MiniMax M2.5 开源部署指南 + M2.7 免费使用方案(2026 实测)
M2.5 开源到底意味着什么
MiniMax 把 M2.5 开源这件事,在 2026 年初的大模型圈子里算是投了颗石头。
不是那种”开放权重但限制商用”的半吊子开源——M2.5 的完整权重直接放在 HuggingFace 上,256B 总参数,MoE 架构激活 45.9B,协议允许商用,随便下载随便部署。放出来之后,OpenRouter 上的调用量直接冲到第一,超过了一堆闭源模型。
对开发者来说,最直接的问题就两个:我能不能自己部署一套?不部署的话,怎么用最省钱?下面分开聊。
M2.5 的 API 接入方式和基础参数,之前在《MiniMax M2.5 API 接入教程》里写过了。本文重点讲部署和免费使用方案,接入细节不再重复。
自部署 M2.5:硬件门槛和现实考量
先泼盆冷水:M2.5 虽然开源,但不是随便找台机器就能跑的东西。
硬件需求拆解
M2.5 是 MoE 架构,256B 总参数。虽然每次推理只激活 45.9B 参数,但加载模型时所有参数都要进显存。按 FP16 计算:
| 精度 | 显存需求 | 典型配置 | 推理质量 |
|---|---|---|---|
| FP16(全精度) | ~512 GB | 8×A100 80GB | 最佳 |
| INT8 量化 | ~256 GB | 4×A100 80GB | 接近无损 |
| INT4 量化 | ~128 GB | 2×A100 80GB | 有一定损失 |
| GPTQ/AWQ 4bit | ~120 GB | 2×A100 80GB 或 4×RTX 4090 | 取决于量化质量 |
现实情况是:如果你手头没有多卡 GPU 集群,光是硬件成本就已经不太划算了。一台 8×A100 80GB 的服务器,云平台月租在 $15,000 到 $20,000 之间。
推理框架选型
假设硬件已经到位,选什么框架跑推理是第二个关键决策。目前跑 MoE 模型比较成熟的选择:
vLLM — 社区最活跃的选项。对 MoE 架构支持不错,PagedAttention 技术在高并发场景下显存利用率高。M2.5 在 vLLM 上跑得比较稳,社区也有现成的配置参考。
SGLang — 专门为大模型推理设计,支持 tensor parallelism 和 expert parallelism。对 MoE 模型的路由调度做了优化,理论上吞吐量比 vLLM 高一截,但配置门槛也更高。
TGI(Text Generation Inference) — HuggingFace 官方出品,配置最简单,docker pull 就能跑。适合快速验证,生产环境吞吐量不如前两者。
多数团队首选 vLLM,理由简单:够稳,社区资源多,遇到问题容易找到答案。SGLang 吞吐上限更高但调优成本也高,适合有专人维护推理服务的团队。TGI 适合验证阶段快速跑通,生产环境一般不用。
部署后的运维现实
模型跑通了不代表能上生产。MoE 架构的显存占用在不同请求之间波动不小,取决于激活了哪些专家模块,你得盯着 GPU 利用率和显存峰值,设好并发上限,不然 OOM 是迟早的事。
版本更新也是个麻烦。MiniMax 后续大概率会发 M2.5 的微调版,自部署就得自己跟进——下载新权重、跑验证、灰度切换,这套流程每次都要走一遍。
还有个容易低估的点:M2.5 标称支持 1M token 上下文,但长序列推理的显存消耗是非线性增长的。真要处理超长文档,硬件预算得在上面那张表的基础上再翻一番。
所以自部署 M2.5 实际上只适合两类团队——数据合规要求严格到不能出内网的,以及日均处理量超过 5000 万 token、自建确实比买 API 省钱的。不在这两类里的,直接调 API 更理性。
M2.7 的三种免费/低成本使用方案
M2.7 是闭源的,没法自部署。但对多数开发者来说,这反而是好消息——不用折腾硬件,直接调 API 就行。关键是怎么把成本压到最低。
方案一:MiniMax 官方平台免费额度
最直接的路径。MiniMax 的官方平台 platform.minimax.io 对新注册用户赠送免费 token 额度,足够跑通开发测试阶段。
注册流程很简单:国内手机号直接注册,获取 API Key 后就能调用。官方 SDK 和 OpenAI 兼容格式都支持。
优点是直连、延迟最低、不经过任何中间层。缺点是免费额度用完后续费只能走官方定价,而且只能用 MiniMax 一家的模型——如果你的项目同时需要 Claude 或 GPT,得分别管理多个平台账号。
方案二:通过 API 聚合平台调用
这是多数开发者的实际选择。通过 ofox.ai 这类 API 聚合平台,一个 Key 可以同时调用 MiniMax M2.7、Claude、GPT 等几十个模型。
M2.7 在 ofox.ai 上的价格:
| 模型 | 输入价格 | 输出价格 | 上下文窗口 | 最大输出 |
|---|---|---|---|---|
| MiniMax M2.7 | $0.30/M tokens | $1.20/M tokens | 200K | 131K |
| MiniMax M2.7 Highspeed | $0.60/M tokens | $2.40/M tokens | 200K | 131K |
对比一下:Claude Sonnet 4.6 输入 $3、输出 $15——M2.7 便宜了整整十倍。在编码辅助和日常 Agent 任务上,这个差价意味着你可以放心让模型多跑几次,不用心疼 token 消耗。
接入方式也很简单,OpenAI 兼容协议,改一下 base_url 和 model 名就行。model 填 minimax/minimax-m2.7 或 minimax/minimax-m2.7-highspeed。
具体的 API 调用方式和参数配置,参见《MiniMax M2.7 API 教程》。
方案三:OpenClaw 配置 MiniMax 模型
如果你在用 OpenClaw 做开发,可以直接在模型配置里加上 MiniMax。通过 ofox.ai 的 Key 接入后,OpenClaw 里切换模型就是改一行配置的事。
这个方案的好处是日常编码用 M2.7 压成本,遇到复杂任务随时切回 Claude——模型选择在 OpenClaw 里是实时切换的,不需要改代码。
详细的 OpenClaw 配置步骤,之前在《MiniMax OpenClaw + Claude Code 配置教程》里写过。如果你还没配过 OpenClaw,建议先看《OpenClaw 模型配置完全教程》。
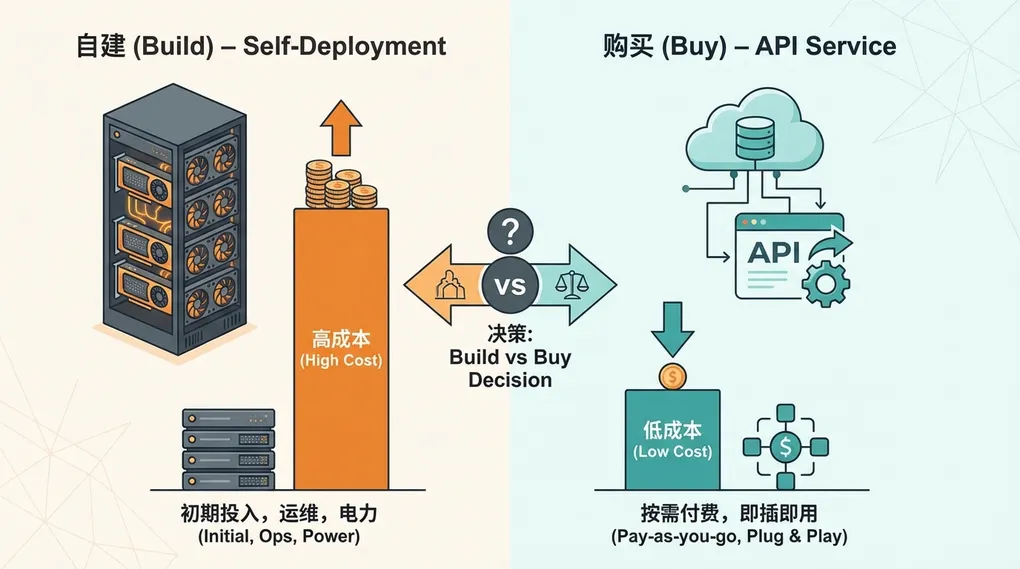
自部署 vs API 调用:成本算笔账
很多人对”开源模型自己部署一定更便宜”有执念。我们来算笔细账。
自部署成本估算
以 4×A100 80GB(INT8 量化)为例,主流云平台月租约 $8,000-10,000。假设满负载跑,月处理量大约:
- 每秒处理约 50-80 个 token(输出)
- 月处理量约 1.3-2 亿 token(输出)
- 换算单价约 $0.04-0.08/千 token(输出)
看起来很便宜?别急,这里面藏着几笔账。
上面的计算假设了 24 小时满负载。实际上哪个团队的调用量没有波峰波谷?夜间和周末利用率可能不到 20%。按平均 40% 利用率算,实际单价直接翻 2.5 倍。
GPU 服务器的运维也不是零成本。模型更新、故障排查、监控报警、显存 OOM 调优,这些都需要人盯着。一个有经验的 MLOps 工程师月薪多少,算进去你就知道了。还有弹性的问题:业务量突然翻倍怎么办?API 平台能自动扩容,自部署需要提前预留资源或者临时加机器,而云平台的 GPU 实例通常不是想加就能加到的。
盈亏平衡点
粗略估算,通过 ofox.ai 调用 M2.7 的日均消耗如果低于 5000 万 token,API 调用的总成本(包括隐性成本)低于自部署。超过这个量级,自部署才开始有经济优势。
5000 万 token 是什么概念?大约等于每天处理 2500 篇万字长文,或者跑 25000 次标准的 Agent 对话。绝大多数创业团队和中小企业远远达不到这个量。
M2.5 和 M2.7 怎么选
这两个模型的差异不只是版本号。
M2.5 的价值在于开源本身:你能下载完整权重、部署在自己的服务器上、完全掌控数据流向。如果你的业务涉及医疗、金融或政务数据,合规部门要求模型不能跑在第三方云上,M2.5 可能是目前参数规模最大的可选项。另外它支持 1M 超长上下文,处理大批量文档有优势。
M2.7 走的是另一条路。闭源,但工具调用和编码能力比 M2.5 强一截,通过 API 调用不用操心硬件。如果你的日常工作是编码辅助、跑 Agent、生成内容,M2.7 配合聚合平台用起来更省心。
有些团队两个都用:核心业务在内网跑自部署的 M2.5,日常开发任务走 API 调 M2.7 和 Claude。这没什么矛盾。但如果你不属于”必须私有化部署”那个群体,不用因为”开源就该自己部署”这个念头给自己加戏。
M2.5 和主流闭源模型的性能对比,参见《MiniMax M2.5 vs Claude Sonnet 4.6 vs GPT-5.4 横评》。M2.7 的 Highspeed 模式详解在《MiniMax M2.7 API 教程》。
写在最后
我在帮几个团队做技术选型的时候发现一个规律:真正需要自部署的团队,在看这篇文章之前就已经在着手准备硬件了。他们的需求很明确,预算也到位。
剩下的多数人,其实是被”开源”两个字吸引过来的。开源当然好,但开源不等于免费——8 张 A100 的月租和一个 MLOps 的工资,加起来够你用 API 跑很久了。M2.7 通过 ofox.ai 调用,输入 $0.30 一百万 token,多数团队一个月花不了几百块。
把省下来的时间和钱花在打磨产品上,比折腾部署环境有意义得多。