / GPT-4o | 2-5с |
| Сложные рассуждения | GPT-5.4 Thinking / Claude Opus 4 | 5-15с |
4. Сокращайте промпт
Меньше input-токенов — меньше время обработки. Убирайте избыточные system prompt, заменяйте длинные описания структурированными инструкциями.
5. Параллельные запросы
Если есть несколько независимых AI-задач, не выполняйте их последовательно:
import asyncio
async def parallel_calls(prompts):
tasks = [
aclient.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": p}]
)
for p in prompts
]
return await asyncio.gather(*tasks)6. Ближайшая точка подключения
Сетевая задержка API-запросов особенно заметна в Китае. Прямое подключение к OpenAI имеет RTT 300-500 мс, а через облачные узлы ускорения — 50-100 мс. Узлы Alibaba Cloud / Volcano Cloud Ofox.ai снижают сетевую задержку на 80% и более — особенно заметно для streaming, где каждый chunk экономит 200 мс ожидания.
Лучшие практики для продакшена: обработка ошибок раз и навсегда
Объединим все решения в продакшен-уровень API-клиент:
import time
import random
import logging
from openai import OpenAI
logger = logging.getLogger(__name__)
class RobustAIClient:
"""Продакшен-уровень AI API клиент с встроенной обработкой ошибок"""
def __init__(self, api_key, base_url="https://api.openai.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
def chat(self, messages, model="gpt-4o", max_retries=5, **kwargs):
for attempt in range(max_retries):
try:
return self.client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
except Exception as e:
status = getattr(e, 'status_code', 0)
error_msg = str(e)
# 429 ограничение частоты: экспоненциальный откат
if status == 429 or "429" in error_msg:
wait = min(2 ** attempt + random.uniform(0, 1), 60)
logger.warning(f"Ограничение частоты, ожидание {wait:.1f}с (попытка {attempt+1})")
time.sleep(wait)
continue
# 500/502/503 серверная ошибка: короткий повтор
if status in (500, 502, 503, 529):
wait = 2 * (attempt + 1)
logger.warning(f"Серверная ошибка {status}, ожидание {wait}с")
time.sleep(wait)
continue
# 400/401/403 клиентская ошибка: не повторять
if 400 <= status < 500:
logger.error(f"Клиентская ошибка {status}: {error_msg}")
raise
# Неизвестная ошибка
if attempt == max_retries - 1:
raise
time.sleep(1)
raise Exception(f"Не удалось после {max_retries} попыток")
# Пример использования
client = RobustAIClient(
api_key="your-key",
base_url="https://api.ofox.ai/v1" # Опционально: через шлюз-агрегатор
)
response = client.chat(
messages=[{"role": "user", "content": "Привет"}],
model="gpt-4o"
)Таблица кодов ошибок по платформам
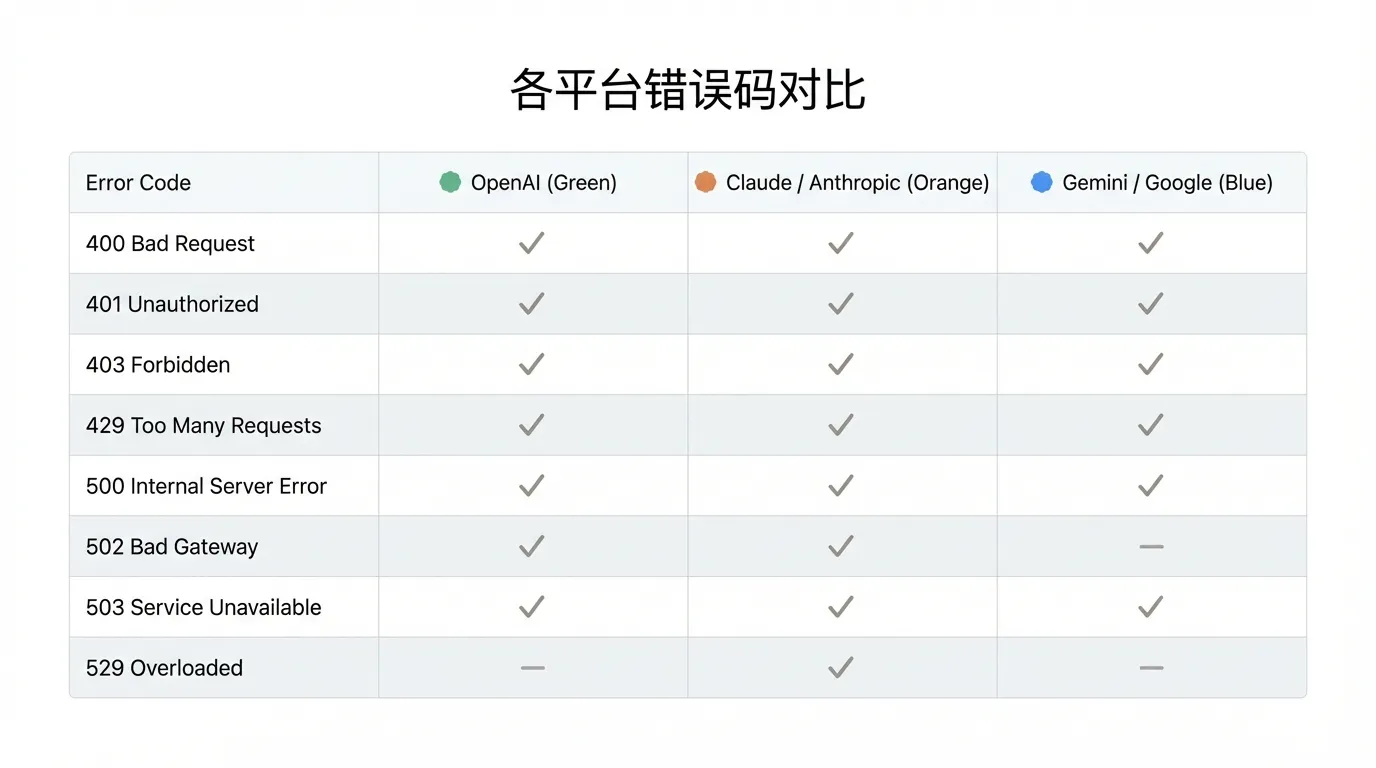
| Код | OpenAI | Claude | Gemini | Значение | Действие |
|---|---|---|---|---|---|
| 400 | Да | Да | Да | Ошибка параметров | Проверить формат запроса |
| 401 | Да | Да | Да | Ошибка аутентификации | Проверить API Key |
| 403 | Да | Да | Да | Нет прав доступа | Проверить права модели/региона |
| 404 | Да | Да | Да | Ресурс не найден | Проверить имя модели/эндпоинт |
| 408 | Да | — | — | Таймаут запроса | Уменьшить токены/включить Stream |
| 429 | Да | Да | Да | Ограничение частоты | Экспоненциальный откат + повышение квоты |
| 500 | Да | Да | Да | Серверная ошибка | Повторить |
| 502 | Да | Да | — | Ошибка шлюза | Повторить |
| 503 | Да | Да | Да | Сервис недоступен | Подождать + повторить |
| 529 | — | Да | — | Перегрузка | Подождать + повторить |
Часто задаваемые вопросы (FAQ)
В: GPT API постоянно выдаёт 429, пополнил баланс — всё равно не работает?
После пополнения нужно подождать автоматического повышения Usage Tier — обычно от нескольких минут до нескольких часов. Проверить текущий Tier можно на странице Limits в панели OpenAI. Если Tier уже повышен, а 429 сохраняется, проверьте, не TPM ли это — длинные промпты легко исчерпывают лимит по токенам.
В: AI API работает слишком медленно — можно ли ускорить без смены модели?
Три способа с мгновенным эффектом: 1) Включить streaming — задержка первого байта с 3-5 секунд падает до менее 1 секунды; 2) Сократить промпт и max_tokens; 3) Использовать ближайший узел ускорения — через облачное ускорение сетевая задержка снижается на 200-400 мс.
В: API Key утёк на GitHub — что делать?
Немедленно удалите ключ в панели управления платформы и сгенерируйте новый. OpenAI и Google имеют автоматическое обнаружение — обнаруженный в публичном репозитории ключ автоматически аннулируется. В будущем используйте переменные окружения и никогда не вписывайте ключи в код.
В: Какая AI API платформа самая выгодная для разработки?
Зависит от объёма и сценария. Если нужно несколько моделей одновременно (GPT для генерации, Claude для анализа, Gemini для мультимодальности), удобнее платформа-агрегатор — один ключ для всех моделей, единая тарификация, автоматический fallback. Например, Ofox.ai поддерживает 50+ моделей с узлами ускорения в Китае.
В: Какую обработку ошибок нужно реализовать в продакшене?
Как минимум: 1) Экспоненциальный откат для всех запросов; 2) Разделение клиентских ошибок (4xx — не повторять) и серверных (5xx — повторять); 3) Разумный таймаут (рекомендуется 30-60 секунд); 4) Логирование ошибок с request ID; 5) Fallback-модель для критических путей.
Итоги и план действий
Ошибки AI API не страшны — страшно отсутствие системного подхода к их обработке. Рекомендуемый порядок действий:
- Сделайте сейчас: добавьте экспоненциальный откат ко всем API-вызовам (30 минут работы)
- Сделайте на этой неделе: реализуйте единую обёртку обработки ошибок (см.
RobustAIClientвыше) - Долгосрочно: настройте мониторинг и оповещения — записывайте задержку, частоту ошибок и расход токенов каждого вызова
Если вы разрабатываете из Китая, настоятельно рекомендуем использовать API-шлюз с узлами ускорения — разница в сетевой задержке колоссальная. Подробнее о подключении: документация для разработчиков Ofox.ai, регистрация с бесплатным балансом.
Рекомендуемые статьи: если вы строите более сложные AI-приложения:
- Function Calling: полное руководство по вызову функций GPT/Claude API
- Как снизить расходы на AI API: 7 стратегий экономии
- Embedding + RAG: руководство по разработке
- Dify: руководство по настройке API