
DeepSeek V4 API 接入指南:万亿参数多模态模型抢先体验与国内调用攻略(2026)
DeepSeek V4 API 接入指南:万亿参数多模态模型抢先体验与国内调用攻略(2026)
摘要
DeepSeek V4 是 2026 年最受期待的开源大模型——万亿参数 MoE 架构、原生多模态、1M+ 上下文窗口、Engram 条件记忆,内部基准直逼 GPT-5.4 和 Claude Opus 4.6,而推理成本可能仅为后者的 1/30 到 1/50。尽管截至 3 月 20 日尚未正式发布(预计 4 月),但架构论文、泄露基准和 OpenRouter 匿名测试已让开发者社区沸腾。本文基于已公开信息,全面解析 V4 的技术架构、性能预期、API 接入准备方案和与当前旗舰模型的深度对比,帮你在 V4 发布第一天就能跑通生产环境。
目录
- V4 发布时间线与最新动态
- 技术架构深度解析
- 性能基准与竞品对比
- API 价格预测与成本分析
- 国内三种调用方式
- 从 V3.2 迁移到 V4 的准备工作
- 实战代码:提前适配 V4
- OpenRouter 匿名测试事件复盘
- 常见问题(FAQ)
- 总结与行动建议
V4 发布时间线与最新动态
DeepSeek V4 的发布堪称 2026 年 AI 圈最大悬念。以下是关键时间线:
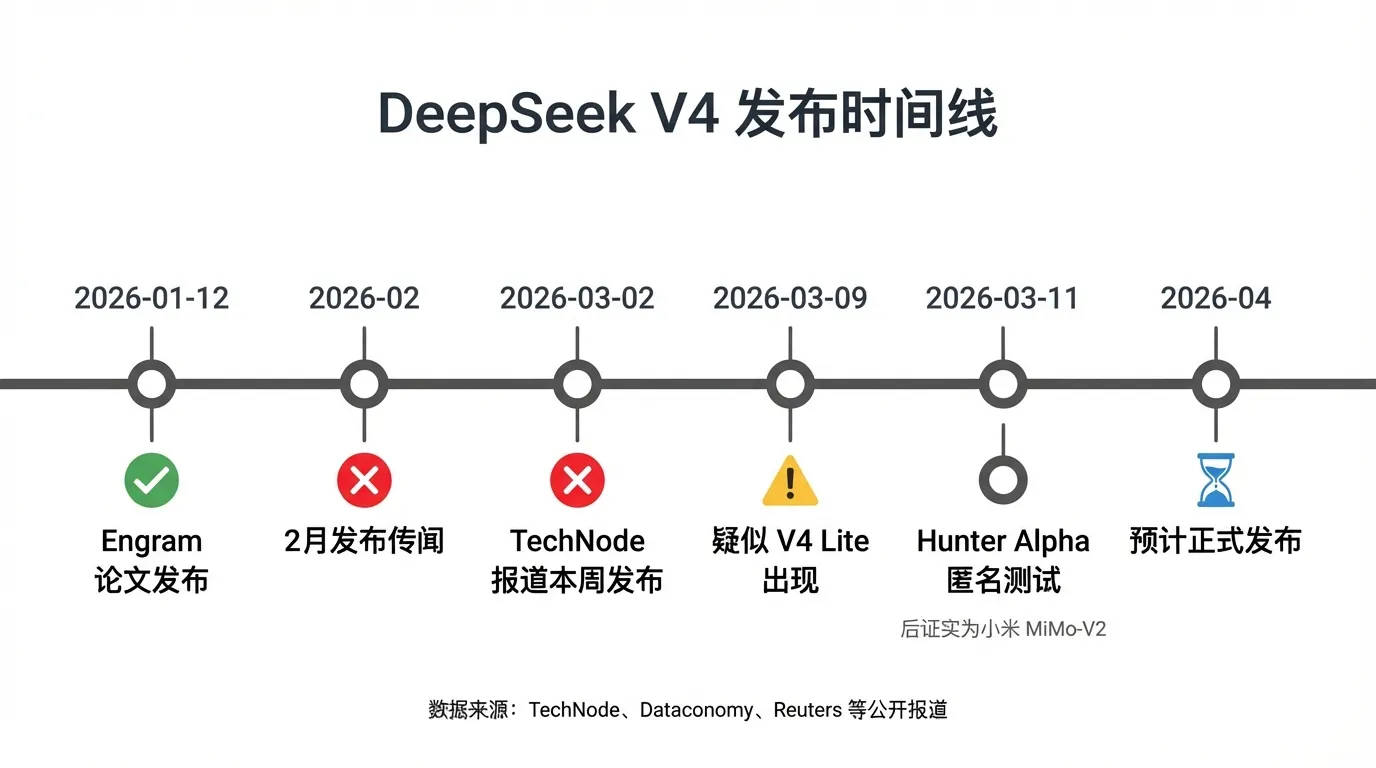
| 时间 | 事件 | 状态 |
|---|---|---|
| 2026-01-12 | DeepSeek 发布 Engram 论文,条件记忆架构 | ✅ 已确认 |
| 2026-02 | 多家媒体预测 V4 将于 2 月发布 | ❌ 未兑现 |
| 2026-03-02 | TechNode 报道「DeepSeek 计划本周发布 V4 多模态模型」 | ❌ 未兑现 |
| 2026-03-09 | 网页版出现疑似 V4 Lite 更新,社区称「V4 Lite」 | ⚠️ 未官方确认 |
| 2026-03-11 | OpenRouter 出现匿名模型 Hunter Alpha,疑似 V4 | ❌ 后证实为小米 MiMo-V2 |
| 2026-03-16 | Dataconomy 报道 V4 与腾讯混元将于 4 月发布 | 📅 待验证 |
| 2026-04(预计) | V4 正式发布 | ⏳ 等待中 |
最新判断:综合多方信源,V4 大概率在 2026 年 4 月正式发布。DeepSeek 一贯低调,多次「跳票」反而说明团队在打磨模型质量——V3 系列的成功证明了这种策略的有效性。
技术架构深度解析
V4 不是简单的参数堆叠,而是三项突破性技术的融合。
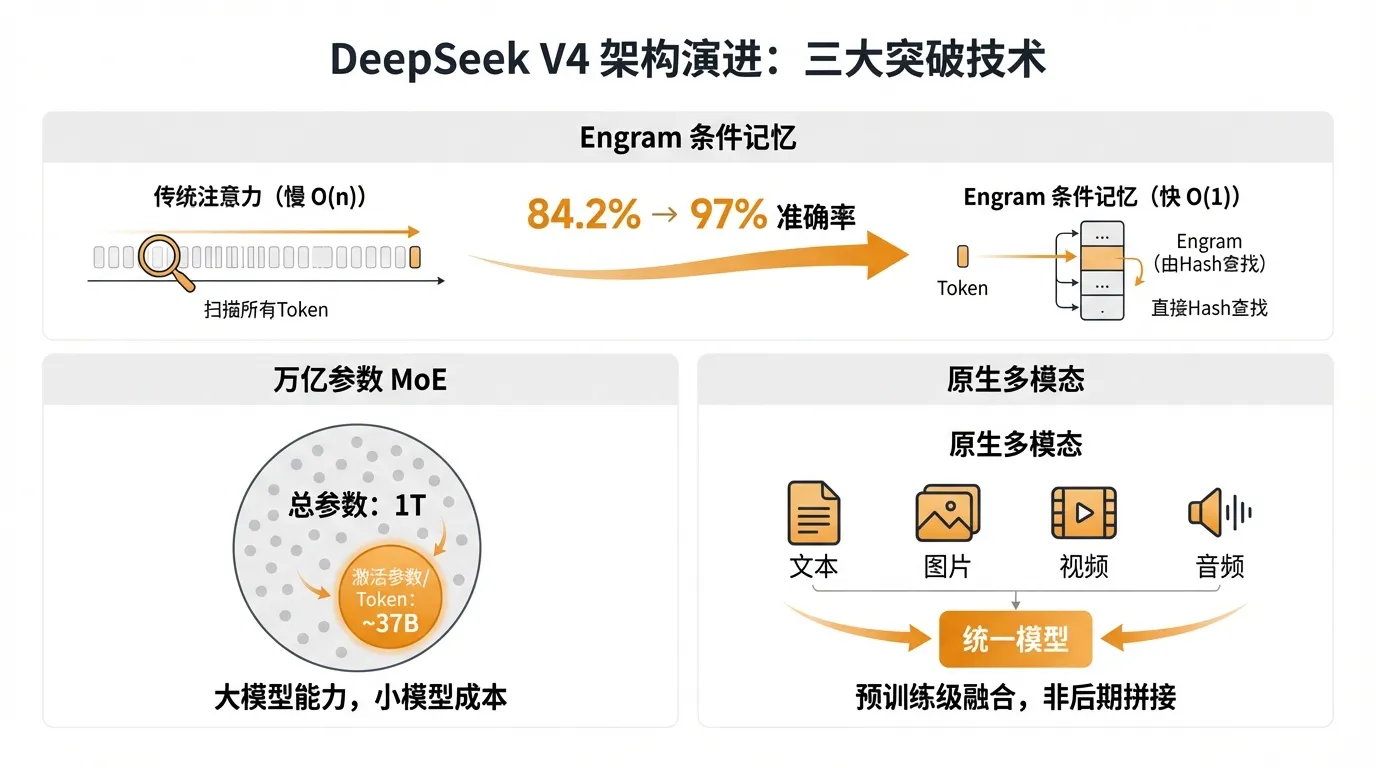
万亿参数 MoE:规模与效率兼得
| 规格 | DeepSeek V3.2 | DeepSeek V4(预期) | 提升 |
|---|---|---|---|
| 总参数 | 6710 亿 | ~1 万亿 | +50% |
| 激活参数 | ~37B | ~37B | 持平 |
| 上下文窗口 | 128K | 1M+ | 8x |
| 模态 | 纯文本 | 文本 + 图片 + 视频 + 音频 | 原生多模态 |
| 训练芯片 | NVIDIA | 华为昇腾 + 寒武纪 | 国产化 |
关键在于:总参数虽然暴增到万亿级,但每个 token 只激活约 37B 参数(与 V3.2 持平),这意味着推理成本不会显著上升。MoE 架构的精髓就在于此——用稀疏激活实现「大模型的能力,小模型的成本」。
Engram 条件记忆:重新定义长上下文
传统 Transformer 用相同的注意力计算处理所有信息——无论是检索「法国的首都」这种简单事实,还是推导数学证明。Engram 的核心洞察是:这两类任务不应该用同一种计算方式处理。
Engram 的工作原理:
- Multi-Head Hashing:将静态知识编码为哈希索引,实现 O(1) 常数时间检索
- 稀疏分配法则:20-25% 的稀疏参数分配给记忆,其余分配给计算
- 与 MoE 协同:MoE 解决「如何少算」,Engram 解决「不该算的别算」
实测效果(27B 参数模型):
| 基准 | 无 Engram | 有 Engram | 提升 |
|---|---|---|---|
| 知识基准 | 基线 | +3-5 分 | 显著 |
| Needle-in-a-Haystack | 84.2% | 97% | +12.8% |
| 推理效率 | 基线 | 提升 15-20% | 明显 |
论文由 DeepSeek 创始人梁文锋与北京大学研究者联合发表,代码已在 GitHub 开源。这不是纸上谈兵,而是已经可以复现的技术。
Manifold-Constrained Hyper-Connections(mHC)
万亿参数模型最大的挑战不是算力,而是训练稳定性。mHC 是 DeepSeek 解决这个问题的核心技术——它通过流形约束确保超大规模模型在训练过程中不会崩溃。这项技术是 V4 能够突破万亿参数的关键前提。
DeepSeek Sparse Attention + Lightning Indexer
支撑 1M+ 上下文窗口的底层技术。Lightning Indexer 通过高效索引,让模型在百万 token 的上下文中也能快速定位关键信息,配合 Engram 实现精准的长程记忆。
性能基准与竞品对比
以下对比基于已公开的基准数据。注意:DeepSeek V4 数据来自泄露的内部测试,尚未经独立验证。
编码能力对比
| 基准 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | DeepSeek V3.2 | DeepSeek V4(泄露) |
|---|---|---|---|---|---|
| SWE-bench Verified | 80.9% | ~80% | 80.6% | 72-74% | 80%+(预期) |
| HumanEval | ~88% | ~87% | ~86% | ~85% | 90%(泄露) |
| 定价(输出/1M tokens) | $25.00 | $4.50(mini) | $12.00 | $0.42 | ~$0.50-2.00(预估) |
综合能力定位
| 维度 | Claude Opus 4.6 | GPT-5.4 | DeepSeek V4(预期) |
|---|---|---|---|
| 核心优势 | 复杂代码重构、长文分析 | 推理可配置、多模态最全 | 极致性价比、开源可控 |
| 上下文窗口 | 1M | 128K-1M | 1M+ |
| 多模态 | 文本 + 图片 | 文本 + 图片 + 音频 + 视频 | 文本 + 图片 + 视频 + 音频(原生) |
| 开源 | ❌ | ❌ | ✅(预计 Apache 2.0) |
| 适合场景 | 企业级高质量输出 | 全能型产品集成 | 大规模推理、成本敏感型项目 |
务实建议:不要押注单一模型。最佳策略是多模型混用——Claude 做复杂重构,GPT-5.4 做推理调试,DeepSeek 做高并发批处理。通过 API 聚合平台,切换模型只需改一个参数。
API 价格预测与成本分析
V4 官方定价尚未公布,但我们可以基于历史数据和模型规格做合理推测。
定价预测逻辑
| 因素 | 分析 |
|---|---|
| V3.2 定价 | deepseek-chat: $0.28/$0.42,deepseek-reasoner: $0.55/$2.19 |
| 激活参数不变 | V4 激活参数 ~37B 与 V3.2 持平,推理成本理论上接近 |
| 多模态溢价 | 图片/视频输入通常比纯文本贵 2-5 倍 |
| 竞争定价策略 | DeepSeek 一贯以极低价格抢市场 |
价格预测区间
| 模型 | 输入(/1M tokens) | 输出(/1M tokens) | 置信度 |
|---|---|---|---|
| V4 文本模式 | $0.30-0.60 | $0.50-2.00 | 中 |
| V4 多模态(图片输入) | $1.00-3.00 | $0.50-2.00 | 低 |
| V4 推理模式 | $0.60-1.50 | $2.00-5.00 | 低 |
与当前旗舰模型成本对比(月度估算)
假设客服 Agent 项目,日均 1000 次对话,每次 2000 token 输入 + 1000 token 输出:
| 模型 | 月成本(估算) | 相对 V4 |
|---|---|---|
| DeepSeek V4(预估中位) | ¥ 80-150 | 1x |
| DeepSeek V3.2 | ¥ 65 | 0.5-0.8x |
| GPT-5.4 Nano | ¥ 120 | 0.8-1.5x |
| GPT-5.4 Mini | ¥ 450 | 3-6x |
| Gemini 3 Flash | ¥ 295 | 2-4x |
| Claude Sonnet 4.6 | ¥ 1,305 | 9-16x |
| Claude Opus 4.6 | ¥ 2,625 | 18-33x |
即使 V4 定价比 V3.2 上浮,仍将是主流旗舰模型中成本最低的选择。
国内三种调用方式
V4 发布后,国内开发者依然有三条成熟路径。这些路径与 V3.2 完全相同,因此现在就可以提前搭建好基础设施。
方式对比
| 维度 | 官方直连 | 云厂商托管 | API 聚合中转 |
|---|---|---|---|
| base_url | api.deepseek.com | dashscope.aliyuncs.com 等 | api.ofox.ai |
| 延迟 | 中等 | 低(内网) | 低(国内节点) |
| V4 上线速度 | 第一时间 | 1-2 周内 | 通常 24 小时内 |
| 模型范围 | 仅 DeepSeek | 仅 DeepSeek | 50+ 模型 |
| 支付方式 | 支付宝 | 企业账单 | 支付宝/微信 |
| 适合场景 | 纯 DeepSeek 项目 | 企业生产环境 | 多模型灵活切换 |
推荐策略
- 单模型项目:官方直连,价格最低
- 企业生产环境:阿里云/火山云托管,SLA 有保障
- 多模型混用:Ofox.ai 聚合平台,一个 Key 调 50+ 模型,DeepSeek V4 上线后无缝切换
从 V3.2 迁移到 V4 的准备工作
好消息是:如果你的代码已经跑通了 V3.2,迁移到 V4 大概率只需要改 model 参数。
迁移清单
| 准备项 | 操作 | 现在就做 |
|---|---|---|
| SDK 版本 | 确保 openai >= 1.50.0 | ✅ |
| 多模态支持 | 代码中预留图片/音频输入的 message 格式 | ✅ |
| 上下文管理 | 设计 1M 上下文的分段加载策略 | ✅ |
| 错误处理 | 加入模型 fallback(V4 不可用时降级到 V3.2) | ✅ |
| 成本监控 | 建立 token 用量和成本追踪 | ✅ |
多模态预适配
V4 的原生多模态意味着可以直接处理图片输入。提前适配 OpenAI Vision API 的 message 格式:
# V4 多模态调用预估格式(基于 OpenAI 兼容协议)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "描述这张架构图的设计思路"},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{base64_image}"
}
}
]
}
]实战代码:提前适配 V4
以下代码可以现在就用 V3.2 跑通,V4 发布后改一个参数即可切换。
基础调用 + 自动模型降级
from openai import OpenAI, APIError
client = OpenAI(
api_key="sk-your-key",
base_url="https://api.ofox.ai/v1" # 聚合平台,V4 上线后自动可用
)
def chat(messages: list, prefer_v4: bool = True) -> str:
"""优先使用 V4,不可用时自动降级到 V3.2"""
models = ["deepseek-chat"] # V4 发布后改为 ["deepseek-v4", "deepseek-chat"]
for model in models:
try:
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.7,
max_tokens=4096
)
return response.choices[0].message.content
except APIError as e:
if "model_not_found" in str(e).lower():
continue # 尝试下一个模型
raise
raise Exception("所有模型均不可用")推理模式(R1/R2)调用
def reason(question: str) -> tuple[str, str]:
"""调用推理模型,返回思考过程和最终答案"""
response = client.chat.completions.create(
model="deepseek-reasoner", # V4 发布后可能有新的推理模型 ID
messages=[{"role": "user", "content": question}]
)
msg = response.choices[0].message
thinking = getattr(msg, "reasoning_content", "")
return thinking, msg.content
# 示例
thinking, answer = reason("证明:对任意正整数 n,n³ + 2n 能被 3 整除")
print(f"思考过程:{thinking[:200]}...")
print(f"最终答案:{answer}")Function Calling + Agent 循环
import json
tools = [
{
"type": "function",
"function": {
"name": "search_docs",
"description": "搜索技术文档",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"},
"language": {"type": "string", "enum": ["zh", "en"]}
},
"required": ["query"]
}
}
}
]
def run_agent(user_input: str) -> str:
messages = [{"role": "user", "content": user_input}]
while True:
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools,
tool_choice="auto"
)
msg = response.choices[0].message
messages.append(msg)
if not msg.tool_calls:
return msg.content
for tc in msg.tool_calls:
result = execute_tool(tc.function.name, json.loads(tc.function.arguments))
messages.append({
"role": "tool",
"tool_call_id": tc.id,
"content": json.dumps(result, ensure_ascii=False)
})流式输出
stream = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "解释 Engram 条件记忆的工作原理"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)以上所有代码均使用 OpenAI 兼容协议。无论通过官方 API、阿里云百炼还是 Ofox.ai 聚合平台调用,代码完全一致——只需修改
base_url和api_key。完整接入文档见 Ofox.ai 开发者文档。
OpenRouter 匿名测试事件复盘
这个事件值得单独讲,因为它揭示了当前 AI 行业的竞争格局。
事件经过
- 3 月 11 日:OpenRouter 出现匿名模型 Hunter Alpha——万亿参数、1M 上下文、免费使用
- 社区猜测:规格与 V4 传闻高度吻合,路透社测试时模型自称「中国 AI 模型」,训练数据截止 2025 年 5 月(与 DeepSeek 一致)
- 流量爆发:短短数天处理超过 1600 亿 token,大量来自 OpenClaw 等 AI 编程工具
- 3 月 19 日反转:小米确认 Hunter Alpha 是其 AI 团队 MiMo 的 MiMo-V2-Pro 内测版本
关键信息
- MiMo 团队负责人罗福利是前 DeepSeek 研究员,这解释了为什么模型特征与 DeepSeek 高度相似
- 匿名测试已成为 AI 行业常态——Chatbot Arena 也经常出现未公开的匿名模型
- OpenRouter 是最大的模型路由平台,开发者通过它可以一个接口调用数十种模型,是匿名模型测试的理想平台
启示:这个事件说明两件事。第一,市场对 DeepSeek V4 的期待极高,任何疑似 V4 的模型都会引发轰动。第二,开源 AI 生态正在催生更多竞争者,前 DeepSeek 人才在小米做出了同级别的模型。
常见问题(FAQ)
Q: DeepSeek V4 什么时候发布?
A: 综合 Dataconomy、Financial Times 等多方信源,V4 预计 2026 年 4 月正式发布。此前 2 月、3 月多个传闻窗口均已推迟。DeepSeek 一贯不预告发布时间,通常是「说发就发」。
Q: DeepSeek V4 和 V3.2 有什么区别?
A: 代际升级。总参数从 6710 亿提升到万亿级,新增原生多模态(图/视频/音频),上下文窗口从 128K 扩展到 1M+,引入 Engram 条件记忆实现 O(1) 知识检索,并针对国产芯片做了深度优化。
Q: V4 的 API 会兼容现有代码吗?
A: 极大概率兼容。DeepSeek 一直保持 OpenAI 协议兼容,V3.2 到 V4 的升级应该只需修改 model 参数。多模态输入格式也会遵循 OpenAI Vision API 的标准格式。
Q: API 价格会涨吗?
A: 可能小幅上调,但仍远低于竞品。V4 激活参数与 V3.2 持平(~37B),推理成本理论上接近。多模态输入可能有额外计费。
Q: 现在应该等 V4 还是先用 V3.2?
A: 先用 V3.2 投入生产。V3.2 已经非常强大,SWE-bench 72-74%,价格极低。等 V4 发布后无缝切换,不浪费时间。
Q: V4 开源吗?模型权重可以下载吗?
A: 根据 DeepSeek 的一贯策略和多方报道,V4 预计以 Apache 2.0 许可证开源。V3 系列已在 Hugging Face 公开模型权重。
Q: V4 可以本地部署吗?
A: 万亿参数模型的本地部署对硬件要求极高。但 MoE 架构意味着推理时只激活 ~37B 参数,理论上 4×A100 80GB 或同等配置即可运行。等模型权重发布后会有更清晰的硬件需求。
Q: Engram 条件记忆对开发者意味着什么?
A: 更准确的长上下文处理。在 1M token 的上下文中,传统注意力可能「遗忘」关键信息,Engram 通过 O(1) 哈希检索确保关键知识不丢失。对需要处理大量文档的 RAG 应用尤其有价值。
Q: 国内调用 DeepSeek V4 有延迟问题吗?
A: DeepSeek 服务器在国内,官方 API 延迟表现良好。如果需要更低延迟,可以用阿里云百炼(内网调用)或 Ofox.ai(国内加速节点)。高峰期排队问题可以通过中转平台的多源路由缓解。
Q: DeepSeek V4 对 AI 编程工具(OpenClaw/Cursor)有什么影响?
A: 巨大影响。V4 的万亿参数 + 1M 上下文 + 原生多模态,意味着它可以同时理解代码库、设计稿和文档。Hunter Alpha 在 OpenRouter 测试期间,大量流量就来自 OpenClaw。V4 有望成为 AI 编程工具的最佳后端之一。
Q: 如何一个 Key 同时使用 DeepSeek、GPT、Claude?
A: 通过 Ofox.ai 等 API 聚合平台。统一的 OpenAI 兼容接口,一个 Key 调用 50+ 模型,阿里云/火山云国内节点加速,支付宝/微信支付。查看接入文档 →
总结与行动建议
DeepSeek V4 将是 2026 年最重要的开源 AI 模型发布——万亿参数、原生多模态、1M+ 上下文,成本仍保持在竞品的 1/10 以下。虽然尚未正式发布,但现在就应该做好准备。
立即行动的四步:
- 跑通 V3.2 → 如果还没用过 DeepSeek API,现在注册领 500 万 token 免费额度
- 代码适配 → 用上面的 fallback 代码模式,V4 上线后改参数即可切换
- 预留多模态 → 在消息格式中预适配图片/音频输入
- 多模型策略 → 用 Ofox.ai 聚合平台 一个 Key 管理所有模型,V4 发布后第一时间可用
Ofox.ai 提供统一的 OpenAI 兼容接口,一个 Key 调用 DeepSeek、GPT-5.4、Claude 4.6、Gemini 3 等 50+ 模型,阿里云/火山云国内节点加速低延迟。查看接入文档 →
参考资料
- Engram: Conditional Memory via Scalable Lookup(论文)
- DeepSeek Engram GitHub 仓库
- DeepSeek V4 技术解析(NxCode)
- DeepSeek V4 与腾讯混元将于 4 月发布(Dataconomy)
- Hunter Alpha 确认为小米 MiMo-V2(Japan Times)
- DeepSeek V4 vs Claude Opus 4.6 vs GPT-5.4 对比(Evolink)
- Engram 记忆架构解析(Tom’s Hardware)
- DeepSeek 官方 API 文档
- OpenAI GPT-5.4 Mini/Nano 发布公告
- Anthropic Claude API 定价
- Google Gemini API 定价
- Ofox.ai 开发者文档


