多模态 AI API 完全指南:Vision 识图、TTS 语音合成、Whisper 转录一站式接入(2026)
摘要
2026 年,多模态 AI 已从概念变为生产标配——60% 的企业应用已整合两种以上数据模态。本文手把手教你用 OpenAI 兼容协议,一套代码接入 Vision 图片识别、TTS 文字转语音、Whisper 语音转录三大能力,覆盖 GPT-4o、Claude 3.5 Sonnet、Gemini 2.0 三大平台的多模态 API。不用管理三套 SDK,一个 API Key 搞定。
目录
- 问题背景:为什么你需要多模态 API
- Vision API:让 AI 看懂图片
- TTS API:文字转语音实战
- Whisper API:语音转文字最佳实践
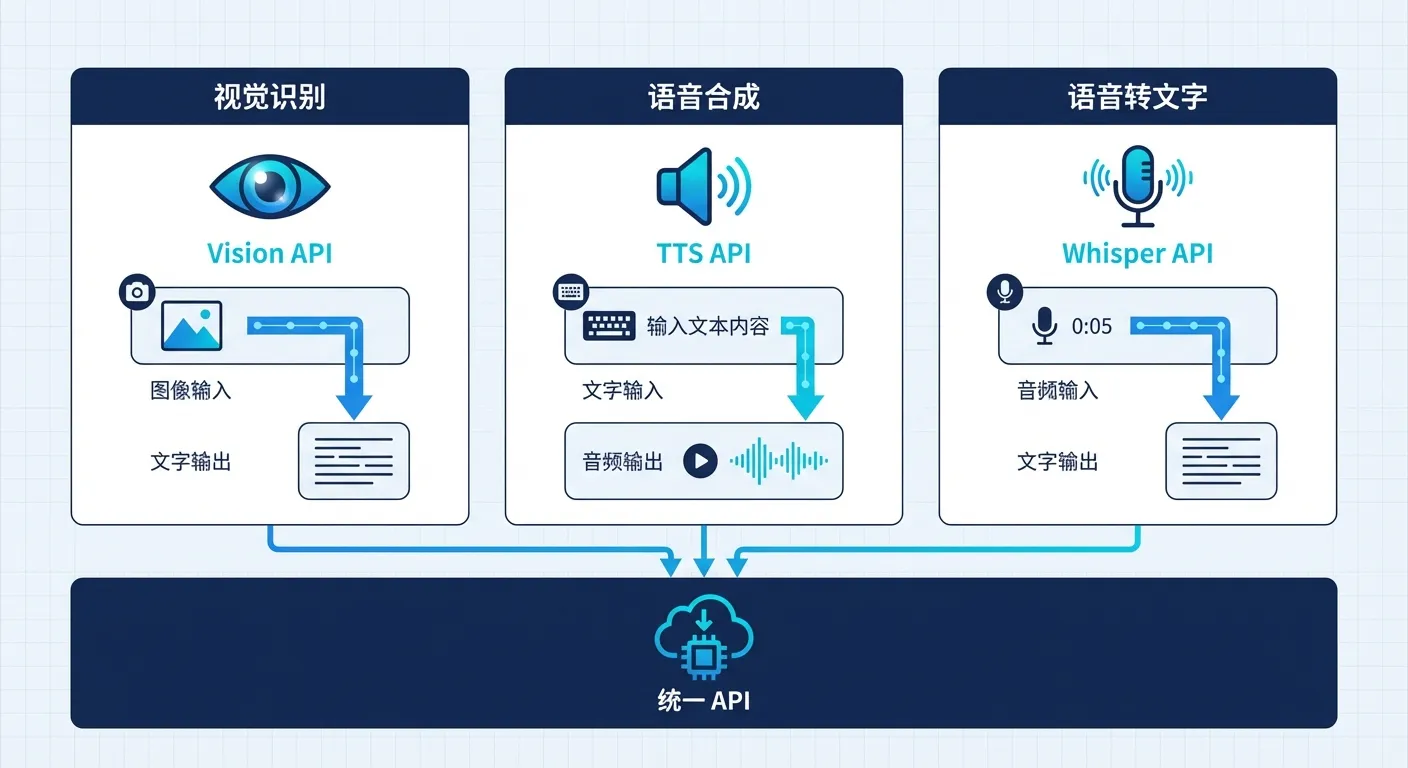
- 统一接入方案:一个 API Key 调所有模态
- 成本对比与选型建议
- 生产级架构:多模态 Pipeline 设计
- 常见问题(FAQ)
- 总结与行动建议
- 参考资料
问题背景:为什么你需要多模态 API
如果你还在用纯文本 API 构建 AI 应用,2026 年的你已经落后了。
根据 Mordor Intelligence 的报告,2026 年多模态 AI 市场规模已达 38.5 亿美元,年复合增长率 28.59%。更关键的数据是:近 60% 的企业应用已经在使用两种以上数据模态(文本 + 图片、文本 + 语音等)。
这意味着什么?你的竞争对手大概率已经在做这些事:
- 客服系统:用户发截图,AI 直接看图诊断问题(Vision API)
- 内容平台:自动给文章生成语音版(TTS API)
- 会议工具:实时转录会议内容,自动生成纪要(Whisper API)
- 电商应用:拍照搜商品、语音下单、图片审核一条龙
问题是,接入这些能力的门槛不低。你需要管理 OpenAI 的 Vision、单独部署 Whisper 实例、对接 ElevenLabs 的 TTS……每个模态一套 SDK、一套鉴权、一套计费。
有没有更简单的方案? 有。往下看。
Vision API:让 AI 看懂图片
Vision API 是多模态中最成熟、应用最广的能力。2026 年主流模型都已原生支持图片输入。
基本调用:一行代码传图
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1" # 兼容 OpenAI 协议
)
response = client.chat.completions.create(
model="gpt-4o", # 也可换成 claude-3.5-sonnet、gemini-2.0-flash
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这张图片里有什么?请详细描述。"},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/photo.jpg"
}
}
]
}
],
max_tokens=1000
)
print(response.choices[0].message.content)传入本地图片(Base64 编码)
实际业务中,更多是用户上传的本地图片:
import base64
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_data = encode_image("screenshot.png")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "分析这张截图中的错误信息,给出解决方案。"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_data}"
}
}
]
}
]
)Vision API 实战场景
| 场景 | 模型推荐 | 说明 |
|---|---|---|
| 通用图片理解 | GPT-4o | 综合能力最强,支持复杂推理 |
| 文档 OCR | Gemini 2.0 Flash | 长文档处理速度快,成本低 |
| UI 截图分析 | Claude 3.5 Sonnet | 对 UI 元素识别精准 |
| 医学影像初筛 | GPT-4o | 需配合专业 prompt 和人工复核 |
| 电商商品识别 | Gemini 2.0 Flash | 性价比最优 |
关键参数与注意事项
- 图片大小:OpenAI 限制单张 20MB,建议压缩到 1MB 以内减少延迟
- 分辨率:
detail: "high"模式会消耗更多 token,按需选择 - 多图输入:GPT-4o 支持单次传入多张图片,适合对比分析
- token 计算:图片 token 按分辨率计算,一张 1024×1024 约消耗 765 token
TTS API:文字转语音实战
TTS(Text-to-Speech)是多模态中增长最快的领域。OpenAI 在 2025 年底推出了 gpt-4o-mini-tts 模型,支持通过 prompt 控制语气、情感和说话风格,效果远超传统 TTS 方案。
基础调用:文字转音频文件
from openai import OpenAI
from pathlib import Path
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
# 基础 TTS:文字转语音
response = client.audio.speech.create(
model="tts-1", # tts-1 速度快,tts-1-hd 质量高
voice="alloy", # 可选:alloy, echo, fable, onyx, nova, shimmer
input="你好,欢迎使用我们的 AI 助手。有什么可以帮你的吗?"
)
# 保存为 MP3
speech_file = Path("output.mp3")
response.stream_to_file(speech_file)
print(f"音频已保存到 {speech_file}")高级用法:控制语气和情感
gpt-4o-mini-tts 模型的杀手特性——可编程语气控制:
# 用 instructions 控制说话风格
response = client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="coral",
input="您的订单已发货,预计明天到达。",
instructions="用温暖友好的语气说话,像客服小姐姐一样亲切自然。"
)这比传统 TTS 的 SSML 标记方便太多了——不用写 XML,用自然语言描述就行。
TTS 模型对比
| 模型 | 延迟 | 音质 | 语气控制 | 价格(每百万字符) |
|---|---|---|---|---|
| tts-1 | ~300ms | 好 | 6 种预设 | $15 |
| tts-1-hd | ~800ms | 极好 | 6 种预设 | $30 |
| gpt-4o-mini-tts | ~400ms | 极好 | 自然语言指令 | $12 |
| ElevenLabs Turbo v2.5 | ~200ms | 极好 | 声音克隆 | $30+ |
实时流式播放
对于对话场景,流式输出避免等待完整音频:
import pyaudio
# 流式 TTS
with client.audio.speech.with_streaming_response.create(
model="tts-1",
voice="alloy",
input="这是一段实时生成的语音,你可以边生成边播放。",
response_format="pcm"
) as response:
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=24000, output=True)
for chunk in response.iter_bytes(1024):
stream.write(chunk)
stream.stop_stream()
stream.close()
p.terminate()Whisper API:语音转文字最佳实践
语音转录是多模态 AI 中 ROI 最高的能力之一。OpenAI 最新的 gpt-4o-mini-transcribe 模型相比 Whisper v2 减少了 90% 的幻觉(空音频时不再生成无关文字),词错率也显著降低。
基础转录
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1"
)
# 打开音频文件进行转录
with open("meeting_recording.mp3", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
language="zh", # 指定语言提升准确率
response_format="verbose_json", # 获取时间戳
timestamp_granularities=["segment"]
)
# 输出转录结果(含时间戳)
for segment in transcript.segments:
start = f"{int(segment.start // 60)}:{int(segment.start % 60):02d}"
print(f"[{start}] {segment.text}")新一代转录模型对比
| 模型 | 词错率 | 幻觉率 | 语言支持 | 价格(每分钟) |
|---|---|---|---|---|
| whisper-1 | 基准 | 基准 | 57 种语言 | $0.006 |
| gpt-4o-transcribe | ↓15% | ↓80% | 57 种语言 | $0.01 |
| gpt-4o-mini-transcribe | ↓12% | ↓90% | 57 种语言 | $0.005 |
gpt-4o-mini-transcribe 是目前性价比最高的选择:比 whisper-1 更准确、更便宜,幻觉减少 90%。
音频处理最佳实践
from pydub import AudioSegment
import io
def transcribe_long_audio(file_path: str, client: OpenAI) -> str:
"""处理超长音频:分段转录再拼接"""
audio = AudioSegment.from_file(file_path)
# Whisper API 限制 25MB,按 10 分钟分段
chunk_length_ms = 10 * 60 * 1000
chunks = [audio[i:i + chunk_length_ms]
for i in range(0, len(audio), chunk_length_ms)]
full_transcript = []
for i, chunk in enumerate(chunks):
# 导出为 MP3 并转录
buffer = io.BytesIO()
chunk.export(buffer, format="mp3")
buffer.name = f"chunk_{i}.mp3"
buffer.seek(0)
result = client.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=buffer,
language="zh"
)
full_transcript.append(result.text)
return "\n".join(full_transcript)语音翻译:一步到位
Whisper API 还支持直接把外语音频翻译成英文:
# 日语音频 → 英文文本
with open("japanese_podcast.mp3", "rb") as audio_file:
translation = client.audio.translations.create(
model="whisper-1",
file=audio_file
)
print(translation.text) # 输出英文翻译统一接入方案:一个 API Key 调所有模态
到这里你可能已经发现问题了:Vision 用 GPT-4o、TTS 用 gpt-4o-mini-tts、转录用 gpt-4o-mini-transcribe……模型这么多,难道要注册三个平台的账号?
不用。 用兼容 OpenAI 协议的 API 聚合网关,一个 API Key 就能调用所有模型的所有模态。
架构对比
传统方案:
你的应用
├── OpenAI SDK → OpenAI API(Vision + TTS + Whisper)
├── Anthropic SDK → Claude API(Vision)
├── Google SDK → Gemini API(Vision + TTS)
└── ElevenLabs SDK → ElevenLabs API(TTS)4 套 SDK、4 个 API Key、4 套计费、4 种错误处理。
聚合网关方案(以 Ofox 为例):
你的应用
└── OpenAI SDK → Ofox API Gateway → 50+ 模型(所有模态)1 套 SDK、1 个 API Key、统一计费、统一错误处理。
代码实现:零改造接入
如果你已经在用 OpenAI SDK,只需改两行:
from openai import OpenAI
# 改这两行就行
client = OpenAI(
api_key="sk-ofox-your-key", # Ofox API Key
base_url="https://api.ofox.ai/v1" # 聚合网关地址
)
# 以下代码完全不用改 ↓
# Vision:用 Claude 看图
response = client.chat.completions.create(
model="claude-3.5-sonnet", # 切模型只改这一行
messages=[{"role": "user", "content": [
{"type": "text", "text": "描述这张图"},
{"type": "image_url", "image_url": {"url": "https://..."}}
]}]
)
# TTS:用 OpenAI 合成语音
speech = client.audio.speech.create(
model="tts-1", voice="nova",
input="语音合成测试"
)
# Whisper:语音转文字
with open("audio.mp3", "rb") as f:
transcript = client.audio.transcriptions.create(
model="whisper-1", file=f
)这种方案的好处:
- 切模型零成本——比较 GPT-4o 和 Claude 的 Vision 效果?改一行 model 参数
- 统一错误处理——不用写 4 套 try/catch
- 成本可控——按量付费,用多少付多少,不用每个平台充最低额度
- 国内低延迟——聚合网关通常有国内节点加速
成本对比与选型建议
各模态成本速算
| 模态 | 模型 | 单价 | 典型用量/月 | 月成本 |
|---|---|---|---|---|
| Vision | GPT-4o | ~$2.5/百万 token | 50 万次识图 | ~$125 |
| Vision | Gemini 2.0 Flash | ~$0.1/百万 token | 50 万次识图 | ~$5 |
| TTS | tts-1 | $15/百万字符 | 100 万字符 | $15 |
| TTS | gpt-4o-mini-tts | $12/百万字符 | 100 万字符 | $12 |
| 转录 | whisper-1 | $0.006/分钟 | 1000 分钟 | $6 |
| 转录 | gpt-4o-mini-transcribe | $0.005/分钟 | 1000 分钟 | $5 |
选型决策树
需要图片理解?
├── 复杂推理(数学题、代码截图)→ GPT-4o
├── 大量文档 OCR → Gemini 2.0 Flash(便宜 25 倍)
└── UI/设计稿分析 → Claude 3.5 Sonnet
需要语音合成?
├── 对话场景(低延迟)→ tts-1
├── 内容场景(高音质)→ tts-1-hd
└── 需要语气控制 → gpt-4o-mini-tts
需要语音转录?
├── 预算敏感 → gpt-4o-mini-transcribe(最便宜+最少幻觉)
├── 需要最高准确率 → gpt-4o-transcribe
└── 简单场景 → whisper-1生产级架构:多模态 Pipeline 设计
以一个典型的「智能客服系统」为例,展示如何组合多模态能力:
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="sk-ofox-your-key",
base_url="https://api.ofox.ai/v1"
)
async def handle_customer_message(message_type: str, content) -> dict:
"""统一处理客户消息:文字、图片、语音"""
if message_type == "voice":
# Step 1: 语音转文字
transcript = await client.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=content
)
user_text = transcript.text
elif message_type == "image":
# Step 1: 图片理解
vision_response = await client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": [
{"type": "text", "text": "用户发了这张图片,识别其中的问题或需求。"},
{"type": "image_url", "image_url": {"url": content}}
]}]
)
user_text = vision_response.choices[0].message.content
else:
user_text = content
# Step 2: AI 理解并生成回复
reply = await client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是智能客服,简洁专业地回答用户问题。"},
{"role": "user", "content": user_text}
]
)
reply_text = reply.choices[0].message.content
# Step 3: 生成语音回复(可选)
speech = await client.audio.speech.create(
model="gpt-4o-mini-tts",
voice="nova",
input=reply_text,
instructions="用温暖友好的客服语气。"
)
return {
"text": reply_text,
"audio": speech.content,
"original_input": user_text
}架构要点
- 异步调用:多模态处理耗时较长,用
AsyncOpenAI避免阻塞 - 模态路由:根据输入类型自动选择处理链路
- 错误降级:Vision 失败时提示用户描述问题,TTS 失败时只返回文字
- 缓存策略:相同图片的识别结果缓存 5 分钟,避免重复调用
常见问题(FAQ)
Q: Vision API 图片识别支持哪些格式?
A: 主流格式都支持——PNG、JPEG、GIF、WebP。GPT-4o 还支持非动画 GIF。建议使用 JPEG 格式,压缩率高、传输快。Base64 和 URL 两种方式传图都可以,URL 方式延迟更低(API 服务器直接下载图片,不需要你上传)。
Q: TTS 文字转语音 API 调用太慢怎么办?
A: 三个优化方向:第一,用 tts-1 而不是 tts-1-hd,延迟从 800ms 降到 300ms;第二,用流式输出(streaming),边生成边播放,用户感知延迟接近零;第三,选择有国内加速节点的 API 网关(如 Ofox 的阿里云/火山云节点),网络延迟可以从 300ms+ 降到 50ms 以内。
Q: Whisper 语音转文字有大小限制吗?
A: 有,单次请求最大 25MB。超过的话需要分段处理——用 pydub 库按 10 分钟一段切割,分别转录后拼接。本文上方的 transcribe_long_audio 函数就是现成的解决方案。
Q: 做 AI 产品用什么接口比较好?
A: 看你的需求复杂度。如果只用一个模型的一种能力,直接调官方 API 最简单。但如果你的产品涉及多个模态(看图 + 对话 + 语音),或者需要在不同模型间切换找最优方案,用聚合网关更省事——一套 SDK 搞定所有模型的所有模态,按量付费,避免每个平台都充值。
Q: Claude 和 GPT 的 Vision 能力选哪个?
A: 各有所长。GPT-4o 在复杂推理和数学题识别上更强,Claude 3.5 Sonnet 在 UI 截图和代码截图的理解上更精准。实际项目建议用同一张测试图跑两个模型对比。用聚合网关的话,切模型只需改一行参数,测试成本几乎为零。
Q: AI API 有什么坑要避开?
A: 几个常见坑:①图片太大导致超时——先压缩到 1MB 以内;②TTS 中文发音不准——指定 language 参数;③Whisper 空音频产生幻觉——升级到 gpt-4o-mini-transcribe,幻觉率降低 90%;④不同平台的错误码不一样——用聚合网关可以统一错误处理逻辑。
总结与行动建议
2026 年,多模态 AI API 已经足够成熟,可以直接用于生产环境。核心要点:
- Vision API 是最成熟的模态,GPT-4o 综合最强,Gemini 2.0 Flash 性价比最高
- TTS API 选
gpt-4o-mini-tts,支持自然语言控制语气,价格还最低 - Whisper 转录选
gpt-4o-mini-transcribe,幻觉最少、性价比最高 - 统一接入:用兼容 OpenAI 协议的聚合网关,一个 Key 调所有模型的所有模态
下一步行动:
- 去 Ofox 开发文档 获取 API Key(注册即有免费额度)
- 用本文的代码示例跑通 Vision + TTS + Whisper 三个 Demo
- 基于你的业务场景,参考「选型决策树」选择最合适的模型组合
- 用异步 + 流式的方式搭建生产级多模态 Pipeline