MCP 协议实战:用 Python 给 AI Agent 装上「外挂」的标准化方案(2026 完全指南)
最近在折腾 AI Agent 的工具调用,被各种私有协议搞得头大。OpenAI 的 Function Calling 一套规范,Anthropic 的 Tool Use 又是另一套,换个模型就要重写一遍集成代码。直到用上 MCP(Model Context Protocol),才发现这才是正确的打开方式 — 写一次 Server,所有支持 MCP 的客户端都能用。
先说结论
| 对比项 | 传统 Function Calling | MCP 协议 |
|---|---|---|
| 标准化 | 各厂商各一套 | 统一开放标准 |
| 复用性 | 换模型要改代码 | 一次开发到处用 |
| 生态 | 封闭 | 社区驱动,Server 可共享 |
| 调试 | 各自为政 | 统一 Inspector 工具 |
| 适用场景 | 单模型应用 | 多模型、多客户端 |
结论很简单:如果你的 AI 应用需要调用外部工具,2026 年该用 MCP 了。
什么是 MCP?一句话说清楚
MCP 全称 Model Context Protocol,最早由 Anthropic 在 2024 年底发布,到 2026 年已经成了 AI 工具调用的事实标准。你可以把它理解为 AI 世界的 USB 接口 — 不管什么品牌的设备(大模型),插上就能用。
核心架构很简单:
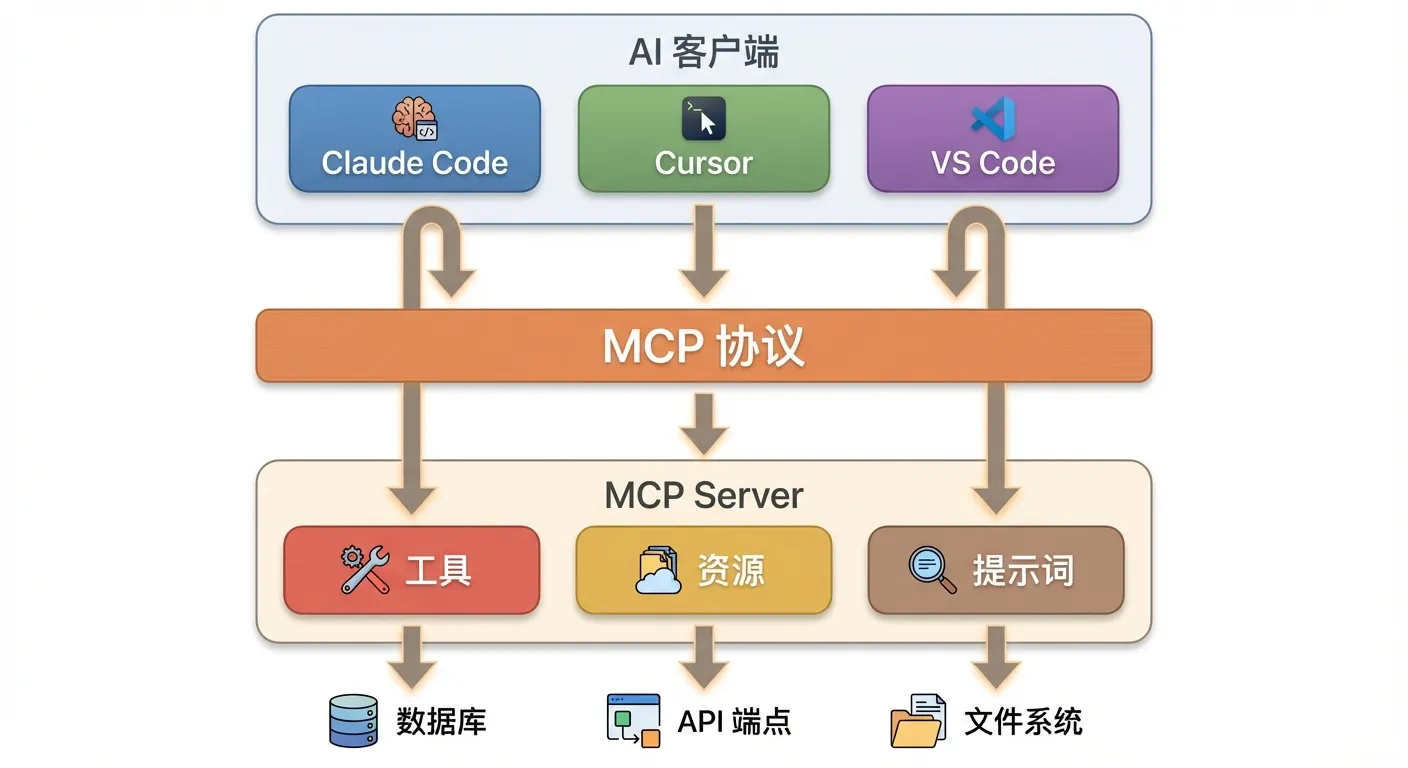
MCP Server 可以提供三种能力:
- Tools:可被 AI 调用的函数(查天气、读数据库、发邮件)
- Resources:可被 AI 读取的数据源(文件内容、配置信息)
- Prompts:预定义的提示词模板
实战:30 行代码搭一个 MCP Server
别看概念一堆,实际写起来极其简单。用 FastMCP 框架,30 行代码就能搞定。
环境准备
# 创建项目
mkdir my-mcp-server && cd my-mcp-server
python3 -m venv .venv && source .venv/bin/activate
# 安装依赖(注意锁版本,v2.0 API 会有破坏性变更)
pip install "mcp[cli]>=1.25,<2"写一个查询 API 余额的 MCP Server
这是我实际在用的一个例子 — 让 AI Agent 能查询各个模型 API 的余额和用量:
# server.py
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("api-balance-checker")
@mcp.tool()
def check_balance(provider: str = "all") -> str:
"""查询 AI API 账户余额和用量统计
Args:
provider: API 提供商名称,支持 openai/anthropic/all
"""
import httpx
# 通过聚合平台一个接口查所有余额
resp = httpx.get(
"https://api.ofox.ai/v1/dashboard/usage",
headers={"Authorization": f"Bearer {get_api_key()}"},
params={"provider": provider}
)
data = resp.json()
lines = ["## API 余额查询结果\n"]
for item in data.get("providers", []):
lines.append(
f"- **{item['name']}**: "
f"余额 ${item['balance']:.2f}, "
f"本月已用 ${item['usage']:.2f}, "
f"调用 {item['calls']} 次"
)
return "\n".join(lines)
@mcp.tool()
def list_models(category: str = "chat") -> str:
"""列出可用的 AI 模型列表
Args:
category: 模型类别 chat/embedding/image/tts
"""
import httpx
resp = httpx.get(
"https://api.ofox.ai/v1/models",
headers={"Authorization": f"Bearer {get_api_key()}"}
)
models = resp.json().get("data", [])
filtered = [m for m in models if category in m.get("type", "")]
lines = [f"## 可用 {category} 模型 ({len(filtered)} 个)\n"]
for m in filtered[:20]:
lines.append(f"- `{m['id']}` — {m.get('description', '无描述')}")
return "\n".join(lines)
def get_api_key():
import os
return os.environ.get("OFOX_API_KEY", "")
if __name__ == "__main__":
mcp.run()接入 Claude Code
# 添加到 Claude Code
claude mcp add api-checker \
--env OFOX_API_KEY=your-key-here \
-- python3 /path/to/server.py
# 验证
claude mcp list接入后在 Claude Code 里直接说「帮我查一下 API 余额」,它就会自动调用你的 MCP Server。
实战案例 2:数据库查询 Server
这个更实用 — 让 AI 直接查数据库,不用你手动写 SQL:
from mcp.server.fastmcp import FastMCP
import sqlite3
mcp = FastMCP("db-query")
DB_PATH = "/path/to/your/database.db"
@mcp.tool()
def query_database(sql: str) -> str:
"""执行 SQL 查询并返回结果(只读,不支持写操作)
Args:
sql: SELECT 查询语句
"""
# 安全检查:只允许 SELECT
if not sql.strip().upper().startswith("SELECT"):
return "❌ 安全限制:只允许 SELECT 查询"
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row
try:
cursor = conn.execute(sql)
rows = cursor.fetchall()
if not rows:
return "查询结果为空"
# 格式化为 Markdown 表格
headers = rows[0].keys()
lines = ["| " + " | ".join(headers) + " |"]
lines.append("| " + " | ".join(["---"] * len(headers)) + " |")
for row in rows[:50]: # 限制返回行数
lines.append("| " + " | ".join(str(row[h]) for h in headers) + " |")
return f"共 {len(rows)} 条结果(显示前 50 条)\n\n" + "\n".join(lines)
finally:
conn.close()
@mcp.resource("schema://tables")
def get_schema() -> str:
"""返回数据库所有表的结构信息"""
conn = sqlite3.connect(DB_PATH)
cursor = conn.execute(
"SELECT name, sql FROM sqlite_master WHERE type='table'"
)
tables = cursor.fetchall()
conn.close()
lines = ["# 数据库表结构\n"]
for name, sql in tables:
lines.append(f"## {name}\n```sql\n{sql}\n```\n")
return "\n".join(lines)
if __name__ == "__main__":
mcp.run()实战案例 3:HTTP 传输模式(远程部署)
前面两个例子用的都是 stdio 模式(本地进程),如果要部署到服务器上给团队共享,需要用 HTTP 传输:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("remote-tools", stateless_http=True)
@mcp.tool()
def search_docs(query: str) -> str:
"""搜索公司内部文档"""
# 你的搜索逻辑
...
# 启动 HTTP Server
if __name__ == "__main__":
mcp.run(transport="streamable-http", host="0.0.0.0", port=8000)客户端连接:
claude mcp add remote-docs --transport http --url https://your-server.com:8000/mcp踩坑记录
分享几个我踩过的坑,可能帮你省点时间:
坑 1:FastMCP 版本问题
MCP Python SDK v2.0 正在开发中,API 会有大改。现在装依赖一定要锁版本:
# ✅ 正确
pip install "mcp[cli]>=1.25,<2"
# ❌ 别这样,会装到 dev 版本
pip install mcp坑 2:环境变量传递
Claude Code 添加 MCP Server 时,环境变量必须用 --env 参数显式传递,不会自动继承你的 shell 环境:
# ✅ 正确
claude mcp add my-server --env API_KEY=xxx -- python3 server.py
# ❌ 这样 server.py 里拿不到 API_KEY
export API_KEY=xxx
claude mcp add my-server -- python3 server.py坑 3:工具描述很重要
MCP 的 tool 描述不是给人看的,是给 AI 看的。描述写得越清晰,AI 调用的准确率越高:
# ❌ AI 不知道什么时候该调用
@mcp.tool()
def do_stuff(x: str) -> str:
"""处理一下"""
...
# ✅ AI 能准确判断使用场景
@mcp.tool()
def check_api_balance(provider: str = "all") -> str:
"""查询 AI API 账户余额和用量。
当用户问到「余额」「花了多少钱」「API 用量」时调用此工具。
Args:
provider: 服务商名称,支持 openai/anthropic/google/all
"""
...坑 4:Streamable HTTP vs SSE
2026 年的 MCP 规范已经从 SSE 迁移到了 Streamable HTTP。如果你看到的教程还在用 sse transport,那是过时的:
# ❌ 旧方案
claude mcp add xxx --transport sse --url ...
# ✅ 新方案
claude mcp add xxx --transport http --url ...哪些 AI 客户端支持 MCP?
截至 2026 年 3 月:
| 客户端 | 支持情况 | 备注 |
|---|---|---|
| Claude Code | ✅ 原生支持 | 体验最好,配置最方便 |
| Claude Desktop | ✅ 支持 | 通过配置文件 |
| Cursor | ✅ 支持 | IDE 集成 |
| VS Code + Continue | ✅ 支持 | 开源方案 |
| OpenClaw | ✅ 支持 | 通过 Skills 机制 |
| ChatGPT | ⚠️ 部分支持 | GPT-5 开始支持 |
基本上主流 AI 开发工具都支持了,写一个 Server 确实能到处用。
小结
MCP 已经从 Anthropic 的内部协议变成了行业标准。如果你在做 AI Agent 开发,现在上车正好 — 生态成熟了,但竞争还没那么卷。
我自己的实践是:把常用的 API 查询、数据库操作、文档搜索都封装成 MCP Server,然后不管用 Claude Code 还是 Cursor 都能直接调用。特别是用聚合 API 平台(比如我一直在用的 ofox.ai)的话,一个 Server 就能管理 50+ 模型的调用和监控,省心不少。
代码都在文章里了,复制就能跑。有问题欢迎评论区交流。