Dify 怎么配置 API?模型供应商接入与自定义 API 完整指南(2026)
摘要
Dify 配置 AI API 有三种方式:官方模型供应商(填 Key 即用)、OpenAI 兼容自定义 API(接入第三方服务)、本地模型(Ollama/vLLM)。国内开发者推荐用 API 聚合平台作为中间层,一个 Key 就能在 Dify 里用上 GPT、Claude、Gemini 等 50+ 模型,延迟低且稳定。
目录
- 为什么 Dify 的 API 配置这么重要
- 方式一:官方模型供应商(最简单)
- 方式二:OpenAI 兼容自定义 API(最灵活)
- 方式三:接入本地模型
- 实战:用 API 聚合平台一站式接入 50+ 模型
- 多模型负载均衡与故障切换
- 工作流中的模型分级策略
- 常见报错与解决方案
- 常见问题(FAQ)
- 总结与行动建议
- 参考资料
为什么 Dify 的 API 配置这么重要
Dify 是目前最火的开源 AI 应用开发平台,GitHub 星标超过 90k。它让你通过可视化界面构建 AI 工作流、聊天机器人、Agent 智能体,不写一行代码就能搭建复杂的 AI 应用。
但 Dify 本身不提供大模型——它是一个编排平台,需要你接入外部的 AI 模型 API 才能运转。这意味着:
- API 配置是第一步:没有正确配置模型,Dify 里什么都跑不起来
- 选对 API 决定体验:延迟、稳定性、价格都取决于你接入的 API 服务
- 多模型切换是核心优势:Dify 最强的能力之一就是在工作流中灵活切换不同模型
下面手把手教你三种配置方式,从入门到进阶。
方式一:官方模型供应商(最简单)
Dify 内置了数十家模型供应商的集成,填入 API Key 就能直接使用。
配置步骤
- 登录 Dify 后台,点击右上角头像 → 设置
- 左侧菜单选择 模型供应商
- 找到你要用的供应商(如 OpenAI),点击 设置
- 输入 API Key,点击保存
支持的主流供应商
| 供应商 | 代表模型 | 适合场景 |
|---|---|---|
| OpenAI | GPT-4o、GPT-4o-mini、o3 | 通用对话、代码生成 |
| Anthropic | Claude Sonnet 4.6、Opus 4.6 | 长文本分析、复杂推理 |
| Gemini 3 Pro、Flash | 多模态任务、性价比 | |
| DeepSeek | DeepSeek-V3、R1 | 中文场景、代码能力 |
| 通义千问 | Qwen3.5、Qwen-Max | 国内部署、中文理解 |
| Azure OpenAI | GPT-4o(Azure 托管) | 企业合规、数据安全 |
注意事项
- 每个供应商的 API Key 需要从其官网单独申请
- 部分海外供应商(OpenAI、Anthropic、Google)在国内可能无法直连
- 如果遇到网络问题,看下面的「方式二」
方式二:OpenAI 兼容自定义 API(最灵活)
这是 Dify 最强大的功能之一——通过 OpenAI-API-compatible 通道,你可以接入任何兼容 OpenAI 协议的 API 服务。
为什么需要自定义 API?
- 国内无法直连 OpenAI / Anthropic / Google 等海外服务
- 想用 API 聚合平台 统一管理多个模型
- 需要接入 自部署的模型服务(如 vLLM、text-generation-inference)
- 公司有自己的 API 网关,需要走内部代理
配置步骤
- 在模型供应商页面,找到 OpenAI-API-compatible
- 点击 添加模型
- 填写以下信息:
模型名称:gpt-4o(或你要用的模型 ID)
API Key:你的 API Key
API Base URL:https://your-api-provider.com/v1- 选择模型类型(LLM / Text Embedding / Speech2Text / TTS)
- 设置模型参数上限(上下文长度、最大输出 token 等)
- 点击保存
关键参数说明
| 参数 | 说明 | 示例 |
|---|---|---|
| Model Name | 模型 ID,必须与 API 供应商的模型名一致 | gpt-4o、claude-sonnet-4-6 |
| API Key | 你在 API 服务商处获取的密钥 | sk-xxxxx |
| API Base URL | API 服务地址,必须以 /v1 结尾 | https://api.example.com/v1 |
| Context Size | 模型最大上下文窗口 | 128000 |
| Max Tokens | 单次最大输出 token | 16384 |
| Vision Support | 是否支持图片输入 | 勾选 |
| Function Calling | 是否支持函数调用 | 勾选 |
| Streaming | 是否支持流式输出 | 勾选 |
常见坑:API Base URL 末尾多一个
/可能导致请求失败。正确格式是https://api.example.com/v1,不是https://api.example.com/v1/。
配置验证
保存后,点击模型名称旁的 测试 按钮,发送一条测试消息。如果返回正常响应,说明配置成功。
方式三:接入本地模型
如果你对数据隐私有严格要求,或者想零成本使用开源模型,Dify 支持接入本地部署的模型。
Ollama(推荐)
Ollama 是最简单的本地模型运行工具:
# 1. 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 2. 拉取模型
ollama pull llama3.1:8b
ollama pull qwen3.5:14b
# 3. 启动服务(默认端口 11434)
ollama serve在 Dify 中配置:
- 模型供应商 → 找到 Ollama
- Base URL 填写
http://localhost:11434(Docker 部署 Dify 时用http://host.docker.internal:11434) - 选择已下载的模型
vLLM
适合需要高吞吐量的生产环境:
# 启动 vLLM 服务(OpenAI 兼容模式)
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-8B-Instruct \
--port 8000在 Dify 中通过 OpenAI-API-compatible 方式接入,API Base URL 填 http://localhost:8000/v1。
本地 vs 云端 API 对比
| 维度 | 本地部署 | 云端 API |
|---|---|---|
| 成本 | 硬件一次性投入 | 按 token 计费 |
| 延迟 | 取决于 GPU 性能 | 通常 <1s(首 token) |
| 隐私 | 数据不出本地 | 需信任供应商 |
| 模型能力 | 受限于本地硬件 | 可用旗舰级模型 |
| 运维 | 需自行维护 | 零运维 |
| 适合场景 | 隐私敏感、内网环境 | 快速上线、追求最优效果 |
实战:用 API 聚合平台一站式接入 50+ 模型
对于大多数开发者来说,最现实的方案是:用一个 API 聚合平台,统一接入所有模型。
为什么不直接用各家官方 API?
- 国内网络问题:OpenAI、Anthropic、Google 官方 API 在国内延迟高或无法访问
- 管理复杂度:每个供应商都要单独注册、充值、管理 Key
- 成本不透明:多个账单分散在不同平台,难以统一管控
- 切换成本高:想试新模型还得重新走一遍注册流程
API 聚合平台的工作原理
你的 Dify 应用
↓ OpenAI 兼容协议
API 聚合平台(统一入口)
↓ 智能路由
┌───────┬───────┬───────┬────────┐
│OpenAI │Claude │Gemini │DeepSeek│ ...50+ 模型
└───────┴───────┴───────┴────────┘聚合平台提供一个统一的 OpenAI 兼容接口,你只需要一个 API Key,就能调用所有模型。以 Ofox 为例,在 Dify 中配置非常简单:
Dify 接入示例
在 Dify 模型供应商页面,添加 OpenAI-API-compatible 模型:
接入 GPT-4o:
模型名称:gpt-4o
API Key:你的聚合平台 Key
API Base URL:https://api.ofox.ai/v1
上下文长度:128000
最大输出:16384
✅ Vision Support
✅ Function Calling
✅ Streaming接入 Claude Sonnet 4.6:
模型名称:anthropic/claude-sonnet-4-6
API Key:同一个 Key
API Base URL:https://api.ofox.ai/v1
上下文长度:200000
最大输出:64000
✅ Vision Support
✅ Function Calling
✅ Streaming接入 Gemini 3 Flash:
模型名称:google/gemini-3-flash
API Key:同一个 Key
API Base URL:https://api.ofox.ai/v1
上下文长度:1000000
最大输出:65536
✅ Vision Support
✅ Function Calling
✅ Streaming关键优势:三个模型用同一个 API Key 和同一个 Base URL,在 Dify 里自由切换。
用 Python 验证 API 连通性
在配置 Dify 之前,建议先用脚本验证 API 是否正常:
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
# 测试 GPT-4o
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "你好,请用一句话介绍自己"}],
max_tokens=100
)
print(response.choices[0].message.content)如果正常返回响应,就可以放心在 Dify 中配置了。
多模型负载均衡与故障切换
Dify 支持为同一个模型配置多组凭据,实现自动负载均衡。
配置方法
- 添加第一组模型凭据(API Key A + Base URL A)
- 再次添加相同模型名称和类型的凭据(API Key B + Base URL B)
- Dify 自动将两组凭据合并,请求时自动轮换
负载均衡策略
用户请求 → Dify
↓
┌─── 凭据 A(50%流量)
│ API Key: sk-aaa
│ Base URL: https://provider-a.com/v1
│
└─── 凭据 B(50%流量)
API Key: sk-bbb
Base URL: https://provider-b.com/v1使用场景
- 突破速率限制:单个 Key 的 RPM(每分钟请求数)不够用时,多 Key 轮换
- 故障切换:一个供应商出问题时自动切到另一个
- 成本优化:在不同供应商之间分散调用量,利用各家的免费额度
工作流中的模型分级策略
Dify 工作流的一大优势是:不同节点可以用不同模型。合理分级能大幅降低成本。
推荐分级方案
| 任务类型 | 推荐模型 | 价格(每百万 token) | 说明 |
|---|---|---|---|
| 意图识别 / 分类 | GPT-4o-mini | $0.15 / $0.60 | 简单任务,小模型足够 |
| 文本摘要 / 改写 | Gemini 3 Flash | $0.50 / $3.00 | 高性价比,速度快 |
| 复杂推理 / 分析 | Claude Sonnet 4.6 | $3.00 / $15.00 | 长文本强,逻辑好 |
| 代码生成 / Debug | GPT-4o | $2.50 / $10.00 | 代码能力强 |
| 图片理解 | Gemini 3 Pro | $2.00 / $12.00 | 多模态最强 |
工作流设计示例
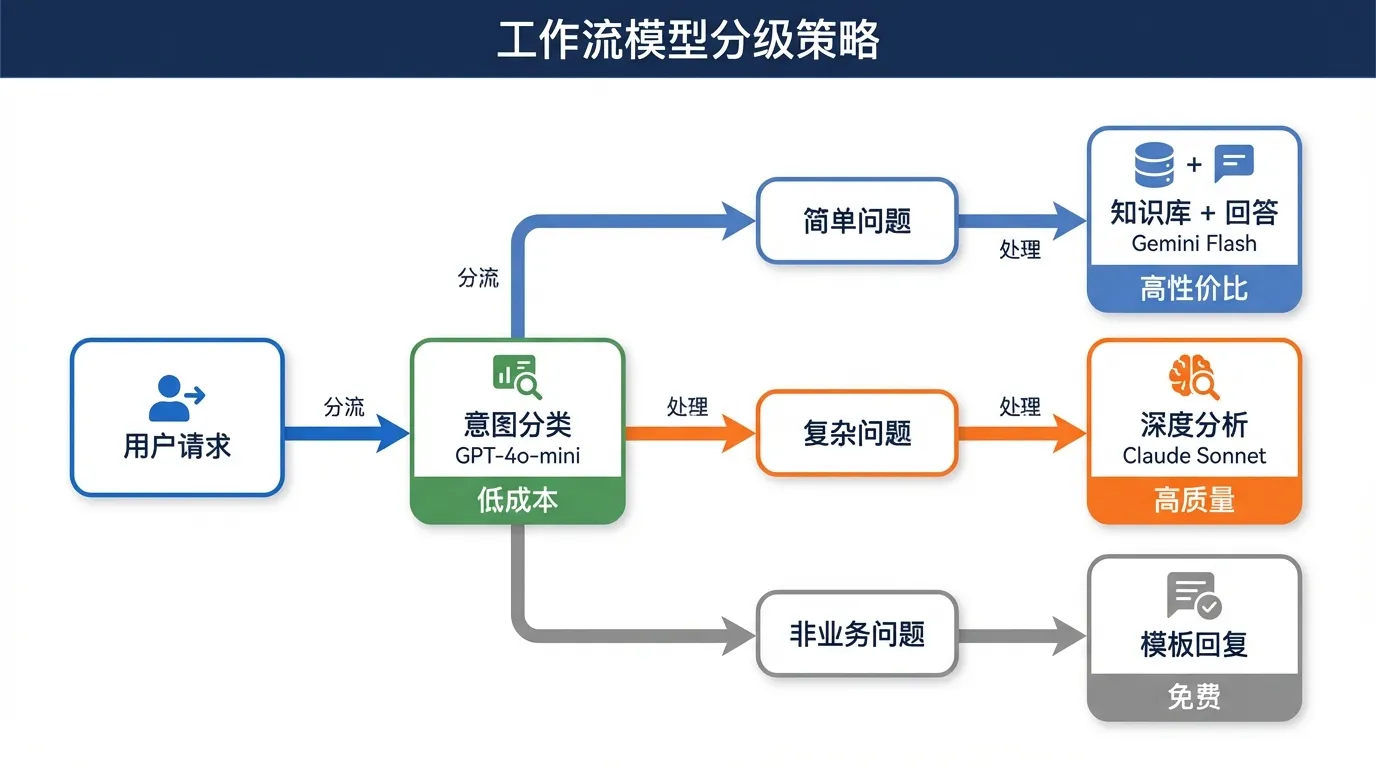
以一个「智能客服」工作流为例:
用户提问
↓
[意图分类] ← GPT-4o-mini($0.15/M)
↓
├── 简单问题 → [知识库检索 + 回答] ← Gemini 3 Flash($0.50/M)
├── 复杂问题 → [深度分析 + 回答] ← Claude Sonnet 4.6($3.00/M)
└── 非业务问题 → [礼貌拒绝] ← 模板回复(免费)这种分级策略下,80% 的请求走低成本模型,整体费用比全部用旗舰模型降低 70% 以上。
常见报错与解决方案
401 Unauthorized
Error: Incorrect API key provided原因:API Key 无效 解决:
- 重新复制 API Key,注意前后不要有空格
- 确认 Key 未过期或被吊销
- 如果用自定义 Base URL,确认 Key 与对应平台匹配
404 Not Found
Error: The model 'xxx' does not exist原因:模型 ID 不正确 解决:
- 检查模型名称拼写(区分大小写)
- 确认你的 API 套餐包含该模型
- 查看供应商文档获取正确的模型 ID
429 Too Many Requests
Error: Rate limit reached原因:请求频率超过限制 解决:
- 降低并发请求数
- 配置多组 API Key 做负载均衡
- 使用 API 聚合平台,通常有更高的速率限制
连接超时
Error: Connection timeout原因:网络问题,多见于国内直连海外 API 解决:
- 使用 API 聚合平台的国内加速节点
- 检查防火墙和代理设置
- Docker 部署时确认网络模式配置正确
Dify Docker 环境下无法访问本地模型
Error: Connection refused (localhost:11434)原因:Docker 容器内的 localhost 不是宿主机
解决:将 Ollama 地址改为 http://host.docker.internal:11434(macOS/Windows)或宿主机实际 IP(Linux)。
常见问题(FAQ)
Q: Dify 社区版和云端版在 API 配置上有区别吗?
A: 功能上基本一致。社区版(自部署)需要自行准备所有 API Key;云端版(dify.ai)额外提供了 Dify 自己的模型供应商选项,内置了一些模型额度。核心的自定义 API 配置流程完全一样。
Q: Dify 配置的 API Key 安全吗?
A: 社区版中,Key 加密存储在你自己的数据库里,不会外传。云端版中,Key 存储在 Dify 的服务器上。如果安全性是首要考虑,建议使用社区版自部署。
Q: 配置了模型但工作流里选不到怎么办?
A: 检查三点:1)模型类型是否匹配(LLM 节点只能选 LLM 类型的模型);2)模型状态是否正常(测试是否通过);3)刷新页面或重新进入工作流编辑器。
Q: Embedding 模型怎么配置?
A: 同样在 OpenAI-API-compatible 中添加,模型类型选择 Text Embedding,模型名填 text-embedding-3-small 或 text-embedding-ada-002。知识库索引和检索都需要 Embedding 模型。
Q: 可以在 Dify 中使用 Rerank 模型吗?
A: 可以。在模型供应商中添加 Rerank 模型(如 Cohere rerank-v3.5 或 bge-reranker),然后在知识库检索设置中启用 Rerank 功能,能显著提升检索准确性。
总结与行动建议
三步搞定 Dify API 配置
- 评估需求:确定你需要哪些模型,是否有网络限制
- 选择接入方式:
- 能直连 → 用官方模型供应商,最简单
- 国内使用 → 用 OpenAI 兼容 API + 聚合平台
- 隐私要求高 → 用 Ollama 本地部署
- 优化配置:
- 配置多组凭据做负载均衡
- 工作流中按任务分级选模型
- 定期检查 API 用量和错误率
推荐方案
对于大多数国内开发者,最省心的方案是:
用 API 聚合平台 + Dify 的 OpenAI-API-compatible 通道。一个 Key、一个 Base URL,50+ 模型随便切换,国内低延迟访问。
如果你还没有合适的 API 聚合平台,可以试试 Ofox——统一的 OpenAI 兼容接口,注册即送体验额度,支持 GPT、Claude、Gemini、DeepSeek 等主流模型。