
OpenClaw 8 大模型实测对比:GPT-5/Claude/Gemini/DeepSeek 谁最强?(2026)
摘要
2026 年 AI 模型百花齐放,OpenClaw 用户面临一个幸福的烦恼:模型太多,到底选哪个?本文对 GPT-5.4、GPT-4o、Claude Opus 4.6、Claude Sonnet 4.6、Gemini 3 Pro、Gemini 3 Flash、DeepSeek V3.2、Qwen3.5 这 8 款主流模型,从推理能力、代码生成、工具调用、响应速度、成本五个维度进行实测打分,给出大横评表格、场景推荐矩阵和性价比排名。不吹不黑,用数据说话。
目录
- 测试方法论
- 8 大模型速览
- 维度一:推理能力
- 维度二:代码生成
- 维度三:工具调用
- 维度四:响应速度
- 维度五:成本
- 五维度大横评总表
- 场景推荐矩阵
- 性价比排名
- OpenClaw 最佳模型配置方案
- 常见问题(FAQ)
- 总结
测试方法论
先说清楚怎么测的,免得被质疑”评分随便编的”。
测试环境
- 平台:OpenClaw v2.4,统一通过 Ofox API 接入所有模型
- 时间:2026 年 3 月
- 网络:国内阿里云节点,排除网络波动干扰
- 温度:统一设为 0,确保结果可复现
评分维度
| 维度 | 权重 | 测试内容 |
|---|---|---|
| 推理能力 | 25% | 数学题、逻辑推理、多步骤分析 |
| 代码生成 | 25% | Python/JS/Go 函数生成、Bug 修复、重构 |
| 工具调用 | 20% | Function Calling 准确率、多工具编排 |
| 响应速度 | 15% | 首 token 延迟、吞吐量 |
| 成本 | 15% | 每百万 token 价格 |
每个维度满分 10 分,最终加权计算综合得分。
测试集
每个维度准备了 30+ 个测试 case,覆盖简单、中等、困难三个档次。不用公开 benchmark(那些早被模型训练数据污染了),用的是实际业务场景构造的测试题。
8 大模型速览
先快速认识一下今天的 8 位选手:
| 模型 | 厂商 | 定位 | 上下文窗口 | 发布时间 |
|---|---|---|---|---|
| GPT-5.4 | OpenAI | 旗舰推理 | 1M tokens | 2026.02 |
| GPT-4o | OpenAI | 性价比多模态 | 128K tokens | 2025.05 |
| Claude Opus 4.6 | Anthropic | 旗舰全能 | 1M tokens | 2026.01 |
| Claude Sonnet 4.6 | Anthropic | 性价比全能 | 200K tokens | 2026.01 |
| Gemini 3 Pro | 旗舰长文本 | 2M tokens | 2026.02 | |
| Gemini 3 Flash | 极速性价比 | 1M tokens | 2026.01 | |
| DeepSeek V3.2 | DeepSeek | 国产性价比之王 | 128K tokens | 2026.01 |
| Qwen3.5 | 阿里云 | 国产全能 | 128K tokens | 2026.02 |
三个梯队一目了然:
- 旗舰梯队:GPT-5.4、Claude Opus 4.6、Gemini 3 Pro——能力天花板,价格也是天花板
- 性价比梯队:GPT-4o、Claude Sonnet 4.6——八成功力、三成价格
- 经济梯队:Gemini 3 Flash、DeepSeek V3.2、Qwen3.5——便宜大碗,日常够用
维度一:推理能力
推理能力决定了模型能不能”想明白”复杂问题。我们测了数学计算、逻辑推理、因果分析、多步骤规划四类题目。
测试结果
| 模型 | 数学计算 | 逻辑推理 | 因果分析 | 多步规划 | 推理总分 |
|---|---|---|---|---|---|
| GPT-5.4 | 9.5 | 9.5 | 9.0 | 9.5 | 9.5 |
| Claude Opus 4.6 | 9.0 | 9.5 | 9.5 | 9.5 | 9.5 |
| Gemini 3 Pro | 9.0 | 8.5 | 8.5 | 8.0 | 8.5 |
| Claude Sonnet 4.6 | 8.0 | 8.5 | 8.5 | 8.0 | 8.0 |
| GPT-4o | 8.0 | 8.0 | 8.0 | 8.0 | 8.0 |
| DeepSeek V3.2 | 8.5 | 8.0 | 7.5 | 7.5 | 8.0 |
| Qwen3.5 | 8.0 | 7.5 | 7.5 | 7.5 | 7.5 |
| Gemini 3 Flash | 7.0 | 7.0 | 7.0 | 6.5 | 7.0 |
关键发现
- GPT-5.4 和 Claude Opus 4.6 并列第一,但各有侧重:GPT-5.4 数学推理更强,Opus 在长链因果推理和多步规划上更稳
- DeepSeek V3.2 数学能力突出(8.5 分),甚至超过 GPT-4o,这跟 DeepSeek 团队在数学推理上的深度优化有关
- Gemini 3 Flash 推理偏弱,复杂逻辑题容易跑偏,但简单推理完全够用
维度二:代码生成
OpenClaw 最常见的用途之一是写代码。测试涵盖函数生成、Bug 修复、代码重构、测试用例编写。
测试结果
| 模型 | 函数生成 | Bug 修复 | 代码重构 | 测试编写 | 代码总分 |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 9.5 | 9.5 | 9.5 | 9.0 | 9.5 |
| GPT-5.4 | 9.5 | 9.0 | 9.0 | 9.0 | 9.0 |
| Claude Sonnet 4.6 | 9.0 | 8.5 | 8.5 | 8.5 | 8.5 |
| Gemini 3 Pro | 8.5 | 8.0 | 8.0 | 8.0 | 8.0 |
| DeepSeek V3.2 | 8.0 | 8.0 | 7.5 | 7.5 | 7.5 |
| GPT-4o | 8.0 | 7.5 | 7.5 | 7.5 | 7.5 |
| Qwen3.5 | 8.0 | 7.5 | 7.0 | 7.5 | 7.5 |
| Gemini 3 Flash | 7.0 | 6.5 | 6.5 | 6.5 | 6.5 |
关键发现
- Claude Opus 4.6 是代码之王,不管是从零生成、还是修 Bug 和重构,代码质量始终最高。它对代码上下文的理解深度明显领先
- Claude Sonnet 4.6 性价比惊人,代码能力 8.5 分,但价格只有 Opus 的五分之一
- DeepSeek V3.2 和 GPT-4o 在代码维度打平,但 DeepSeek 价格低得多
维度三:工具调用
工具调用(Function Calling)是 AI Agent 的核心能力——模型能不能正确理解该调哪个工具、传什么参数、处理返回结果。
测试结果
| 模型 | 单工具调用 | 多工具编排 | 参数准确率 | 错误处理 | 工具总分 |
|---|---|---|---|---|---|
| GPT-5.4 | 10.0 | 9.5 | 9.5 | 9.0 | 9.5 |
| Claude Opus 4.6 | 9.5 | 9.0 | 9.0 | 9.0 | 9.0 |
| Claude Sonnet 4.6 | 9.0 | 8.5 | 8.5 | 8.0 | 8.5 |
| Gemini 3 Pro | 9.0 | 8.5 | 8.0 | 8.0 | 8.5 |
| GPT-4o | 9.0 | 8.0 | 8.5 | 7.5 | 8.0 |
| DeepSeek V3.2 | 8.0 | 7.0 | 7.5 | 7.0 | 7.5 |
| Qwen3.5 | 8.0 | 7.0 | 7.0 | 6.5 | 7.0 |
| Gemini 3 Flash | 7.5 | 6.5 | 7.0 | 6.5 | 7.0 |
关键发现
- GPT-5.4 工具调用最强,OpenAI 在 Function Calling 上的积累确实深厚,参数格式几乎零错误
- Claude 系列紧随其后,尤其在多工具编排(同时调多个工具、根据结果决定下一步)上表现出色
- 国产模型差距明显,DeepSeek V3.2 和 Qwen3.5 在多工具编排上容易出错,遗漏参数或调用顺序混乱。这是国产模型做 AI Agent 时的主要短板
维度四:响应速度
OpenClaw 执行任务时会多轮调用模型,每一轮的延迟都会累积。我们测了首 token 延迟(TTFT)和生成吞吐量(tokens/s)。
测试结果
| 模型 | 首 token 延迟 | 吞吐量 (tokens/s) | 速度评分 |
|---|---|---|---|
| Gemini 3 Flash | ~0.3s | ~180 | 9.5 |
| GPT-4o | ~0.5s | ~120 | 9.0 |
| Claude Sonnet 4.6 | ~0.6s | ~110 | 8.5 |
| DeepSeek V3.2 | ~0.8s | ~100 | 8.0 |
| Qwen3.5 | ~0.8s | ~95 | 8.0 |
| Gemini 3 Pro | ~1.0s | ~80 | 7.5 |
| GPT-5.4 | ~1.5s | ~60 | 6.5 |
| Claude Opus 4.6 | ~1.8s | ~50 | 6.0 |
注:以上数据基于 Ofox 国内加速节点测试,直连海外 API 延迟会更高。
关键发现
- Gemini 3 Flash 速度碾压全场,首 token 0.3 秒、吞吐 180 tokens/s,用它处理简单任务体验极其流畅
- 旗舰模型普遍偏慢,GPT-5.4 和 Claude Opus 4.6 的响应速度是 Flash 级模型的 1/3。复杂任务必须等,但简单任务真没必要用旗舰
- DeepSeek V3.2 速度中等偏上,考虑到它的价格,这个速度已经很能打
维度五:成本
成本直接影响 OpenClaw 的长期使用意愿。统一换算为 $/百万 token(参考各平台官方定价)。
价格对比
| 模型 | 输入价格 ($/M tokens) | 输出价格 ($/M tokens) | 混合成本估算 | 成本评分 |
|---|---|---|---|---|
| Gemini 3 Flash | ~$0.15 | ~$0.60 | 极低 | 10.0 |
| DeepSeek V3.2 | ~$0.27 | ~$1.10 | 极低 | 9.5 |
| Qwen3.5 | 约 $0.40 | 约 $1.20 | 很低 | 9.0 |
| GPT-4o | ~$2.50 | ~$10.00 | 中等 | 7.0 |
| Claude Sonnet 4.6 | ~$3.00 | ~$15.00 | 中等 | 6.5 |
| Gemini 3 Pro | ~$2.50 | ~$10.00 | 中等 | 7.0 |
| GPT-5.4 | ~$10.00 | ~$30.00 | 较高 | 4.5 |
| Claude Opus 4.6 | ~$15.00 | ~$75.00 | 高 | 3.5 |
注:价格参考各厂商 2026 年 3 月官方定价,实际使用中会因缓存命中、批量折扣等有所变化。通过 Ofox 接入时价格与官方基本一致。
关键发现
- Gemini 3 Flash 和 DeepSeek V3.2 是成本之王,价格比旗舰模型低 50-100 倍
- Claude Opus 4.6 最贵,输出价格 $75/M tokens,重度使用一个月轻松上千元。但如果你需要最强代码能力,这笔钱值
- 中间梯队(Sonnet/GPT-4o/Gemini Pro)价格接近,选择更多取决于能力偏好而非价格
五维度大横评总表
终于到了最关键的汇总环节。以下是 8 大模型五个维度的完整评分和加权总分:
| 模型 | 推理 (25%) | 代码 (25%) | 工具 (20%) | 速度 (15%) | 成本 (15%) | 加权总分 |
|---|---|---|---|---|---|---|
| Claude Opus 4.6 | 9.5 | 9.5 | 9.0 | 6.0 | 3.5 | 8.0 |
| GPT-5.4 | 9.5 | 9.0 | 9.5 | 6.5 | 4.5 | 8.0 |
| Claude Sonnet 4.6 | 8.0 | 8.5 | 8.5 | 8.5 | 6.5 | 8.0 |
| GPT-4o | 8.0 | 7.5 | 8.0 | 9.0 | 7.0 | 7.9 |
| Gemini 3 Pro | 8.5 | 8.0 | 8.5 | 7.5 | 7.0 | 8.0 |
| DeepSeek V3.2 | 8.0 | 7.5 | 7.5 | 8.0 | 9.5 | 8.0 |
| Qwen3.5 | 7.5 | 7.5 | 7.0 | 8.0 | 9.0 | 7.7 |
| Gemini 3 Flash | 7.0 | 6.5 | 7.0 | 9.5 | 10.0 | 7.7 |
怎么读这张表:
- 如果你只看能力天花板:Claude Opus 4.6 和 GPT-5.4 并列第一
- 如果你综合考虑性价比:Claude Sonnet 4.6 和 DeepSeek V3.2 是最优解
- 如果你极致省钱:Gemini 3 Flash 成本最低,基本能力也够用
场景推荐矩阵
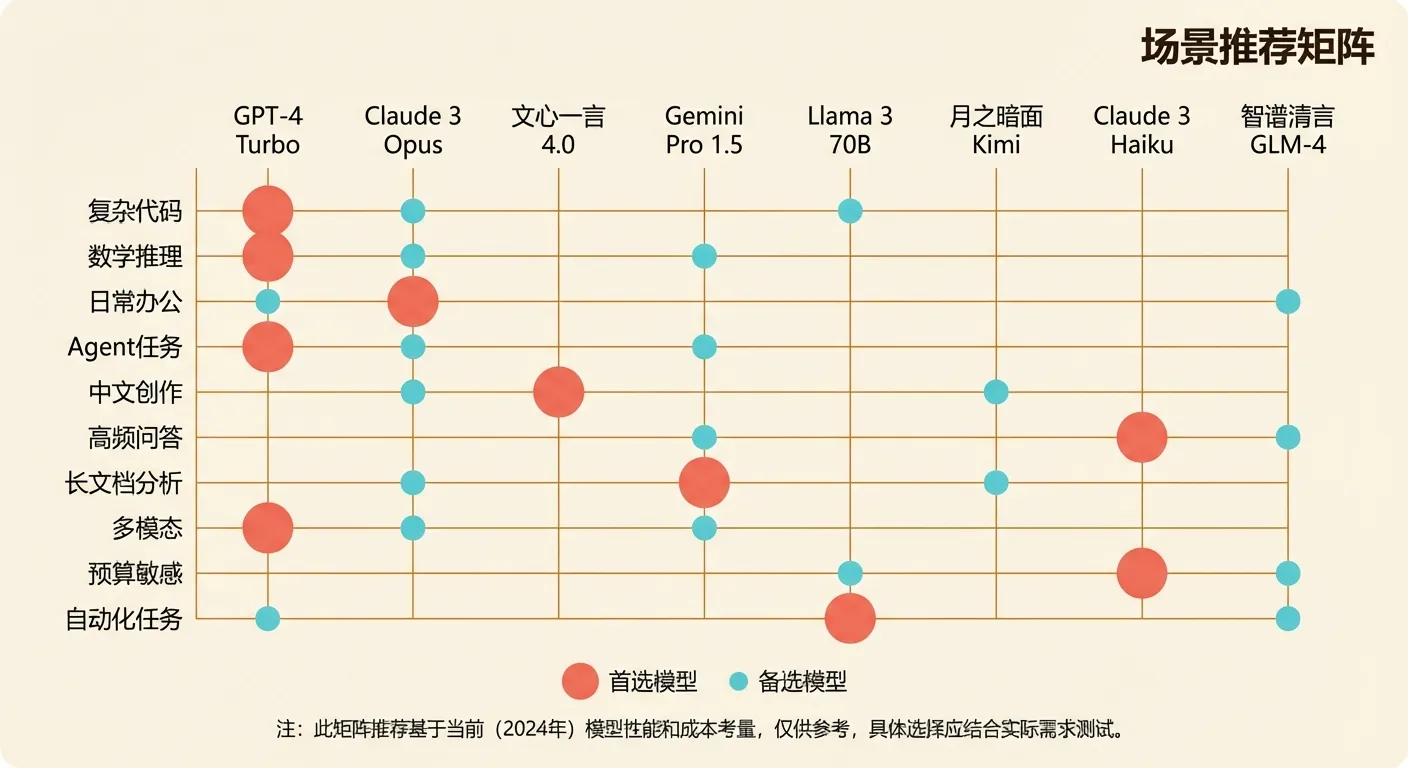
不同场景该用什么模型?直接看表:
| 使用场景 | 首选模型 | 备选模型 | 原因 |
|---|---|---|---|
| 复杂代码生成/重构 | Claude Opus 4.6 | GPT-5.4 | 代码质量最高 |
| 数学/逻辑推理 | GPT-5.4 | Claude Opus 4.6 | 数学推理 GPT 略胜 |
| 日常办公对话 | Claude Sonnet 4.6 | GPT-4o | 能力够、价格合理 |
| 多工具 Agent 任务 | GPT-5.4 | Claude Opus 4.6 | 工具调用最准 |
| 中文内容创作 | DeepSeek V3.2 | Qwen3.5 | 中文理解好、便宜 |
| 高频简单问答 | Gemini 3 Flash | DeepSeek V3.2 | 极快极便宜 |
| 超长文档分析 | Gemini 3 Pro | Claude Opus 4.6 | 200 万 token 上下文 |
| 多模态(图片理解) | GPT-4o | Gemini 3 Pro | 多模态能力最均衡 |
| 预算极度敏感 | DeepSeek V3.2 | Gemini 3 Flash | 价格最低 |
| 7×24 自动化任务 | Claude Sonnet 4.6 | GPT-4o | 稳定、快、不太贵 |
性价比排名
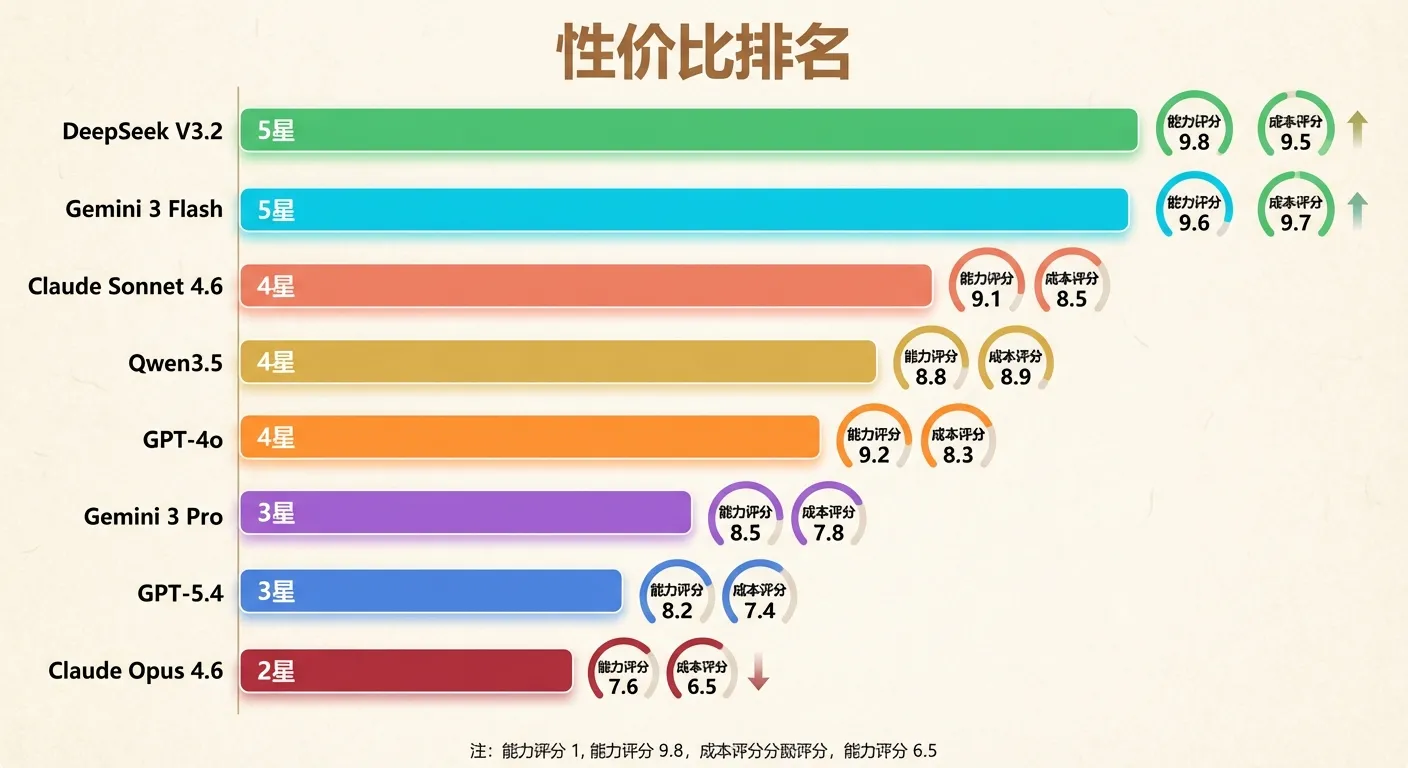
性价比 = 综合能力 / 成本。以下排名考虑了”每花一块钱能买到多少能力”:
| 排名 | 模型 | 能力评分 | 成本评分 | 性价比指数 | 点评 |
|---|---|---|---|---|---|
| 🥇 1 | DeepSeek V3.2 | 7.8 | 9.5 | ★★★★★ | 国产之光,价格是旗舰的 1/50,能力够用 |
| 🥈 2 | Gemini 3 Flash | 7.2 | 10.0 | ★★★★★ | 极致便宜,简单任务的最佳选择 |
| 🥉 3 | Claude Sonnet 4.6 | 8.3 | 6.5 | ★★★★☆ | 中端最强,代码和推理都能打 |
| 4 | Qwen3.5 | 7.5 | 9.0 | ★★★★☆ | 国产全能选手,阿里生态加持 |
| 5 | GPT-4o | 7.9 | 7.0 | ★★★★☆ | OpenAI 经典款,多模态好 |
| 6 | Gemini 3 Pro | 8.1 | 7.0 | ★★★☆☆ | 超长上下文独一份,但贵了点 |
| 7 | GPT-5.4 | 8.5 | 4.5 | ★★★☆☆ | 最强之一,但只在复杂任务上值回票价 |
| 8 | Claude Opus 4.6 | 8.8 | 3.5 | ★★☆☆☆ | 能力天花板,钱包杀手,按需使用 |
结论很明确:不是最贵的就最好。DeepSeek V3.2 和 Gemini 3 Flash 的性价比遥遥领先,80% 的日常任务用它们就够了。旗舰模型留给真正需要的时刻。
OpenClaw 最佳模型配置方案
基于以上测试结果,我给出三套配置方案,覆盖不同预算:
方案一:旗舰配置(月预算 500+ 元)
Primary: Claude Opus 4.6 # 主力模型,代码和推理最强
Secondary: GPT-5.4 # 数学和工具调用备选
Fallback: Claude Sonnet 4.6 # 简单任务降级适合:专业开发者、对代码质量要求高的团队。
方案二:均衡配置(月预算 100-300 元)⭐ 推荐
Primary: Claude Sonnet 4.6 # 日常主力,能力全面
Secondary: GPT-4o # 多模态任务
Economy: DeepSeek V3.2 # 简单任务省钱
Fallback: Gemini 3 Flash # 兜底,永不掉线适合:大多数开发者和团队,平衡能力与成本。
方案三:经济配置(月预算 100 元以内)
Primary: DeepSeek V3.2 # 主力,便宜能打
Secondary: Qwen3.5 # 中文任务补充
Fallback: Gemini 3 Flash # 极简任务兜底适合:个人用户、预算敏感、以中文任务为主。
以上所有模型都可以通过 Ofox 一个接口调用——注册一个账号、拿一个 API Key,在 OpenClaw 配置里填上 https://api.ofox.ai/v1 作为 base_url,就能在这些模型间自由切换。不用分别注册 OpenAI、Anthropic、Google、DeepSeek 四个平台,也不用操心海外支付问题。
常见问题(FAQ)
OpenClaw 用什么模型最好?
没有绝对最好,取决于你的场景。综合能力最强是 Claude Opus 4.6 和 GPT-5.4,性价比最高是 DeepSeek V3.2,速度最快是 Gemini 3 Flash。建议参考本文的场景推荐矩阵选择。
国产模型做 AI Agent 够用吗?
日常任务够用,但工具调用能力是短板。DeepSeek V3.2 和 Qwen3.5 在单工具调用上已经不错,但多工具编排和复杂参数构造上跟 GPT/Claude 还有差距。建议国产模型做主力省钱,复杂 Agent 任务切换到 GPT/Claude。
这些模型在哪里能一起用?
通过 API 聚合平台可以一个接口调用所有模型。Ofox 支持本文测试的全部 8 个模型以及 100+ 其他模型,使用统一的 OpenAI 兼容协议,配置一次即可。
评分和公开 benchmark 为什么不一样?
公开 benchmark(如 MMLU、HumanEval)的测试集已被广泛用于模型训练,存在数据污染问题。本文使用自建的实际业务场景测试集,更能反映真实使用体验。分数仅代表 OpenClaw Agent 场景下的表现,不是通用能力排名。
多久需要更新模型选择?
建议每 3-6 个月重新评估。AI 模型迭代非常快,2025 年的王者到 2026 年可能已经被超越。通过聚合平台切换模型只需改一个参数,成本极低。
总结
8 个模型测下来,核心结论就三条:
- 能力天花板:Claude Opus 4.6(代码最强)和 GPT-5.4(推理和工具调用最强)并列,但价格也是最高的
- 日常最优解:Claude Sonnet 4.6 综合能力最均衡,配合 DeepSeek V3.2 做经济兜底,是大多数 OpenClaw 用户的最佳组合
- 别只用一个模型:混合策略能让你在不牺牲体验的前提下降低 60-70% 的成本
最后一个实操建议:通过 Ofox 这样的聚合平台接入,可以用一个 API Key 在这 8 个模型之间自由切换,省去了分别注册、管理、支付的麻烦。先用免费额度跑通流程,找到最适合自己的模型组合,再考虑长期投入。
模型在不断进化,半年后这份排名大概率会变。但选模型的方法论不会变:先明确场景,再看能力,最后算成本。