Coze(扣子)怎么配置第三方 API?接入 GPT、Claude、Gemini 全模型教程(2026)
摘要
Coze(扣子)接入第三方 API 有两条路径:SaaS 版在工作流 LLM 节点填 Base URL + Key 即可,开源版在 backend/conf/model/ 写 YAML 配置文件。国内开发者推荐用 API 聚合平台做中间层——一个 Key 接入 GPT-5、Claude 4、Gemini 3 Pro、DeepSeek V4 等 50+ 模型,延迟低、免额外网络配置。本文给你完整的配置代码和踩坑指南。
目录
- 为什么要给 Coze 接第三方 API
- 方案一:Coze SaaS 版配置自定义 API
- 方案二:Coze 开源版私有化部署 + 自定义模型
- 实战:用 API 聚合平台一键接入 50+ 模型
- 工作流多模型混用实战
- 常见报错排查手册
- FAQ
- 总结与行动建议
- 参考资料
为什么要给 Coze 接第三方 API
Coze(扣子)是字节跳动推出的 AI 智能体开发平台,2025 年 7 月正式开源后在 GitHub 上迅速获得数千 Star。它提供了可视化的工作流编排、插件系统和 Agent 管理能力,堪称国内最好用的 AI Agent 搭建工具之一。
但 Coze 内置的模型有几个痛点:
| 痛点 | 具体表现 |
|---|---|
| 模型选择有限 | SaaS 版主要提供豆包系列模型,GPT、Claude 等海外模型需要自行配置 |
| 成本不透明 | 内置模型按 Token 计费,大量调用时成本难以控制 |
| 延迟波动 | 高峰期响应速度不稳定,影响 Agent 用户体验 |
| 无法用最新模型 | GPT-5.2、Claude 4 Opus 等新模型上线后,平台支持往往滞后 |
解决方案很简单:接入第三方 API 服务。通过兼容 OpenAI 协议的 API 聚合平台,你可以:
- 一个 Key 调用 50+ 模型(GPT、Claude、Gemini、DeepSeek、Qwen 全都有)
- 按需切换模型,在工作流不同节点用不同模型
- 国内直连低延迟,不需要额外的网络配置
- 明确的按量计费,成本完全可控
下面分两种场景详细讲配置方法。
方案一:Coze SaaS 版配置自定义 API
适用场景:使用 coze.cn 在线平台,不想自己部署。
第一步:创建工作流
登录 Coze 后台,进入你的 Bot 项目,点击「工作流」→「新建工作流」。
第二步:添加 LLM 节点
在工作流画布中拖入一个 LLM 节点。这是接入自定义模型的核心:
- 点击 LLM 节点,打开配置面板
- 在「模型」下拉框中,选择底部的 「自定义模型」 或 「OpenAI 兼容」 选项
- 填入三个关键参数:
# Coze SaaS 版 LLM 节点配置
Base URL: https://api.ofox.ai/v1 # API 聚合平台地址
API Key: sk-your-api-key-here # 你的 API Key
Model: gpt-5 # 模型名称第三步:连通性测试
重要:配置完成后,不要急着接入复杂工作流。先做单节点测试:
1. 在 LLM 节点输入一条简单的 Prompt:"你好,请回复OK"
2. 点击「测试运行」
3. 确认返回结果正常
4. 检查响应时间是否在可接受范围内(通常 < 3 秒)如果测试通过,说明 API 连接正常,可以继续搭建工作流了。
第四步:Prompt 配置
LLM 节点的 Prompt 支持变量引用,这是 Coze 工作流的精髓:
你是一个专业的客服助手。
用户问题:{{input}}
历史上下文:{{context}}
请根据以上信息,给出准确、专业的回复。其中 {{input}} 和 {{context}} 是工作流中上游节点传入的变量。
超时设置建议
Coze 的 LLM 节点有超时机制,使用第三方 API 时建议:
| 参数 | 推荐值 | 说明 |
|---|---|---|
| 超时时间 | 60s | 设置为最大值,避免长回复被截断 |
| 重试次数 | 2 | 网络抖动时自动重试 |
| Temperature | 根据场景 | 客服类 0.3,创意类 0.8 |
方案二:Coze 开源版私有化部署 + 自定义模型
适用场景:需要完全掌控数据和模型配置,适合企业内部部署。
环境准备
Coze 开源版(coze-studio)的硬件门槛非常低:
# 最低配置
CPU: 2 核
内存: 4 GB
磁盘: 10 GB
系统: Linux / macOS / Windows (Docker)快速部署
# 克隆仓库
git clone https://github.com/coze-dev/coze-studio.git
cd coze-studio
# 使用 Docker Compose 一键启动
docker compose up -d
# 等待服务启动(约 1-2 分钟)
# 访问 http://localhost:8888 进入 Coze Studio 界面配置自定义模型(核心步骤)
开源版的模型配置在 backend/conf/model/ 目录下,每个模型一个 YAML 文件:
# 进入模型配置目录
cd backend/conf/model/
# 复制模板文件
cp ../template/model_template_basic gpt5.yaml编辑 gpt5.yaml:
# backend/conf/model/gpt5.yaml
id: 1001 # 模型 ID,全局唯一的非零整数
name: "GPT-5" # 显示名称
description: "OpenAI GPT-5" # 模型描述
meta:
conn_config:
api_key: "sk-your-api-key-here" # API Key
model: "gpt-5" # 模型标识
base_url: "https://api.ofox.ai/v1" # API 地址
model_config:
max_tokens: 16384 # 最大输出 Token
temperature: 0.7 # 默认 Temperature批量添加多个模型
一个 API Key 可以配置多个模型文件,每个模型用不同的 id 和 model 字段:
# claude4.yaml
id: 1002
name: "Claude 4 Sonnet"
meta:
conn_config:
api_key: "sk-your-api-key-here" # 同一个 Key
model: "claude-sonnet-4-6" # Claude 模型标识
base_url: "https://api.ofox.ai/v1"
model_config:
max_tokens: 8192
temperature: 0.5# gemini3.yaml
id: 1003
name: "Gemini 3 Pro"
meta:
conn_config:
api_key: "sk-your-api-key-here" # 同一个 Key
model: "gemini-3-pro" # Gemini 模型标识
base_url: "https://api.ofox.ai/v1"
model_config:
max_tokens: 16384
temperature: 0.7配置完成后重启服务:
docker compose restart backend刷新 Coze Studio 界面,在模型选择列表中就能看到新添加的模型了。
实战:用 API 聚合平台一键接入 50+ 模型
手动配置每个模型的官方 API 很繁琐——不同厂商的 Base URL、鉴权方式、模型命名规则都不一样。更现实的做法是使用 API 聚合平台,统一接口调用所有模型。
为什么选 API 聚合平台
| 对比项 | 逐个接官方 API | API 聚合平台 |
|---|---|---|
| Key 数量 | 每家一个,管理 5-6 个 Key | 一个 Key 搞定 |
| 协议兼容 | 各家略有差异 | 统一 OpenAI 协议 |
| 国内访问 | GPT/Claude 需要代理 | 国内直连低延迟 |
| 计费方式 | 各家独立充值 | 统一账户按量计费 |
| 模型更新 | 手动更新配置 | 平台自动同步新模型 |
配置示例(以 Ofox 为例)
- 访问 ofox.ai 注册账号,获取 API Key
- 在 Coze 中只需配置一次:
SaaS 版:
Base URL: https://api.ofox.ai/v1
API Key: sk-your-ofox-key
Model: gpt-5 # 随时切换:claude-sonnet-4-6 / gemini-3-pro / deepseek-v4开源版(创建一个配置文件即可调用不同模型):
# ofox-gpt5.yaml
id: 2001
name: "GPT-5 (via Ofox)"
meta:
conn_config:
api_key: "sk-your-ofox-key"
model: "gpt-5"
base_url: "https://api.ofox.ai/v1"换模型只需要改 model 字段,Key 和 Base URL 不变。
支持的模型列表(部分)
| 厂商 | 模型 | 模型标识 |
|---|---|---|
| OpenAI | GPT-5 | gpt-5 |
| OpenAI | GPT-5.2 | gpt-5-2 |
| OpenAI | GPT-4o | gpt-4o |
| Anthropic | Claude 4 Opus | claude-opus-4-6 |
| Anthropic | Claude 4 Sonnet | claude-sonnet-4-6 |
| Gemini 3 Pro | gemini-3-pro | |
| Gemini 3 Flash | gemini-3-flash | |
| DeepSeek | DeepSeek V4 | deepseek-chat |
| 阿里 | Qwen3.5 | qwen-max |
完整模型列表参考 Ofox 文档。
工作流多模型混用实战
Coze 工作流的真正威力在于:不同节点可以用不同模型。一个实际案例——智能客服 Agent:
场景架构
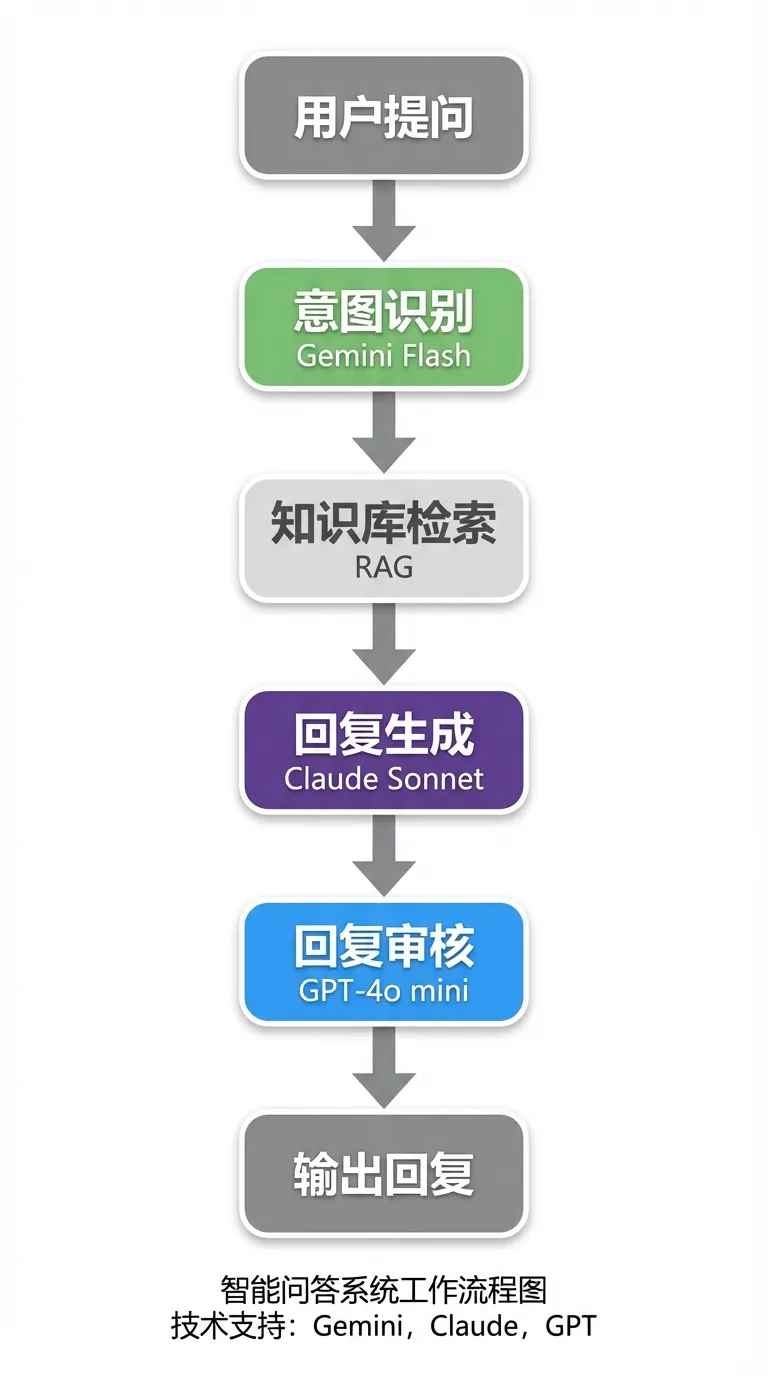
配置要点
# 节点1:意图识别(追求速度)
Model: gemini-3-flash
Temperature: 0.1
Max Tokens: 100
# 节点2:回复生成(追求质量)
Model: claude-sonnet-4-6
Temperature: 0.5
Max Tokens: 2048
# 节点3:回复审核(追求性价比)
Model: gpt-4o-mini
Temperature: 0.0
Max Tokens: 500这样做的好处:
- 意图识别用 Gemini Flash,响应快、成本低(只需要判断分类)
- 回复生成用 Claude Sonnet,文本质量最佳
- 合规审核用 GPT-4o-mini,够用且便宜
三个模型都通过同一个 API 聚合平台调用,只是 model 参数不同。
成本对比
假设每天处理 1000 次客服对话,每次对话平均 3 轮交互:
| 方案 | 单模型方案 (全用 GPT-5) | 多模型混用方案 |
|---|---|---|
| 意图识别 | $0.015/次 | $0.001/次 (Flash) |
| 回复生成 | $0.015/次 | $0.008/次 (Sonnet) |
| 回复审核 | $0.015/次 | $0.0005/次 (Mini) |
| 日均成本 | ~$135 | ~$28.5 |
| 月均成本 | ~$4,050 | ~$855 |
多模型混用方案成本降低约 79%,而回复质量反而更好(Claude 的文本生成能力公认优于 GPT-5)。
常见报错排查手册
401 Unauthorized
Error: Request failed with status code 401原因:API Key 无效或过期。
解决:
- 检查 Key 是否正确复制(前后不能有空格)
- 确认 Key 未过期、未被禁用
- 开源版检查 YAML 中
api_key字段格式是否正确(需要加引号)
422 Unprocessable Entity
Error: The model 'xxx' does not exist原因:模型名称不匹配。
解决:
- 核对 model 字段是否和 API 平台支持的模型标识完全一致
- 注意大小写:
gpt-5和GPT-5可能不同 - 查阅平台文档确认模型标识
超时 (Timeout)
Error: Request timed out after 30000ms原因:网络不通或超时时间设置太短。
解决:
- 先用 curl 测试 API 是否可达:
curl -X POST https://api.ofox.ai/v1/chat/completions \
-H "Authorization: Bearer sk-your-key" \
-H "Content-Type: application/json" \
-d '{"model":"gpt-5","messages":[{"role":"user","content":"hi"}]}'- Coze 中将超时时间调到最大(60s)
- 开源版检查服务器出网是否正常
429 Too Many Requests
Error: Rate limit exceeded原因:请求频率超过 API 限制。
解决:
- 在工作流中增加节点间延迟
- 联系 API 平台提升速率限制
- 开源版可以配置多个 Key 做负载均衡
FAQ
Q: Coze SaaS 版和开源版应该选哪个?
A: 个人开发者和小团队推荐 SaaS 版,开箱即用、免运维。对数据安全有要求的企业(如金融、医疗行业),或者需要深度定制的场景,选 开源私有化部署版。开源版只需要 2 核 4G 内存即可运行,部署门槛很低。
Q: Coze 工作流中可以混合使用内置模型和第三方 API 吗?
A: 可以。SaaS 版的不同 LLM 节点可以分别选择内置模型或自定义模型。比如简单任务用内置豆包模型(免费额度),复杂任务用第三方 GPT-5 或 Claude。
Q: API 聚合平台的延迟比直连官方 API 高吗?
A: 取决于你的网络环境。在国内,直连 OpenAI/Anthropic 官方 API 通常需要代理,实际延迟反而更高。通过部署在阿里云/火山云上的 API 聚合平台,国内请求的首 Token 延迟通常在 300-500ms,比绕代理快得多。
Q: 开源版支持哪些模型供应商?
A: 所有兼容 OpenAI API 协议的模型都可以接入,包括 OpenAI、Anthropic Claude、Google Gemini、DeepSeek、通义千问、百度文心、Llama 系列等。只要供应商提供了 /v1/chat/completions 格式的接口,就能在 Coze 开源版中配置。
总结与行动建议
- 快速上手:使用 Coze SaaS 版 + API 聚合平台,10 分钟内完成配置
- 私有部署:
docker compose up -d启动开源版,编辑 YAML 文件添加模型 - 成本优化:在工作流中根据任务特性混用不同模型,可节省 70%+ 成本
- 稳定性保障:先用单节点测试连通性,确认 OK 后再接入正式工作流
推荐的下一步: