Llama 4 开源 vs Claude/GPT 闭源:成本与性能深度分析
Meta Llama 4 开源模型与 Claude Opus 4.6、GPT-5.4 闭源模型的全方位对比:API 成本、自托管成本、性能差异、适用场景。帮你选出最适合的 LLM 方案。
TL;DR — Meta Llama 4 有两个版本:Scout(109B 参数,10M context)和 Maverick(400B 参数)。自托管单卡 H100 月租 $800-1200,月处理 10 亿 token 以上比 Claude API($30000)便宜。但你需要懂 GPU 运维。月处理量不到 1 亿 token?直接用 ofox.ai API 更划算。
Llama 4 两个变体:Scout vs Maverick
Meta 在 2026 年 4 月发布 Llama 4,首次采用 MoE(混合专家)架构,推出两个针对不同场景的变体:
| 特性 | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| 激活参数 | 17B | 17B |
| 总参数 | 109B(16 专家) | 400B(128 专家) |
| 上下文窗口 | 10M tokens | 1M tokens |
| 硬件需求 | 单 H100(INT4 量化) | 多卡分布式 |
| 适用场景 | 长文档分析、法律合同审查 | 复杂推理、代码生成 |
| 知识截止 | 2024 年 8 月 | 2024 年 8 月 |
Scout 能处理 10M tokens(约 300 万中文字),一次读完整本书不用分段。Maverick 在 MATH benchmark 上 78.9 分,比 GPT-5.4 的 83.4 低 4.5 个百分点。
成本对比:三种部署方式
方式 1:通过 API 调用(ofox.ai)
ofox.ai 已接入 Llama 4,按 token 计费,无需自己管理 GPU:
| 模型 | 输入价格 | 输出价格 | 100 万 token 成本 |
|---|---|---|---|
| Llama 4(ofox) | 待公布 | 待公布 | 预计 $0.2-0.5 |
| Claude Opus 4.6 | $5/M | $25/M | $30(1:1 输入输出) |
| GPT-5.4 | $2.5/M | $15/M | $17.5 |
月处理量不到 1 亿 token?或者只是想快速验证想法?用 API。
# ofox.ai 调用 Llama 4 示例(OpenAI SDK 兼容)
from openai import OpenAI
client = OpenAI(
api_key="your-ofox-api-key",
base_url="https://api.ofox.ai/v1"
)
response = client.chat.completions.create(
model="meta/llama-4-scout", # 或 llama-4-maverick
messages=[{"role": "user", "content": "分析这份 50 页的合同..."}]
)方式 2:自托管(云 GPU)
租用云 GPU 自己部署 Llama 4:
| 配置 | GPU 型号 | 月租金 | 适合模型 | 月处理量 |
|---|---|---|---|---|
| 单卡 | H100 80GB | $800-1200 | Scout(INT4) | ~10 亿 token |
| 双卡 | 2×H100 | $1600-2400 | Maverick(FP16) | ~5 亿 token |
| 四卡 | 4×A100 | $2000-3000 | Maverick(FP16) | ~8 亿 token |
隐藏成本:
- 运维人力:MLOps 工程师 $8000-15000/月
- 部署调优:vLLM/TGI 配置、量化方案,首次 2-4 周
- 监控告警:Prometheus + Grafana,$200-500/月
- 备份容灾:模型权重存储 + 多区域部署,$300-800/月
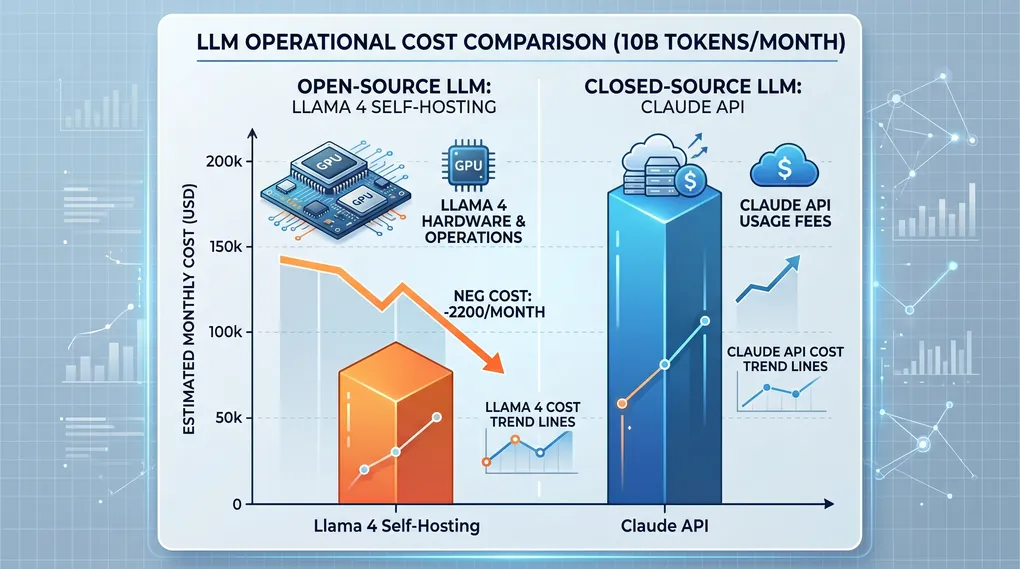
月处理 10 亿 token 以上时,自托管开始省钱:$2200(GPU + 运维)vs Claude API $30000。
方式 3:本地部署(自有硬件)
购买 GPU 服务器一次性投入:
| 配置 | 硬件成本 | 电费/月 | 3 年 TCO | 适合谁 |
|---|---|---|---|---|
| 1×H100 | $30000 | $150 | $35400 | 创业公司 |
| 4×A100 | $60000 | $400 | $74400 | 中型团队 |
数据不能出内网(金融、医疗)?或者月处理量超 100 亿 token?买硬件自己跑。
性能对比:Llama 4 vs 闭源模型
基于 MMLU、HumanEval、MATH 等公开 benchmark(2026 年 4 月数据):
| 能力维度 | Llama 4 Maverick | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| 通用知识(MMLU) | 86.2 | 88.7 | 89.1 |
| 代码生成(HumanEval) | 84.5 | 87.3 | 88.9 |
| 数学推理(MATH) | 78.9 | 82.1 | 83.4 |
| 长文档理解 | ⭐ Scout 10M context | 200K context | 128K context |
| 多语言支持 | 12 种语言 | 100+ 语言 | 80+ 语言 |
Llama 4 Maverick 在通用任务上落后闭源模型 2-5 个百分点。但 Scout 的 10M context 处理长文档时没对手。
五个实际场景
创业公司 MVP
月处理 500 万 token,想快速上线 AI 功能。
用 ofox.ai API 调 Llama 4 或 GPT-5.4-mini。不用买硬件,按需付费,专心做产品。
法律文档分析 SaaS
处理 100 页合同,提取条款风险点。
Llama 4 Scout(10M context)通过 ofox.ai。一次加载整份合同,不用分段丢上下文。
代码生成工具(月活 10 万)
月处理 20 亿 token,要求低延迟。
自托管 Llama 4 Maverick(4×A100)。成本 $3000/月 vs Claude API $60000/月。
金融风控系统
数据不能出内网,实时反欺诈。
本地部署 Llama 4 Maverick。满足合规,推理延迟 < 100ms。
内容审核(UGC 平台)
日处理 1 亿条短文本,成本敏感。
自托管 Llama 4 Scout + 批量推理。API 成本 $5000/天,自托管 $1200/月 + 电费。
开源模型的实际优势
数据隐私
闭源 API 的数据会过厂商服务器(即使声称”不训练”)。Llama 4 自托管后,推理全程在你的 VPC 内:
- 用户隐私数据(医疗记录、金融交易)
- 商业机密(未公开财报、产品路线图)
- 受监管数据(GDPR、HIPAA 合规)
微调定制
Llama 4 支持 LoRA 微调(Together AI 报价:Scout $3/M tokens,Maverick $8/M tokens)。1 万条领域数据微调后,垂直任务能超越通用闭源模型。
法律合同审查微调后,条款提取准确率从 82% 升到 94%。Claude API 做不到这种定制。
无 rate limit
Claude API 有 RPM 限制,高峰期容易 429 错误。自托管 Llama 4 后,QPS 只受 GPU 算力限制:
- 批量处理历史数据(一次跑 100 万条)
- 实时响应突发流量(营销活动、热点事件)
- 并发服务多个客户(SaaS 多租户)
怎么选?
月处理量 < 1 亿 token?
├─ 是 → 用 ofox.ai API(Llama 4 或 GPT-5.4-mini)
└─ 否 → 继续
数据必须内网部署?
├─ 是 → 自托管 Llama 4(本地或私有云)
└─ 否 → 继续
有 MLOps 团队?
├─ 是 → 云 GPU 自托管(成本降 80%)
└─ 否 → ofox.ai API + 逐步建运维能力通过 ofox.ai 开始
ofox.ai 提供 Llama 4、Claude、GPT 统一接入,一个 API Key 调所有模型:
- 访问 ofox.ai 注册(微信/邮箱)
- 控制台创建 API Key,首次送 $5 额度
- 改
model参数就能切换模型,代码不用重写
# 对比三个模型的响应(同一段代码)
curl https://api.ofox.ai/v1/chat/completions \
-H "Authorization: Bearer YOUR_OFOX_KEY" \
-d '{
"model": "meta/llama-4-scout", # 或 anthropic/claude-opus-4.6, openai/gpt-5.4
"messages": [{"role": "user", "content": "解释量子纠缠"}]
}'总结
Llama 4 在长文档处理(10M context)和成本上有优势。怎么选:
- 月处理量 < 1 亿 token:ofox.ai API,按需付费
- 月处理量 > 10 亿 token:云 GPU 自托管,成本降 80%
- 数据不能出内网:本地部署
开源不等于免费。GPU、运维、调优都要钱。但业务规模起来后,Llama 4 的总成本会比闭源 API 低很多。
在 ofox.ai 可以用同一套代码对比 Llama 4、Claude、GPT 的实际效果。
延伸阅读:
- Llama 4 开源模型技术解读:MoE 架构、版本对比与选型指南 — Scout/Maverick 的技术架构、实际表现与部署方案深度分析