Embedding API: полное руководство по векторизации для RAG-приложений (2026)
Кратко
- Embedding API — ключевой компонент RAG (Retrieval-Augmented Generation), который преобразует текст в векторы для семантического поиска
- Четыре главные модели 2026 года: OpenAI text-embedding-3 (лучшая цена), Cohere Embed v4 (мультимодальная), BGE-M3 (open source, 100+ языков), Qwen3-Embedding (лидер MTEB)
- Российские разработчики могут вызывать все модели через единый RAG совместимый API агрегатор — без VPN и сложной настройки
- В статье — полные примеры кода на Python: от векторизации одного текста до построения полного RAG-пайплайна
Содержание
- Что такое Embedding и почему RAG без него не работает
- Сравнение четырёх Embedding-моделей (2026)
- Python: подключаем Embedding API за 5 минут
- Строим полный RAG-пайплайн
- Оптимизация затрат: экономим 80%
- Типичные ошибки и решения
- Часто задаваемые вопросы (FAQ)
- Итоги и план действий
Что такое Embedding и почему RAG без него не работает
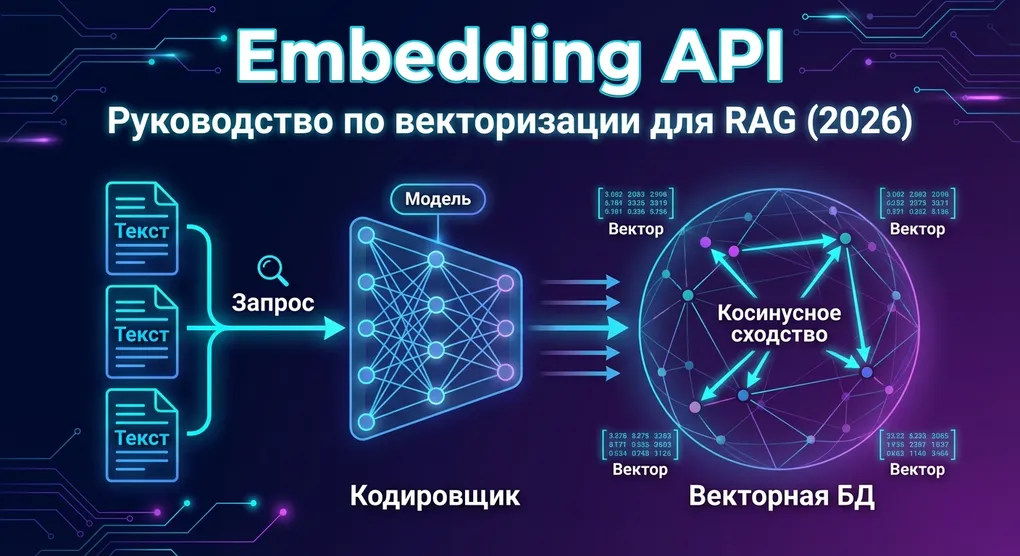
Вы просите GPT ответить на вопрос о внутренней документации компании — он не может, потому что никогда не видел ваших данных. RAG (Retrieval-Augmented Generation) — стандартное решение этой проблемы: сначала из базы знаний извлекаются релевантные фрагменты документов, затем они передаются в промпт, и LLM генерирует ответ на их основе.
Ключ к извлечению — Embedding.
Классический поиск по ключевым словам работает по буквальному совпадению: запрос «как снизить расходы на API» не найдёт документ «стратегии экономии». Embedding отображает текст в многомерное векторное пространство, где семантически близкие тексты находятся рядом:
"как снизить расходы на API" → [0.12, -0.45, ..., 0.89] (1536 измерений)
"стратегии экономии" → [0.11, -0.44, ..., 0.88] (1536 измерений)
Косинусное сходство: 0.95 ✅ Семантическое совпадениеТипичный RAG-пайплайн выглядит так:
Вопрос пользователя → Embedding API (векторизация) → Поиск Top-K в векторной БД → Сборка промпта → LLM генерирует ответEmbedding API — первое звено этой цепочки. Выберете неправильную модель — всё остальное будет впустую.
Сравнение четырёх Embedding-моделей (2026)
| Модель | Разработчик | Размерность | Макс. токенов | MTEB | Цена ($/млн токенов) | Преимущество |
|---|---|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | 8192 | 62.3 | $0.02 | Лучшая цена |
| text-embedding-3-large | OpenAI | 3072 | 8192 | 64.6 | $0.13 | Высокая точность |
| Embed v4 | Cohere | 1536 | 128K | 65.2 | $0.12 | Мультимодальная, сверхдлинный контекст |
| BGE-M3 | BAAI | 1024 | 8192 | 63.0 | Бесплатно (open source) | 100+ языков, гибридный поиск |
| Qwen3-Embedding-8B | Alibaba | 4096 | 32768 | 70.58 | Бесплатно (open source) | №1 в MTEB Multilingual |
OpenAI text-embedding-3: отраслевой стандарт
Третье поколение Embedding-моделей OpenAI, выпущенное в начале 2024 года. До сих пор самый популярный Embedding-сервис по числу API-вызовов. Две версии:
- small: 1536 измерений, $0.02/млн токенов — подходит для 90% RAG-задач
- large: 3072 измерения, $0.13/млн токенов — когда нужна максимальная точность
Поддерживает Matryoshka Embedding (матрёшечное вложение) — можно усечь вектор без значительной потери качества. Например, large-модель с усечением до 1024 измерений по MTEB всё ещё превосходит small с 1536 — при этом затраты на хранение снижаются на 66%.
Cohere Embed v4: мультимодальный лидер
Embed v4, выпущенный в 2025 году, — первая по-настоящему практичная мультимодальная Embedding-модель:
- Текст + изображения в одном запросе: одновременная обработка текста документа и иллюстраций
- 128K сверхдлинный контекст: обработка целых статей, договоров и научных работ без разбиения на чанки
- Несколько форматов квантизации: float, int8, binary — сжатие хранилища до 32 раз
Подходит для корпоративных задач: анализ документов, мультимодальный поиск. Но стоит в 6 раз дороже OpenAI small.
BGE-M3: универсальный open source
Модель от Пекинской академии искусственного интеллекта (BAAI). Три буквы M в названии:
- Multi-Lingual: 100+ языков, включая русский
- Multi-Granularity: от коротких фраз до текстов в 8192 токена
- Multi-Functionality: одновременная поддержка плотного, разреженного и мультивекторного поиска
Одна модель — три режима поиска. Гибридное использование обычно даёт лучшие результаты, чем каждый по отдельности. Можно развернуть локально — нулевые затраты на API.
Qwen3-Embedding: лидер мультиязычных бенчмарков
Qwen3-Embedding-8B от Alibaba занимает первое место в рейтинге MTEB Multilingual с результатом 70.58. Отличные показатели на мультиязычных данных, включая русский и кириллицу.
- 4096-мерный вектор, контекстное окно 32K
- Open source, можно развернуть локально или использовать через DashScope API
- 8B параметров — требуется GPU для инференса
Если ваше RAG-приложение работает с мультиязычным контентом или вам нужна максимальная точность — Qwen3-Embedding на сегодня лучший выбор.
Как выбрать? Дерево решений
Какой у вас сценарий?
├── Мультиязычный RAG (рус/англ/кит) → Qwen3-Embedding (максимальная точность)
├── Многоязычный / кроссязычной поиск → BGE-M3 (100+ языков)
├── Поиск по тексту + изображениям → Cohere Embed v4 (мультимодальная)
├── Быстрый прототип / ограниченный бюджет → text-embedding-3-small (самая дешёвая)
└── Высокая точность + удобство API → text-embedding-3-large (оптимальный баланс)Python: подключаем Embedding API за 5 минут
Вариант 1: Прямой вызов OpenAI Embedding API
from openai import OpenAI
# Для российских разработчиков: вызов через API-агрегатор,
# не нужен VPN или дополнительная настройка
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1" # OpenAI-совместимый интерфейс
)
# Векторизация одного текста
response = client.embeddings.create(
model="text-embedding-3-small",
input="Как создать RAG-приложение на Python?"
)
embedding = response.data[0].embedding
print(f"Размерность: {len(embedding)}") # 1536
print(f"Первые 5 значений: {embedding[:5]}")Вариант 2: Пакетная векторизация
В реальных проектах нужно обрабатывать большие объёмы документов:
import time
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
def batch_embed(texts: list[str], model="text-embedding-3-small", batch_size=100):
"""Пакетная векторизация с автоматическим разбиением на батчи"""
all_embeddings = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
response = client.embeddings.create(model=model, input=batch)
# Сортировка по исходному порядку (API может вернуть в другом)
batch_embeddings = [None] * len(batch)
for item in response.data:
batch_embeddings[item.index] = item.embedding
all_embeddings.extend(batch_embeddings)
# Пауза для соблюдения rate limit
if i + batch_size < len(texts):
time.sleep(0.1)
return all_embeddings
# Пример использования
documents = [
"Python — универсальный язык программирования",
"RAG повышает качество ответов LLM за счёт извлечения документов",
"Векторная база данных хранит и ищет многомерные векторы",
# ... больше документов
]
embeddings = batch_embed(documents)
print(f"Обработано {len(embeddings)} документов, каждый {len(embeddings[0])} измерений")Вариант 3: Вычисление семантического сходства
import numpy as np
def cosine_similarity(a, b):
"""Вычисление косинусного сходства двух векторов"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Векторизация трёх текстов
texts = [
"Как снизить расходы на AI API?",
"Стратегии экономии на вызовах нейросетей",
"Какая погода сегодня в Москве?"
]
response = client.embeddings.create(
model="text-embedding-3-small",
input=texts
)
emb = [item.embedding for item in response.data]
print(f"Семантически близкие: {cosine_similarity(emb[0], emb[1]):.4f}") # ~0.85
print(f"Семантически далёкие: {cosine_similarity(emb[0], emb[2]):.4f}") # ~0.15Строим полный RAG-пайплайн
Ниже — рабочий RAG-пайплайн в 100 строках кода. Без внешних векторных БД, чистый Python:
import json
import numpy as np
from openai import OpenAI
from pathlib import Path
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
class SimpleRAG:
def __init__(self, embedding_model="text-embedding-3-small"):
self.model = embedding_model
self.documents = [] # Исходные документы
self.embeddings = [] # Соответствующие векторы
def add_documents(self, docs: list[str]):
"""Добавление документов в базу знаний"""
response = client.embeddings.create(model=self.model, input=docs)
for i, item in enumerate(response.data):
self.documents.append(docs[item.index])
self.embeddings.append(item.embedding)
print(f"Проиндексировано {len(docs)} документов, всего {len(self.documents)}")
def search(self, query: str, top_k=3) -> list[dict]:
"""Семантический поиск Top-K релевантных документов"""
q_resp = client.embeddings.create(model=self.model, input=[query])
q_emb = np.array(q_resp.data[0].embedding)
# Вычисление косинусного сходства
doc_embs = np.array(self.embeddings)
similarities = np.dot(doc_embs, q_emb) / (
np.linalg.norm(doc_embs, axis=1) * np.linalg.norm(q_emb)
)
# Top-K
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [
{"text": self.documents[i], "score": float(similarities[i])}
for i in top_indices
]
def ask(self, question: str, top_k=3) -> str:
"""RAG-ответ: извлечение + генерация"""
# Шаг 1: Поиск релевантных документов
results = self.search(question, top_k=top_k)
context = "\n\n".join(
f"[Документ {i+1}] (релевантность: {r['score']:.2f})\n{r['text']}"
for i, r in enumerate(results)
)
# Шаг 2: Формирование промпта для LLM
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4-6", # Или другая модель
messages=[
{"role": "system", "content": "Отвечай на вопрос пользователя на основе предоставленных документов. Если в документах нет нужной информации, честно скажи об этом."},
{"role": "user", "content": f"Документы:\n{context}\n\nВопрос: {question}"}
]
)
return response.choices[0].message.content
# Пример использования
rag = SimpleRAG()
# Загрузка базы знаний
rag.add_documents([
"Ofox поддерживает 100+ AI-моделей: GPT, Claude, Gemini, DeepSeek и другие — через единый OpenAI-совместимый интерфейс.",
"text-embedding-3-small стоит $0.02/млн токенов — самая выгодная Embedding-модель на рынке.",
"Качество извлечения в RAG напрямую определяет качество финального ответа. Выбор Embedding-модели критически важен.",
"BGE-M3 поддерживает плотный, разреженный и мультивекторный поиск — гибридное использование даёт лучший результат.",
"Batch API снижает стоимость Embedding на 50%. Подходит для офлайн-обработки больших объёмов.",
])
# Семантический поиск
results = rag.search("Какая Embedding-модель самая дешёвая?")
for r in results:
print(f"[{r['score']:.2f}] {r['text'][:60]}...")
# RAG-ответ
answer = rag.ask("Как снизить затраты на Embedding?")
print(answer)Эта минимальная реализация использует numpy для векторного поиска. Подходит для объёмов до 100 000 документов. При большем масштабе подключайте полноценную векторную базу данных (Milvus, Qdrant, Pinecone и др.).
Оптимизация затрат: экономим 80%
Embedding API и так стоит копейки, но при больших объёмах затраты растут. Вот проверенные стратегии оптимизации:
1. Выбирайте правильную модель — не берите large сразу
| Сценарий | Рекомендуемая модель | Стоимость |
|---|---|---|
| Прототип / MVP | text-embedding-3-small | $0.02/M |
| Продакшн (английский) | text-embedding-3-large | $0.13/M |
| Продакшн (русский / мультиязычный) | BGE-M3 или Qwen3-Embedding (self-hosted) | Только GPU |
| Мультимодальный поиск | Cohere Embed v4 | $0.12/M |
Для большинства RAG-задач small-модели достаточно. Начните с small, соберите метрики — переходите на large только если данные покажут нехватку точности.
2. Batch API — скидка 50%
OpenAI Batch API позволяет обрабатывать запросы асинхронно по половинной цене:
# Пример Batch API (асинхронная обработка, результат в течение 24 часов)
batch_input = {
"custom_id": "doc-001",
"method": "POST",
"url": "/v1/embeddings",
"body": {
"model": "text-embedding-3-small",
"input": "Ваш текст для векторизации"
}
}Идеально для инициализации базы знаний, периодической полной переиндексации и других задач, не требующих мгновенного ответа.
3. Предобработка текста — меньше токенов
import re
def preprocess_for_embedding(text: str) -> str:
"""Очистка текста для уменьшения числа токенов"""
# Убираем лишние пробелы
text = re.sub(r'\s+', ' ', text).strip()
# Убираем HTML-теги
text = re.sub(r'<[^>]+>', '', text)
# Убираем повторяющуюся пунктуацию
text = re.sub(r'[.!?,;]{2,}', '.', text)
return textНа практике очистка снижает число токенов на 15–25% — прямая экономия.
4. Кэширование результатов
Не вызывайте API повторно для одного и того же текста:
import hashlib
import json
from pathlib import Path
class EmbeddingCache:
def __init__(self, cache_dir="./embedding_cache"):
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(exist_ok=True)
def _key(self, text: str, model: str) -> str:
return hashlib.md5(f"{model}:{text}".encode()).hexdigest()
def get(self, text: str, model: str):
path = self.cache_dir / f"{self._key(text, model)}.json"
if path.exists():
return json.loads(path.read_text())
return None
def set(self, text: str, model: str, embedding: list):
path = self.cache_dir / f"{self._key(text, model)}.json"
path.write_text(json.dumps(embedding))5. Matryoshka — снижение размерности
Модели text-embedding-3 поддерживают усечение вектора. Значительная экономия на хранилище и скорости поиска:
response = client.embeddings.create(
model="text-embedding-3-large",
input="Ваш текст",
dimensions=1024 # Вместо 3072 — экономия 66% хранилища
)| Размерность | Хранилище (1 запись) | MTEB | Экономия |
|---|---|---|---|
| 3072 (по умолчанию) | 12 КБ | 64.6 | — |
| 1024 | 4 КБ | 63.8 | 66% |
| 512 | 2 КБ | 62.5 | 83% |
| 256 | 1 КБ | 60.1 | 92% |
Типичные ошибки и решения
Ошибка 1: Смешивание векторов от разных моделей
# ❌ Неправильно: индекс на small, поиск на large
index_emb = embed("документ", model="text-embedding-3-small") # 1536 измерений
query_emb = embed("запрос", model="text-embedding-3-large") # 3072 измерений
# Разные размерности — вычислить сходство невозможно!Решение: индексация и поиск — всегда одна и та же модель. Смена модели = полная повторная векторизация.
Ошибка 2: Тихое обрезание длинных текстов
Embedding API имеет лимит токенов (у text-embedding-3 — 8192). Текст сверх лимита обрезается без предупреждения — информация теряется, ошибки нет.
import tiktoken
def safe_embed(text: str, model="text-embedding-3-small", max_tokens=8000):
"""Безопасная векторизация с автоматическим разбиением длинных текстов"""
enc = tiktoken.encoding_for_model(model)
tokens = enc.encode(text)
if len(tokens) <= max_tokens:
return embed(text, model)
# Разбиение на чанки
chunks = []
for i in range(0, len(tokens), max_tokens):
chunk_text = enc.decode(tokens[i:i + max_tokens])
chunks.append(chunk_text)
# Усреднение векторов чанков (простой вариант)
embeddings = [embed(c, model) for c in chunks]
return np.mean(embeddings, axis=0).tolist()Ошибка 3: Rate limit (429)
При высокой нагрузке легко превысить лимит запросов:
from tenacity import retry, wait_exponential, stop_after_attempt
@retry(wait=wait_exponential(min=1, max=60), stop=stop_after_attempt(5))
def embed_with_retry(text, model="text-embedding-3-small"):
return client.embeddings.create(model=model, input=text)Через API-агрегатор можно получить более высокие лимиты запросов. В документации Ofox указаны конкретные лимиты для каждой модели.
Ошибка 4: Стратегия разбиения для русского текста
Для английского хорошо работает разбиение по предложениям, но в русском тексте границы предложений не всегда очевидны. Рекомендуется разбиение по абзацам + скользящее окно:
def russian_chunk(text: str, chunk_size=500, overlap=50):
"""Разбиение русского текста на чанки с перекрытием"""
paragraphs = text.split('\n')
chunks = []
current = ""
for para in paragraphs:
if len(current) + len(para) > chunk_size:
if current:
chunks.append(current.strip())
# Хвост текущего чанка — начало следующего
current = current[-overlap:] + para
else:
chunks.append(para[:chunk_size])
current = para[chunk_size - overlap:]
else:
current += "\n" + para
if current.strip():
chunks.append(current.strip())
return chunksЧасто задаваемые вопросы (FAQ)
В: Что такое Embedding API и чем он отличается от Chat API?
Embedding API преобразует текст в многомерные векторы (например, массив из 1536 чисел с плавающей запятой), которые используются для семантического поиска, вычисления сходства и RAG-извлечения. Chat API генерирует текстовые ответы, а Embedding API — числовые векторы. Они работают в связке: сначала Embedding находит релевантные документы, затем Chat-модель формирует ответ.
В: Как российским разработчикам вызвать Embedding API OpenAI?
OpenAI API напрямую из России недоступен. Рекомендуем использовать OpenAI-совместимую API-платформу (например, Ofox) — достаточно изменить base_url и использовать стандартный OpenAI SDK для вызова text-embedding-3-small/large. Оплата рублями или криптовалютой, без международной карты.
В: Какую Embedding-модель выбрать для RAG-приложения?
Зависит от задачи: для русскоязычного и мультиязычного контента — BGE-M3 (100+ языков) или Qwen3-Embedding (лидер MTEB), для лучшего соотношения цена/качество — text-embedding-3-small ($0.02/млн токенов), для мультимодальных корпоративных задач — Cohere Embed v4. Обязательно проведите A/B-тест на своих данных.
В: Чем больше размерность вектора, тем лучше?
Не обязательно. У text-embedding-3-large 3072 измерения — на бенчмарках он лучше small (1536), но в реальных RAG-сценариях разница обычно 1–3%. Более высокая размерность — это больше хранилища и медленнее поиск. Начните с small, переходите на large только при доказанной нехватке точности.
В: Сколько стоит вызов Embedding API?
Embedding — самый дешёвый тип AI API. text-embedding-3-small стоит всего $0.02/млн токенов. Векторизация 1 млн символов русского текста обойдётся менее чем в $0.1. Через Batch API можно сэкономить ещё 50%.
В: Нужно ли заново векторизовать все данные при смене модели?
Да. Разные модели генерируют векторы разной размерности и в разных семантических пространствах — их нельзя смешивать. Смена модели = полная повторная векторизация. Поэтому выбирайте модель тщательно. Протестируйте на небольшой выборке перед массовым развёртыванием.
Итоги и план действий
В 2026 году экосистема Embedding-моделей полностью зрелая. Рекомендуемый план действий для разработчиков:
- Быстрый старт:
text-embedding-3-small+ numpy — рабочий RAG-прототип за 10 минут - Оценка точности: сравните 2–3 модели на ваших реальных данных, измерьте качество извлечения
- Оптимизация затрат: подключите кэширование, используйте Batch API, делайте предобработку текста
- Масштабирование: при объёме >100 000 документов переходите на векторную БД (Milvus / Qdrant)
Российские разработчики могут через Ofox вызывать все перечисленные Embedding-модели через единый OpenAI-совместимый RAG совместимый API — один ключ, доступ из России, оплата рублями или криптовалютой. Без VPN, без международных карт.