Мультимодальные AI API: полное руководство по Vision, TTS и Whisper (2026)
Кратко
В 2026 году мультимодальный AI перешёл из стадии концепта в стандарт продакшна — 60% корпоративных приложений уже используют два и более типа данных. Эта статья пошагово показывает, как через OpenAI-совместимый протокол одним кодом подключить три ключевые возможности: распознавание изображений Vision, синтез речи TTS, транскрибацию Whisper — на базе GPT-4o, Claude 3.5 Sonnet, Gemini 2.0. Без управления тремя SDK — один API Key решает всё.
Содержание
- Зачем вам мультимодальные API
- Vision API: AI видит изображения
- TTS API: синтез речи на практике
- Whisper API: лучшие практики распознавания речи
- Единое подключение: один API Key для всех модальностей
- Сравнение стоимости и рекомендации по выбору
- Архитектура для продакшна: мультимодальный Pipeline
- Часто задаваемые вопросы (FAQ)
- Итоги и план действий
- Полезные ссылки
Зачем вам мультимодальные API
Если вы до сих пор используете только текстовый API для AI-приложений, в 2026 году вы уже отстаёте.
По данным Mordor Intelligence, рынок мультимодального AI в 2026 году достиг 3,85 млрд долларов при среднегодовом темпе роста 28,59%. Ключевая цифра: около 60% корпоративных приложений уже используют два и более типа данных (текст + изображения, текст + голос и т.д.).
Что это означает? Ваши конкуренты, скорее всего, уже делают следующее:
- Служба поддержки: пользователь присылает скриншот, AI сразу анализирует проблему (Vision API)
- Контентные платформы: автоматическая озвучка статей (TTS API)
- Инструменты для совещаний: транскрибация в реальном времени с автоматическим формированием протокола (Whisper API)
- E-commerce: поиск товаров по фото, голосовые заказы, модерация изображений — всё в одном потоке
Проблема в том, что порог входа для подключения этих возможностей высок. Нужно управлять OpenAI Vision, отдельно разворачивать Whisper, подключать TTS от ElevenLabs… Для каждой модальности — свой SDK, своя авторизация, своя тарификация.
Есть ли решение проще? Есть. Читайте дальше.
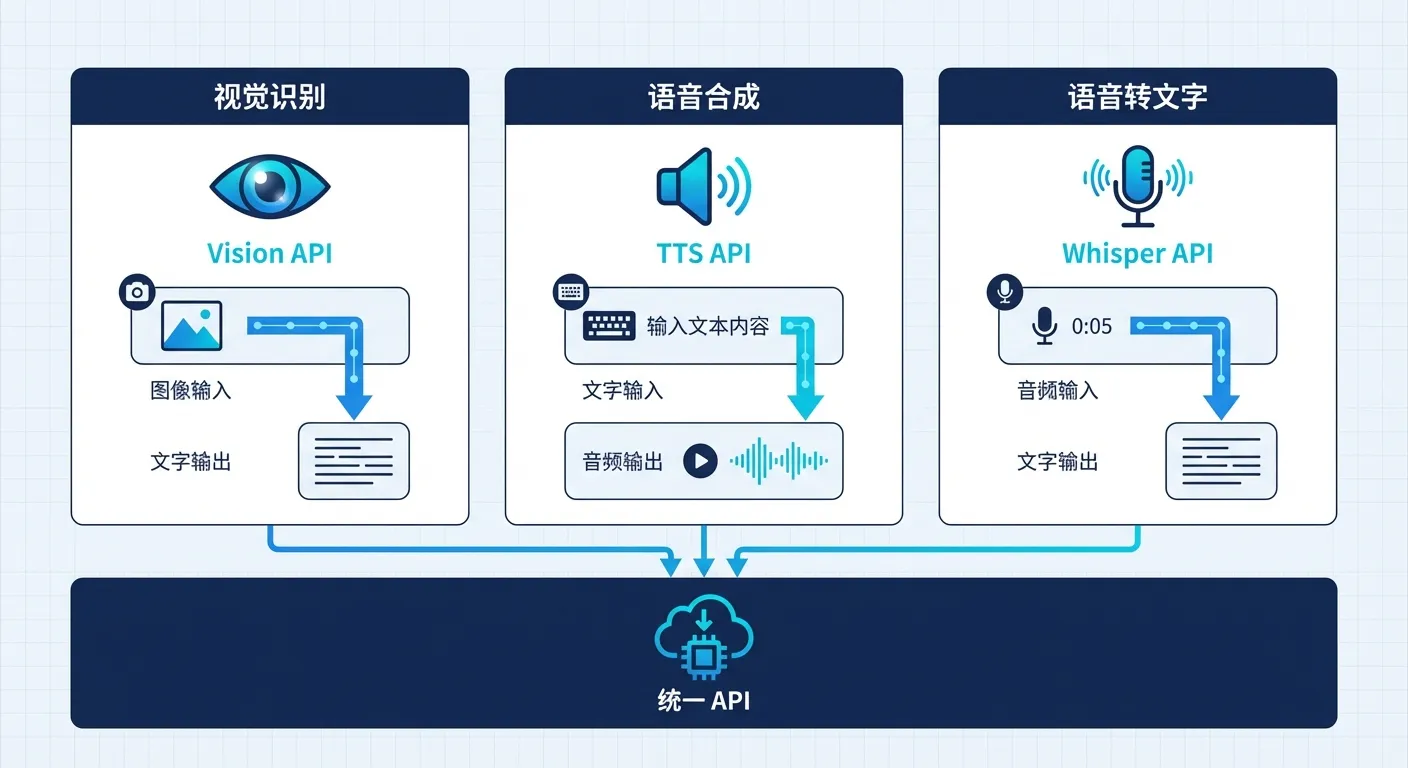
Vision API: AI видит изображения
Vision API — самая зрелая и широко применяемая мультимодальная возможность. В 2026 году все основные модели нативно поддерживают ввод изображений.
Базовый вызов: передача изображения одной строкой
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1" # Совместим с протоколом OpenAI
)
response = client.chat.completions.create(
model="gpt-4o", # Можно заменить на claude-3.5-sonnet, gemini-2.0-flash
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Что изображено на этой картинке? Опишите подробно."},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/photo.jpg"
}
}
]
}
],
max_tokens=1000
)
print(response.choices[0].message.content)Передача локального изображения (Base64)
В реальных проектах чаще работают с загруженными пользователем файлами:
import base64
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_data = encode_image("screenshot.png")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Проанализируйте сообщение об ошибке на скриншоте и предложите решение."},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_data}"
}
}
]
}
]
)Практические сценарии Vision API
| Сценарий | Рекомендуемая модель | Описание |
|---|---|---|
| Общее понимание изображений | GPT-4o | Лучшие универсальные способности, поддержка сложных рассуждений |
| OCR документов | Gemini 2.0 Flash | Быстрая обработка длинных документов, низкая стоимость |
| Анализ UI-скриншотов | Claude 3.5 Sonnet | Точное распознавание элементов интерфейса |
| Первичный скрининг медицинских изображений | GPT-4o | Требуется специализированный промпт и проверка специалистом |
| Распознавание товаров в e-commerce | Gemini 2.0 Flash | Оптимальное соотношение цена/качество |
Ключевые параметры и замечания
- Размер изображения: OpenAI ограничивает до 20 МБ, рекомендуется сжимать до 1 МБ для снижения задержки
- Разрешение: режим
detail: "high"потребляет больше токенов — выбирайте по потребности - Мульти-ввод: GPT-4o поддерживает несколько изображений за один запрос — удобно для сравнительного анализа
- Расчёт токенов: токены за изображение зависят от разрешения — одно изображение 1024x1024 потребляет ~765 токенов
TTS API: синтез речи на практике
TTS (Text-to-Speech) — самая быстрорастущая мультимодальная область. В конце 2025 года OpenAI выпустила модель gpt-4o-mini-tts с управлением тональностью, эмоциями и стилем речи через промпт — результат намного лучше традиционных TTS-решений.
Базовый вызов: текст в аудиофайл
from openai import OpenAI
from pathlib import Path
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
# Базовый TTS: текст в речь
response = client.audio.speech.create(
model="tts-1", # tts-1 — быстрый, tts-1-hd — высокое качество
voice="alloy", # Варианты: alloy, echo, fable, onyx, nova, shimmer
input="Здравствуйте! Добро пожаловать в наш AI-ассистент. Чем могу помочь?"
)
# Сохранение в MP3
speech_file = Path("output.mp3")
response.stream_to_file(speech_file)
print(f"Аудио сохранено в {speech_file}")Продвинутое использование: управление тональностью и эмоциями
Ключевая особенность gpt-4o-mini-tts — программируемое управление тональностью:
# Управление стилем речи через instructions
response = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="coral",
input="Ваш заказ отправлен, ожидается доставка завтра.",
instructions="Говори тёплым, дружелюбным тоном, как приветливый оператор поддержки."
)Это намного удобнее SSML-разметки в традиционном TTS — не нужно писать XML, достаточно описать на естественном языке.
Сравнение моделей TTS
| Модель | Задержка | Качество | Управление тональностью | Цена (за млн символов) |
|---|---|---|---|---|
| tts-1 | ~300 мс | Хорошее | 6 предустановок | $15 |
| tts-1-hd | ~800 мс | Отличное | 6 предустановок | $30 |
| gpt-4o-mini-tts | ~400 мс | Отличное | Инструкции на естественном языке | $12 |
| ElevenLabs Turbo v2.5 | ~200 мс | Отличное | Клонирование голоса | $30+ |
Потоковое воспроизведение в реальном времени
Для диалоговых сценариев — потоковый вывод без ожидания полного аудио:
import pyaudio
# Потоковый TTS
with client.audio.speech.with_streaming_response.create(
model="tts-1",
voice="alloy",
input="Это речь, генерируемая в реальном времени — можно воспроизводить по мере генерации.",
response_format="pcm"
) as response:
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=24000, output=True)
for chunk in response.iter_bytes(1024):
stream.write(chunk)
stream.stop_stream()
stream.close()
p.terminate()Whisper API: лучшие практики распознавания речи
Транскрибация голоса — одна из мультимодальных возможностей с наивысшим ROI. Новейшая модель OpenAI gpt-4o-mini-transcribe по сравнению с Whisper v2 сокращает галлюцинации на 90% (при тишине больше не генерирует случайный текст), а также значительно снижает частоту ошибок.
Базовая транскрибация
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
# Открываем аудиофайл для транскрибации
with open("meeting_recording.mp3", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
language="ru", # Указание языка повышает точность
response_format="verbose_json", # Получаем таймстампы
timestamp_granularities=["segment"]
)
# Вывод результата с таймстампами
for segment in transcript.segments:
start = f"{int(segment.start // 60)}:{int(segment.start % 60):02d}"
print(f"[{start}] {segment.text}")Сравнение моделей транскрибации нового поколения
| Модель | Частота ошибок | Галлюцинации | Поддержка языков | Цена (за минуту) |
|---|---|---|---|---|
| whisper-1 | Базовая | Базовая | 57 языков | $0.006 |
| gpt-4o-transcribe | -15% | -80% | 57 языков | $0.01 |
| gpt-4o-mini-transcribe | -12% | -90% | 57 языков | $0.005 |
gpt-4o-mini-transcribe — лучший выбор по соотношению цена/качество: точнее и дешевле whisper-1, галлюцинации сокращены на 90%.
Лучшие практики обработки аудио
from pydub import AudioSegment
import io
def transcribe_long_audio(file_path: str, client: OpenAI) -> str:
"""Обработка длинного аудио: разбивка на сегменты и объединение"""
audio = AudioSegment.from_file(file_path)
# Whisper API ограничивает 25 МБ — разбиваем по 10 минут
chunk_length_ms = 10 * 60 * 1000
chunks = [audio[i:i + chunk_length_ms]
for i in range(0, len(audio), chunk_length_ms)]
full_transcript = []
for i, chunk in enumerate(chunks):
# Экспорт в MP3 и транскрибация
buffer = io.BytesIO()
chunk.export(buffer, format="mp3")
buffer.name = f"chunk_{i}.mp3"
buffer.seek(0)
result = client.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=buffer,
language="ru"
)
full_transcript.append(result.text)
return "\n".join(full_transcript)Перевод голоса: всё за один шаг
Whisper API также поддерживает прямой перевод иностранного аудио в английский текст:
# Японское аудио → английский текст
with open("japanese_podcast.mp3", "rb") as audio_file:
translation = client.audio.translations.create(
model="whisper-1",
file=audio_file
)
print(translation.text) # Вывод на английскомЕдиное подключение: один API Key для всех модальностей
К этому моменту вы, вероятно, заметили проблему: Vision использует GPT-4o, TTS — gpt-4o-mini-tts, транскрибация — gpt-4o-mini-transcribe… Столько моделей — неужели нужно регистрироваться на трёх платформах?
Нет. Через API-шлюз, совместимый с протоколом OpenAI, один API Key даёт доступ ко всем моделям и всем модальностям.
Сравнение архитектур
Традиционный подход:
Ваше приложение
├── OpenAI SDK → OpenAI API (Vision + TTS + Whisper)
├── Anthropic SDK → Claude API (Vision)
├── Google SDK → Gemini API (Vision + TTS)
└── ElevenLabs SDK → ElevenLabs API (TTS)4 SDK, 4 API Key, 4 системы тарификации, 4 варианта обработки ошибок.
Агрегированный шлюз (на примере Ofox):
Ваше приложение
└── OpenAI SDK → Ofox API Gateway → 50+ моделей (все модальности)1 SDK, 1 API Key, единая тарификация, единая обработка ошибок.
Код: подключение без изменений
Если вы уже используете OpenAI SDK, достаточно изменить две строки:
from openai import OpenAI
# Меняются только эти две строки
client = OpenAI(
api_key="sk-ofox-your-key", # API Key Ofox
base_url="https://api.ofox.ai/v1" # Адрес агрегированного шлюза
)
# Весь остальной код — без изменений ↓
# Vision: анализ изображения через Claude
response = client.chat.completions.create(
model="claude-3.5-sonnet", # Смена модели — одна строка
messages=[{"role": "user", "content": [
{"type": "text", "text": "Опишите это изображение"},
{"type": "image_url", "image_url": {"url": "https://..."}}
]}]
)
# TTS: синтез речи через OpenAI
speech = client.audio.speech.create(
model="tts-1", voice="nova",
input="Тест синтеза речи"
)
# Whisper: распознавание речи
with open("audio.mp3", "rb") as f:
transcript = client.audio.transcriptions.create(
model="whisper-1", file=f
)Преимущества этого подхода:
- Нулевая стоимость смены модели — сравниваете Vision GPT-4o и Claude? Меняете один параметр model
- Единая обработка ошибок — не нужно писать 4 блока try/catch
- Контроль затрат — оплата по факту использования, без минимальных порогов на каждой платформе
- Низкая задержка из Китая — агрегированный шлюз обычно имеет узлы ускорения в Китае
Сравнение стоимости и рекомендации по выбору
Быстрый расчёт стоимости по модальностям
| Модальность | Модель | Цена | Типичный объём/мес. | Стоимость/мес. |
|---|---|---|---|---|
| Vision | GPT-4o | ~$2.5/млн токенов | 500 тыс. распознаваний | ~$125 |
| Vision | Gemini 2.0 Flash | ~$0.1/млн токенов | 500 тыс. распознаваний | ~$5 |
| TTS | tts-1 | $15/млн символов | 1 млн символов | $15 |
| TTS | gpt-4o-mini-tts | $12/млн символов | 1 млн символов | $12 |
| Транскрибация | whisper-1 | $0.006/мин | 1000 минут | $6 |
| Транскрибация | gpt-4o-mini-transcribe | $0.005/мин | 1000 минут | $5 |
Дерево решений по выбору
Нужно распознавание изображений?
├── Сложные рассуждения (математика, скриншоты кода) → GPT-4o
├── Массовый OCR документов → Gemini 2.0 Flash (дешевле в 25 раз)
└── Анализ UI/макетов → Claude 3.5 Sonnet
Нужен синтез речи?
├── Диалоги (низкая задержка) → tts-1
├── Контент (высокое качество) → tts-1-hd
└── Управление тональностью → gpt-4o-mini-tts
Нужна транскрибация?
├── Ограниченный бюджет → gpt-4o-mini-transcribe (самый дешёвый + минимум галлюцинаций)
├── Максимальная точность → gpt-4o-transcribe
└── Простые сценарии → whisper-1Архитектура для продакшна: мультимодальный Pipeline
На примере типичной «интеллектуальной системы поддержки клиентов» — как комбинировать мультимодальные возможности:
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="sk-ofox-your-key",
base_url="https://api.ofox.ai/v1"
)
async def handle_customer_message(message_type: str, content) -> dict:
"""Универсальная обработка сообщений клиента: текст, изображение, голос"""
if message_type == "voice":
# Шаг 1: распознавание речи
transcript = await client.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=content
)
user_text = transcript.text
elif message_type == "image":
# Шаг 1: анализ изображения
vision_response = await client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": [
{"type": "text", "text": "Пользователь прислал это изображение. Определите проблему или запрос."},
{"type": "image_url", "image_url": {"url": content}}
]}]
)
user_text = vision_response.choices[0].message.content
else:
user_text = content
# Шаг 2: AI генерирует ответ
reply = await client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Ты интеллектуальный оператор поддержки. Отвечай кратко и профессионально."},
{"role": "user", "content": user_text}
]
)
reply_text = reply.choices[0].message.content
# Шаг 3: генерация голосового ответа (опционально)
speech = await client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="nova",
input=reply_text,
instructions="Говори тёплым, дружелюбным тоном оператора поддержки."
)
return {
"text": reply_text,
"audio": speech.content,
"original_input": user_text
}Ключевые принципы архитектуры
- Асинхронные вызовы: мультимодальная обработка занимает больше времени —
AsyncOpenAIпредотвращает блокировку - Маршрутизация по модальности: автоматический выбор цепочки обработки по типу ввода
- Деградация при ошибках: при сбое Vision — предложить пользователю описать проблему текстом; при сбое TTS — вернуть только текст
- Кэширование: результаты распознавания одного изображения кэшируются на 5 минут — без повторных вызовов
Часто задаваемые вопросы (FAQ)
В: Какие форматы изображений поддерживает Vision API?
О: Все основные форматы — PNG, JPEG, GIF, WebP. GPT-4o также поддерживает статичные GIF. Рекомендуется JPEG — высокая степень сжатия и быстрая передача. Можно передавать изображения через Base64 или URL; URL-способ быстрее (сервер API загружает изображение напрямую).
В: Вызов TTS API слишком медленный — что делать?
О: Три направления оптимизации. Первое: используйте tts-1 вместо tts-1-hd — задержка снижается с 800 мс до 300 мс. Второе: потоковый вывод (streaming) — воспроизведение по мере генерации, воспринимаемая задержка стремится к нулю. Третье: выбирайте API-шлюз с узлами ускорения в Китае (например, облачные узлы Ofox) — сетевая задержка снижается с 300+ мс до менее 50 мс.
В: Есть ли ограничения по размеру для Whisper?
О: Да, максимум 25 МБ на один запрос. Для более длинных записей используйте сегментацию — библиотека pydub позволяет разбить на фрагменты по 10 минут, транскрибировать по отдельности и объединить. Функция transcribe_long_audio выше — готовое решение.
В: Какой API лучше для AI-продукта?
О: Зависит от сложности задачи. Если используете одну модель для одной модальности — проще вызывать официальный API напрямую. Но если продукт включает несколько модальностей (распознавание изображений + диалог + голос) или требуется сравнение моделей — агрегированный шлюз удобнее: один SDK для всех моделей и модальностей, оплата по факту.
В: Vision — выбрать Claude или GPT?
О: У каждого свои сильные стороны. GPT-4o лучше в сложных рассуждениях и распознавании математических задач; Claude 3.5 Sonnet точнее в понимании UI- и код-скриншотов. В реальном проекте рекомендуется протестировать обе модели на одном изображении. При использовании агрегированного шлюза смена модели — один параметр, стоимость тестирования практически нулевая.
В: Какие подводные камни есть у AI API?
О: Несколько типичных: 1) Слишком большое изображение — таймаут. Сжимайте до 1 МБ. 2) Неточное произношение китайского в TTS — укажите параметр language. 3) Галлюцинации Whisper на тишине — обновитесь до gpt-4o-mini-transcribe, галлюцинации снижены на 90%. 4) Разные коды ошибок на разных платформах — агрегированный шлюз унифицирует обработку ошибок.
Итоги и план действий
В 2026 году мультимодальные AI API достаточно зрелы для использования в продакшне. Ключевые выводы:
- Vision API — самая зрелая модальность: GPT-4o лучший по универсальности, Gemini 2.0 Flash — по соотношению цена/качество
- TTS API — выбирайте
gpt-4o-mini-tts: управление тональностью на естественном языке и самая низкая цена - Транскрибация Whisper — выбирайте
gpt-4o-mini-transcribe: минимум галлюцинаций, лучшее соотношение цена/качество - Единое подключение: агрегированный шлюз с протоколом OpenAI — один Key для всех моделей и всех модальностей
Следующие шаги:
- Перейдите в документацию Ofox для разработчиков и получите API Key (бесплатный баланс при регистрации)
- Запустите три демо по примерам из этой статьи: Vision + TTS + Whisper
- Используйте «дерево решений» для выбора оптимальной комбинации моделей под ваш бизнес
- Постройте продакшн-уровень мультимодального Pipeline на асинхронном + потоковом подходе