AI Agent 开发完全指南:用 Python 从零构建智能体(2026)
摘要
- AI Agent 的核心能力是 Function Calling(工具调用)——让大模型不只会说,还会做
- 本文从零实现一个完整的 AI Agent:天气查询 + 数据库检索 + 代码执行,附可直接运行的 Python 代码
- 覆盖 OpenAI、Claude、Gemini 三大模型的 Tool Use 实现方式,代码可直接复用
- 生产环境要点:错误处理、多轮工具调用、并行调用、安全防护,一次讲透
目录
- 什么是 AI Agent?从 ChatBot 到智能体的进化
- 核心原理:Function Calling 如何工作
- 环境准备与项目搭建
- 第一个 Agent:天气查询助手
- 进阶:多工具协作的智能 Agent
- 三大模型 Function Calling 对比实测
- 生产环境最佳实践
- 常见问题(FAQ)
- 总结与行动建议
- 参考资料
什么是 AI Agent?从 ChatBot 到智能体的进化
2026 年,AI Agent 已经从「能调用工具的聊天机器人」进化为「可持续运行的软件系统」。一个成熟的 Agent 可以:
- 自主规划 多步骤任务并拆解执行
- 调用外部工具 获取实时数据、操作数据库、执行代码
- 维持长期记忆 跨会话记住用户偏好和上下文
- 与其他 Agent 协作 组成多 Agent 系统处理复杂任务
| 能力维度 | 传统 ChatBot | AI Agent |
|---|---|---|
| 输出形式 | 纯文本回复 | 文本 + 工具调用 + 结构化数据 |
| 信息来源 | 仅训练数据 | 训练数据 + 实时 API + 数据库 |
| 执行能力 | 无 | 可执行代码、调用 API、操作文件 |
| 任务复杂度 | 单轮问答 | 多步骤规划与执行 |
| 状态管理 | 无状态或短期上下文 | 长期记忆 + 会话管理 |
这不是概念性的差距——而是能不能帮你干活的差距。
核心原理:Function Calling 如何工作
Function Calling(也叫 Tool Use / Tool Calling)是 AI Agent 的核心引擎。它的工作流程可以用一句话概括:
模型决定调什么工具、传什么参数;你的代码负责执行;结果再喂回模型。
完整的 Agent Loop 是这样运转的:
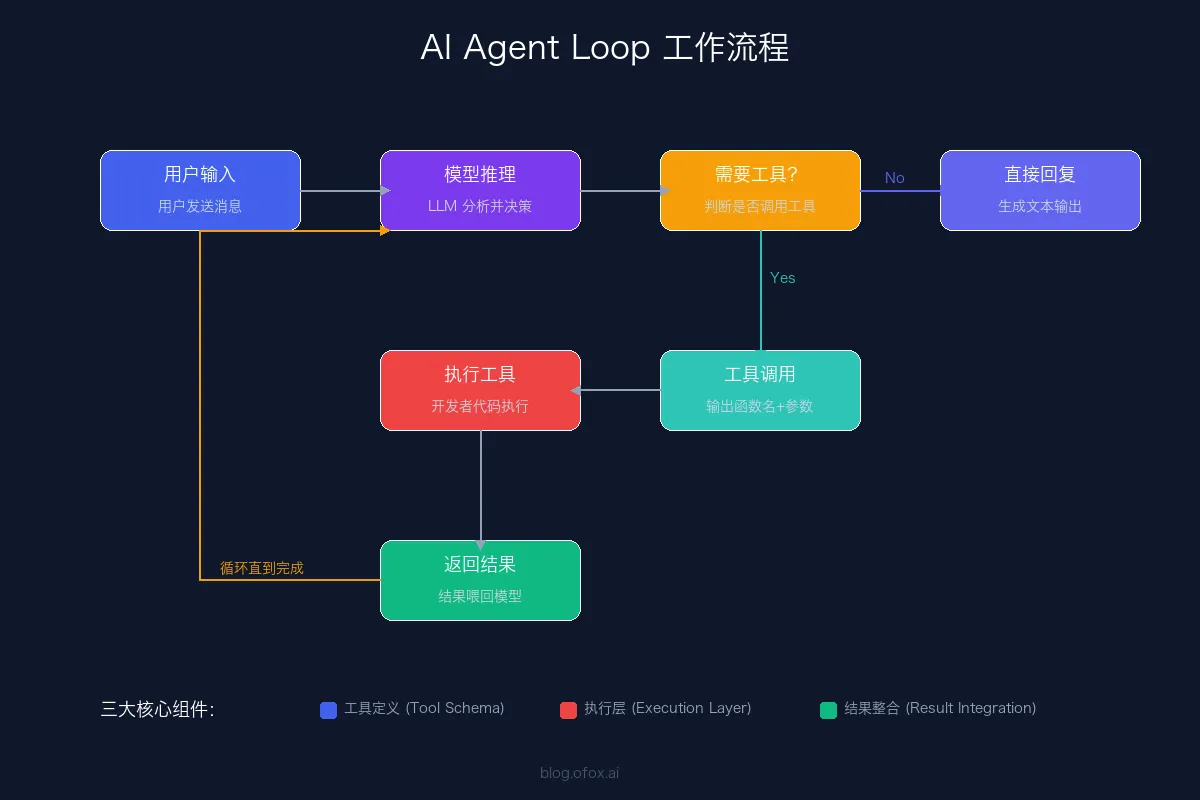
用户输入 → 模型推理 → 是否需要工具?
├─ 否 → 直接回复用户
└─ 是 → 输出工具调用指令
↓
开发者代码执行工具
↓
执行结果返回模型
↓
模型继续推理(可能再次调用工具)
↓
最终回复用户每个 Function Calling 实现都需要三个核心组件:
- 工具定义(Tool Schema):JSON Schema 格式描述工具的名称、功能和参数
- 执行层(Execution Layer):你的代码,负责真正执行工具逻辑
- 结果整合(Result Integration):将工具执行结果喂回模型,让它继续推理
环境准备与项目搭建
安装依赖
pip install openai httpx我们只需要 openai 这一个 SDK——因为所有主流模型(GPT、Claude、Gemini、DeepSeek、Qwen)都兼容 OpenAI 的 API 协议。一套代码,多模型通用。
配置 API
from openai import OpenAI
# 使用 OpenAI 兼容接口,可接入 50+ 模型
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1" # API 聚合网关,国内低延迟
)提示:如果你直接用 OpenAI 官方 API,把
base_url改为https://api.openai.com/v1即可。代码逻辑完全不变。
第一个 Agent:天气查询助手
让我们从最经典的案例开始——一个能查天气的 AI Agent。
Step 1:定义工具
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的当前天气信息,包括温度、湿度和天气状况",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如 '北京'、'上海'、'Tokyo'"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位,默认摄氏度"
}
},
"required": ["city"]
}
}
}
]关键要点:description 字段非常重要——模型根据描述决定什么时候调用这个工具。描述越精确,模型的判断越准确。
Step 2:实现工具函数
import httpx
import json
def get_weather(city: str, unit: str = "celsius") -> str:
"""调用天气 API 获取实时数据"""
# 这里用 wttr.in 作为示例,生产环境建议用付费天气 API
resp = httpx.get(f"https://wttr.in/{city}?format=j1", timeout=10)
data = resp.json()
current = data["current_condition"][0]
temp = current["temp_C"] if unit == "celsius" else current["temp_F"]
unit_label = "°C" if unit == "celsius" else "°F"
return json.dumps({
"city": city,
"temperature": f"{temp}{unit_label}",
"humidity": f"{current['humidity']}%",
"description": current["weatherDesc"][0]["value"],
"wind": f"{current['windspeedKmph']} km/h"
}, ensure_ascii=False)Step 3:实现 Agent Loop
import json
# 工具函数映射表
TOOL_FUNCTIONS = {
"get_weather": get_weather,
}
def run_agent(user_message: str):
"""运行 Agent:发送消息 → 处理工具调用 → 返回最终结果"""
messages = [
{"role": "system", "content": "你是一个智能天气助手。用自然语言回答用户的天气问题。"},
{"role": "user", "content": user_message}
]
while True:
# 1. 调用模型
response = client.chat.completions.create(
model="gpt-4.1-mini", # 也可换成 claude-sonnet-4.5、gemini-2.5-flash 等
messages=messages,
tools=tools,
tool_choice="auto"
)
msg = response.choices[0].message
messages.append(msg)
# 2. 如果没有工具调用,说明模型已经给出最终回复
if not msg.tool_calls:
return msg.content
# 3. 执行每个工具调用
for tool_call in msg.tool_calls:
func_name = tool_call.function.name
func_args = json.loads(tool_call.function.arguments)
print(f"🔧 调用工具: {func_name}({func_args})")
# 执行工具函数
result = TOOL_FUNCTIONS[func_name](**func_args)
# 将结果返回给模型
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
# 测试
answer = run_agent("北京和东京今天哪个更热?")
print(answer)运行效果:
🔧 调用工具: get_weather({"city": "北京"})
🔧 调用工具: get_weather({"city": "东京"})
今天北京气温 18°C,东京气温 15°C,北京比东京高 3 度。
北京天气晴朗,东京多云,都适合外出活动。注意观察:模型自动决定要调用两次天气查询,然后对比分析结果。这就是 Agent 的魅力——它不只是转发数据,而是在推理。
进阶:多工具协作的智能 Agent
真实场景中,Agent 通常需要协调多个工具。让我们构建一个更复杂的助手——同时具备天气查询、数据库检索和计算能力。
定义多个工具
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的当前天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
}
},
{
"type": "function",
"function": {
"name": "search_database",
"description": "搜索产品数据库,返回符合条件的产品列表",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"},
"category": {
"type": "string",
"enum": ["electronics", "clothing", "food", "books"],
"description": "产品分类"
},
"max_results": {
"type": "integer",
"description": "最大返回数量,默认 5"
}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate",
"description": "执行数学计算,支持四则运算、百分比、汇率换算等",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "数学表达式,如 '100 * 0.85' 或 '1999 * 3 + 500'"
}
},
"required": ["expression"]
}
}
}
]实现工具函数
def search_database(query: str, category: str = None, max_results: int = 5) -> str:
"""模拟数据库搜索(实际项目中连接真实数据库)"""
# 模拟数据
products = [
{"name": "MacBook Pro 16", "price": 18999, "category": "electronics", "stock": 50},
{"name": "iPhone 16 Pro", "price": 8999, "category": "electronics", "stock": 200},
{"name": "AirPods Pro 3", "price": 1899, "category": "electronics", "stock": 500},
{"name": "Python 编程指南", "price": 89, "category": "books", "stock": 1000},
]
results = [p for p in products if query.lower() in p["name"].lower()
or (category and p["category"] == category)]
return json.dumps(results[:max_results], ensure_ascii=False)
def calculate(expression: str) -> str:
"""安全的数学计算(仅允许数字和基本运算符)"""
import ast
import operator
# 使用 ast.literal_eval 的安全替代方案
allowed_operators = {
ast.Add: operator.add,
ast.Sub: operator.sub,
ast.Mult: operator.mul,
ast.Div: operator.truediv,
ast.Mod: operator.mod,
ast.Pow: operator.pow,
ast.USub: operator.neg,
}
def safe_eval(node):
if isinstance(node, ast.Expression):
return safe_eval(node.body)
elif isinstance(node, ast.Constant) and isinstance(node.value, (int, float)):
return node.value
elif isinstance(node, ast.BinOp) and type(node.op) in allowed_operators:
left = safe_eval(node.left)
right = safe_eval(node.right)
return allowed_operators[type(node.op)](left, right)
elif isinstance(node, ast.UnaryOp) and type(node.op) in allowed_operators:
return allowed_operators[type(node.op)](safe_eval(node.operand))
else:
raise ValueError(f"不支持的表达式")
try:
tree = ast.parse(expression, mode="eval")
result = safe_eval(tree)
return json.dumps({"expression": expression, "result": result})
except Exception as e:
return json.dumps({"error": str(e)})
# 更新工具映射
TOOL_FUNCTIONS = {
"get_weather": get_weather,
"search_database": search_database,
"calculate": calculate,
}实战:多工具协作
answer = run_agent("帮我查一下电子产品里有哪些苹果设备,算算买一台 MacBook Pro 和一副 AirPods 总共多少钱")
print(answer)🔧 调用工具: search_database({"query": "Mac", "category": "electronics"})
🔧 调用工具: search_database({"query": "AirPods", "category": "electronics"})
🔧 调用工具: calculate({"expression": "18999 + 1899"})
查到两款苹果设备:
- MacBook Pro 16:18,999 元(库存 50 台)
- AirPods Pro 3:1,899 元(库存 500 副)
两件合计 **20,898 元**。如果你需要下单或了解更多配置信息,随时告诉我。模型自动编排了三次工具调用:两次搜索 + 一次计算。这种多工具协作是 Agent 的核心价值。
三大模型 Function Calling 对比实测
2026 年主流模型在 Function Calling 能力上各有所长。以下是基于实际测试的对比:
| 对比维度 | GPT-5.x 系列 | Claude Opus/Sonnet 4.x | Gemini 3.1 Pro |
|---|---|---|---|
| Tool Use 准确率 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 并行工具调用 | 支持 | 支持 | 支持(最强) |
| 复杂推理后调用 | 强 | 最强 | 强 |
| 超长上下文 Tool Use | 128K | 200K | 2M(碾压) |
| API 协议 | OpenAI 原生 | OpenAI 兼容 | OpenAI 兼容 |
| 国内直连 | 需聚合网关 | 需聚合网关 | 需聚合网关 |
代码层面的差异
好消息是,如果你使用 OpenAI 兼容接口,三个模型的代码完全一样——只需要换 model 参数:
# GPT-5.4
response = client.chat.completions.create(model="gpt-5.4", messages=messages, tools=tools)
# Claude Sonnet 4.6
response = client.chat.completions.create(model="claude-sonnet-4.6", messages=messages, tools=tools)
# Gemini 3.1 Pro
response = client.chat.completions.create(model="gemini-3.1-pro", messages=messages, tools=tools)通过 API 聚合网关(如 Ofox),你可以用同一个 API Key 和 base_url 调用所有模型,在代码中随时切换,无需管理多套密钥。
模型选择建议
- 通用 Agent 开发:GPT-4.1-mini 或 Claude Sonnet 4.6(性价比最高)
- 复杂推理 Agent:Claude Opus 4.6 或 Gemini 3.1 Pro
- 超长文档处理:Gemini 3.1 Pro(2M 上下文)
- 预算敏感:DeepSeek V3 或 GPT-4.1-nano
生产环境最佳实践
从 demo 到生产,还有几个关键问题需要处理。
1. 错误处理与重试
def run_agent_production(user_message: str, max_rounds: int = 10):
"""生产级 Agent Loop,带错误处理和轮次限制"""
messages = [
{"role": "system", "content": "你是一个智能助手。如果工具调用失败,告诉用户原因并建议替代方案。"},
{"role": "user", "content": user_message}
]
for round_num in range(max_rounds):
try:
response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=messages,
tools=tools,
tool_choice="auto",
timeout=30
)
except Exception as e:
return f"API 调用失败:{e}"
msg = response.choices[0].message
messages.append(msg)
if not msg.tool_calls:
return msg.content
for tool_call in msg.tool_calls:
func_name = tool_call.function.name
try:
func_args = json.loads(tool_call.function.arguments)
func = TOOL_FUNCTIONS.get(func_name)
if not func:
result = json.dumps({"error": f"未知工具: {func_name}"})
else:
result = func(**func_args)
except json.JSONDecodeError:
result = json.dumps({"error": "参数解析失败"})
except Exception as e:
result = json.dumps({"error": f"工具执行失败: {str(e)}"})
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
return "Agent 达到最大执行轮次,请简化你的问题后重试。"2. 安全防护
Agent 能调用工具意味着它能产生副作用。务必做好安全防护:
# 工具权限控制
TOOL_PERMISSIONS = {
"get_weather": {"level": "read", "rate_limit": 60}, # 只读,每分钟 60 次
"search_database": {"level": "read", "rate_limit": 30}, # 只读
"calculate": {"level": "compute", "rate_limit": 100}, # 计算
"send_email": {"level": "write", "require_confirm": True}, # 写操作需确认
"delete_record": {"level": "dangerous", "require_confirm": True}, # 危险操作需确认
}
def execute_tool_safely(func_name: str, func_args: dict) -> str:
"""安全执行工具,带权限检查"""
perm = TOOL_PERMISSIONS.get(func_name)
if not perm:
return json.dumps({"error": "未授权的工具"})
# 危险操作需要人工确认(生产环境可接入审批系统)
if perm.get("require_confirm"):
print(f"⚠️ 高风险操作: {func_name}({func_args})")
# 在 Web 应用中可以弹出确认对话框
# confirm = await get_user_confirmation(func_name, func_args)
return json.dumps({"error": "此操作需要人工确认,已发送审批请求"})
return TOOL_FUNCTIONS[func_name](**func_args)3. 流式输出 + 工具调用
生产环境中,流式输出能显著提升用户体验:
def run_agent_streaming(user_message: str):
"""流式输出的 Agent"""
messages = [
{"role": "system", "content": "你是一个智能助手。"},
{"role": "user", "content": user_message}
]
while True:
stream = client.chat.completions.create(
model="gpt-4.1-mini",
messages=messages,
tools=tools,
stream=True
)
tool_calls_buffer = {}
content_buffer = ""
for chunk in stream:
delta = chunk.choices[0].delta
# 文本内容:实时输出
if delta.content:
print(delta.content, end="", flush=True)
content_buffer += delta.content
# 工具调用:收集完整调用信息
if delta.tool_calls:
for tc in delta.tool_calls:
idx = tc.index
if idx not in tool_calls_buffer:
tool_calls_buffer[idx] = {
"id": tc.id or "",
"name": "",
"arguments": ""
}
if tc.id:
tool_calls_buffer[idx]["id"] = tc.id
if tc.function and tc.function.name:
tool_calls_buffer[idx]["name"] = tc.function.name
if tc.function and tc.function.arguments:
tool_calls_buffer[idx]["arguments"] += tc.function.arguments
# 如果没有工具调用,返回文本内容
if not tool_calls_buffer:
print() # 换行
return content_buffer
# 执行工具调用并将结果加入 messages(同前面的逻辑)
assistant_msg = {"role": "assistant", "content": content_buffer or None, "tool_calls": []}
for idx in sorted(tool_calls_buffer.keys()):
tc = tool_calls_buffer[idx]
assistant_msg["tool_calls"].append({
"id": tc["id"],
"type": "function",
"function": {"name": tc["name"], "arguments": tc["arguments"]}
})
messages.append(assistant_msg)
for idx in sorted(tool_calls_buffer.keys()):
tc = tool_calls_buffer[idx]
func_args = json.loads(tc["arguments"])
result = TOOL_FUNCTIONS[tc["name"]](**func_args)
messages.append({
"role": "tool",
"tool_call_id": tc["id"],
"content": result
})4. 对话记忆管理
长期运行的 Agent 需要管理上下文窗口:
def manage_context(messages: list, max_tokens: int = 8000) -> list:
"""上下文窗口管理:保留系统提示和最近的对话"""
# 粗略估算 token 数(中文约 1.5 token/字)
estimated_tokens = sum(len(m.get("content", "") or "") * 1.5 for m in messages)
if estimated_tokens <= max_tokens:
return messages
# 保留 system 消息和最近的对话
system_msgs = [m for m in messages if m.get("role") == "system"]
other_msgs = [m for m in messages if m.get("role") != "system"]
# 从最近的消息开始保留
kept = []
current_tokens = sum(len(m.get("content", "") or "") * 1.5 for m in system_msgs)
for msg in reversed(other_msgs):
msg_tokens = len(msg.get("content", "") or "") * 1.5
if current_tokens + msg_tokens > max_tokens:
break
kept.insert(0, msg)
current_tokens += msg_tokens
return system_msgs + kept常见问题(FAQ)
Q: AI Agent 开发需要 GPU 吗?
A: 不需要。AI Agent 开发是纯工程开发——你通过 API 调用云端的大模型,本地只需要一台普通电脑和 Python 环境。模型推理的算力由 API 服务商提供。
Q: 一个 AI Agent 调用多少工具比较合适?
A: 建议单个 Agent 控制在 5-15 个工具。工具太少则能力有限,工具太多模型选择准确率会下降。如果需要更多能力,可以拆分成多个专业 Agent 协作。
Q: Function Calling 的参数校验怎么做?
A: 推荐使用 Pydantic 做参数校验。把工具的参数定义为 Pydantic Model,自动生成 JSON Schema 并校验输入:
from pydantic import BaseModel, Field
class WeatherParams(BaseModel):
city: str = Field(description="城市名称")
unit: str = Field(default="celsius", description="温度单位")
# 自动生成 JSON Schema
schema = WeatherParams.model_json_schema()Q: AI Agent 每次 API 调用的成本大概多少?
A: 以 GPT-4.1-mini 为例,输入 $0.4/百万 token,输出 $1.6/百万 token。一次典型的 Agent 对话(含 2-3 次工具调用)大约消耗 2000-5000 token,成本约 0.001-0.005 美元。通过 API 聚合平台通常还能获得更优惠的价格。
Q: 如何调试 Function Calling?模型不调用工具怎么办?
A: 三个排查方向:1)检查工具描述是否清晰——模型靠描述决定是否调用;2)在 system prompt 中明确告诉模型可以使用哪些工具;3)使用 tool_choice={"type": "function", "function": {"name": "xxx"}} 强制调用特定工具进行测试。
总结与行动建议
AI Agent 开发在 2026 年已经不再是高门槛的前沿技术——它是每个开发者都应该掌握的工程技能。
立即可以开始的三步:
- 跑通第一个 Agent:复制本文的天气查询代码,替换你自己的 API Key,5 分钟跑通
- 接入你的业务工具:把你项目中的数据库查询、第三方 API 封装成工具函数
- 部署到生产:加上错误处理、权限控制和对话记忆管理
如果你需要快速接入多个大模型来测试哪个最适合你的 Agent 场景,可以试试 Ofox.ai——一个 API Key 即可调用 GPT、Claude、Gemini、DeepSeek 等 50+ 模型,兼容 OpenAI SDK,国内阿里云/火山云节点加速,注册即送免费额度。