如何降低 AI API 成本?7 个实测有效的优化策略(2026)
摘要
AI API 成本优化的核心思路:用对模型、写好 Prompt、善用缓存。本文 7 个策略组合使用,实测可将月度 API 账单降低 60-80%。最见效的三板斧是:模型分级(省 40-60%)、Prompt 缓存(省 50-90%)、Batch API(省 50%)。
目录
- 2026 年主流 AI 模型价格全览
- 策略一:按任务复杂度选择模型
- 策略二:Prompt 精简——少一个 Token 就是少一分钱
- 策略三:Prompt 缓存——重复上下文只付一次钱
- 策略四:Batch API——离线任务享半价
- 策略五:设置 Token 预算和自动截断
- 策略六:用聚合平台灵活切换最优模型
- 策略七:监控分析,持续优化
- 实战案例:月费从 $2000 降到 $400
- 常见问题(FAQ)
- 总结与行动建议
- 参考资料
2026 年主流 AI 模型价格全览
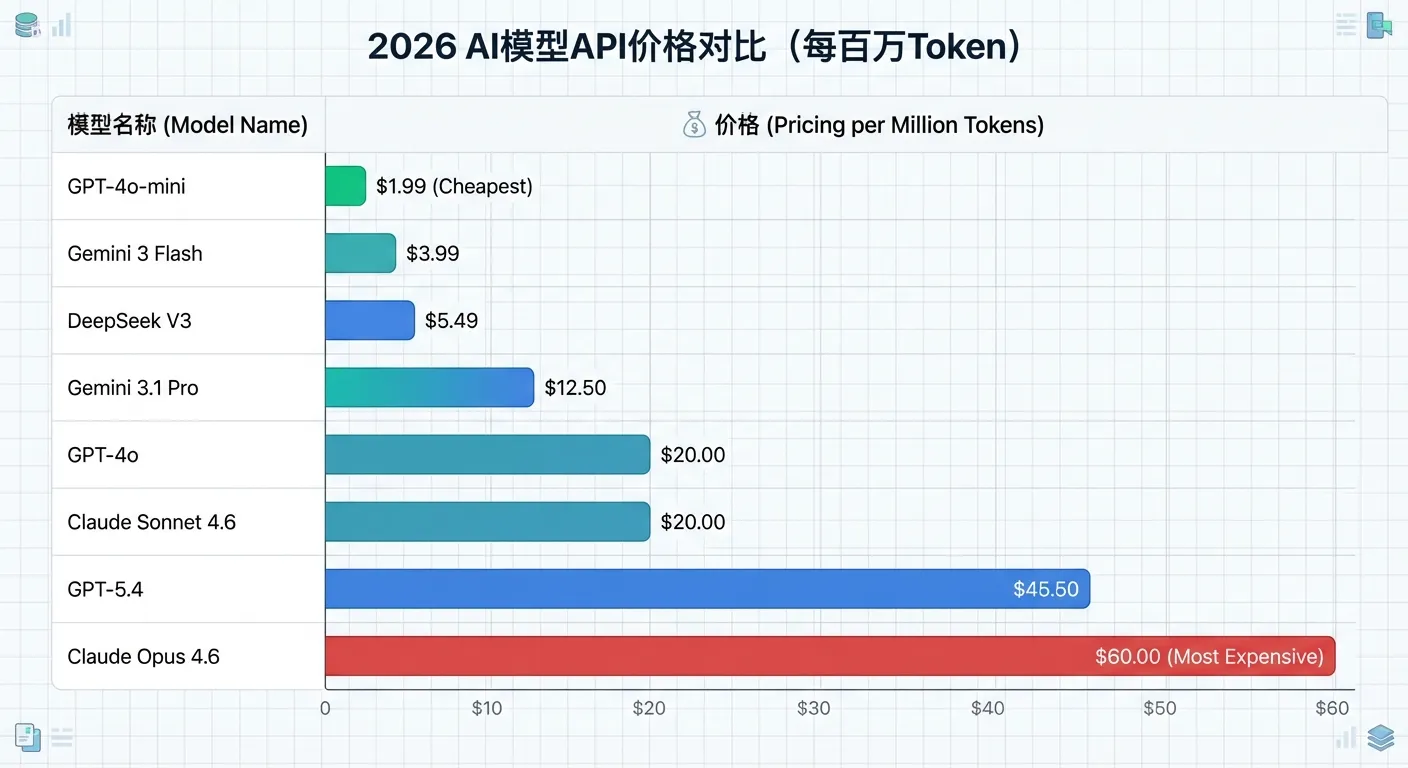
做成本优化之前,先搞清楚现在各家模型到底要多少钱。以下是 2026 年 3 月的最新定价(单位:美元/百万 token):
| 模型 | 输入价格 | 输出价格 | 上下文窗口 | 定位 |
|---|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 128K | OpenAI 主力模型 |
| GPT-4o-mini | $0.15 | $0.60 | 128K | 轻量高性价比 |
| GPT-5.4 | $2.50 | $15.00 | 128K | OpenAI 最新旗舰 |
| Claude Opus 4.6 | $5.00 | $25.00 | 200K | Anthropic 旗舰 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 200K | 编程性价比之王 |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K | 轻量快速 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 200K | Google 旗舰 |
| Gemini 3 Flash | $0.50 | $3.00 | 1M | 超高性价比 |
| DeepSeek V3 | $0.27 | $1.10 | 64K | 国产价格杀手 |
一个直观的算法:如果你的应用每天处理 1000 次对话,每次平均 2000 input token + 500 output token,那么:
- 用 GPT-4o:$(2000 × 2.50 + 500 × 10.00) / 1,000,000 × 1000 × 30 = $300/月
- 用 GPT-4o-mini:$(2000 × 0.15 + 500 × 0.60) / 1,000,000 × 1000 × 30 = $18/月
差了 16 倍。选错模型就是在烧钱。
策略一:按任务复杂度选择模型
这是降本效果最显著的策略——不是所有任务都需要最强模型。
模型分级方案
┌─────────────────────────────────────────────────┐
│ Level 3(旗舰):Opus 4.6 / GPT-5.4 │
│ 复杂推理、多步规划、高精度代码生成 │
│ 成本:$$$ │
├─────────────────────────────────────────────────┤
│ Level 2(主力):Sonnet 4.6 / GPT-4o │
│ 日常编程、文案撰写、数据分析 │
│ 成本:$$ │
├─────────────────────────────────────────────────┤
│ Level 1(轻量):Haiku 4.5 / GPT-4o-mini │
│ 分类、摘要、简单问答、格式转换 │
│ 成本:$ │
└─────────────────────────────────────────────────┘代码实现:自动路由到合适模型
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.ofox.ai/v1" # 聚合平台,一个 Key 用所有模型
)
# 按任务复杂度自动选模型
MODEL_ROUTER = {
"classify": "openai/gpt-4o-mini", # 分类任务 → 最便宜
"summarize": "openai/gpt-4o-mini", # 摘要 → 最便宜
"chat": "anthropic/claude-sonnet-4-6", # 对话 → 主力
"code": "anthropic/claude-sonnet-4-6", # 编程 → 主力
"reasoning": "anthropic/claude-opus-4-6", # 复杂推理 → 旗舰
}
def smart_complete(task_type: str, prompt: str, **kwargs):
"""根据任务类型自动选择最优模型"""
model = MODEL_ROUTER.get(task_type, "openai/gpt-4o-mini")
return client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**kwargs
)
# 简单分类 → GPT-4o-mini,几乎不花钱
result = smart_complete("classify", "这条评论是正面还是负面:'这个产品太好用了'")
# 代码生成 → Sonnet 4.6,性价比最优
result = smart_complete("code", "写一个 Python 函数实现 LRU Cache")降本效果:假设 60% 的请求是简单任务,从全部使用 GPT-4o 改为分级路由后,成本降低约 50%。
策略二:Prompt 精简——少一个 Token 就是少一分钱
大部分开发者的 system prompt 都写得太长了。精简 Prompt 不只省钱,还能提升响应速度。
对比示例
优化前(约 180 token):
你是一个专业的客服助手。你需要帮助用户解决他们遇到的各种问题。
在回答用户问题的时候,你需要保持礼貌和耐心。如果用户的问题
你无法回答,请礼貌地告知他们。你需要使用中文来回答所有的问题。
请确保你的回答准确、简洁、有帮助。不要回答与客服无关的问题。优化后(约 50 token):
角色:中文客服助手
规则:1)简洁准确回答 2)不确定时坦诚说明 3)只处理客服相关问题效果一样,Token 减少了 70%。
实用技巧
- 去掉冗余修饰:「你需要帮助用户解决」→ 直接给指令
- 用列表替代段落:结构化指令比自然语言更短
- 动态上下文:只传必要的上下文,别把整个对话历史都塞进去
def trim_conversation(messages, max_turns=10):
"""只保留最近 N 轮对话,避免上下文无限膨胀"""
system_msgs = [m for m in messages if m["role"] == "system"]
history = [m for m in messages if m["role"] != "system"]
return system_msgs + history[-(max_turns * 2):]策略三:Prompt 缓存——重复上下文只付一次钱
这是 2026 年最值得用的降本特性。如果你的请求里有大段重复的 system prompt 或上下文,缓存能帮你省 50-90% 的输入成本。
各平台缓存机制对比
| 平台 | 缓存方式 | 缓存命中折扣 | 写入成本 | 有效期 |
|---|---|---|---|---|
| Anthropic | Prompt Caching | 90% off(0.1x) | 1.25x(5分钟)/ 2x(1小时) | 5分钟或1小时 |
| OpenAI | Automatic Caching | 50% off(0.5x) | 无额外费用 | 约5-10分钟 |
| Context Caching | 75% off(0.25x) | 按时长计费 | 自定义 |
Anthropic Prompt Caching 实战
import anthropic
client = anthropic.Anthropic()
# 把大段系统提示标记为可缓存
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "你是 XX 公司的智能客服...(此处省略 2000 字的产品知识库)",
"cache_control": {"type": "ephemeral"} # 标记缓存
}
],
messages=[{"role": "user", "content": "你们的退货政策是什么?"}]
)
# 查看缓存效果
print(f"缓存命中 token: {response.usage.cache_read_input_tokens}")
print(f"缓存写入 token: {response.usage.cache_creation_input_tokens}")真实案例:一位开发者将 system prompt(约 4000 token)标记为缓存,客服系统月费从 $720 降到 $72,节省 90%。
OpenAI 自动缓存
OpenAI 的缓存更简单——完全自动,不需要代码改动:
from openai import OpenAI
client = OpenAI()
# OpenAI 会自动缓存相同前缀的请求
# 连续多次调用相同 system prompt 时自动生效
for question in user_questions:
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": long_system_prompt}, # 自动缓存
{"role": "user", "content": question}
]
)
# 缓存命中时,输入价格自动减半策略四:Batch API——离线任务享半价
如果你有不需要实时返回的批量任务,Batch API 直接打五折。
适用场景
- 批量内容生成(产品描述、SEO 文章)
- 数据标注和分类
- 文档摘要提取
- 翻译任务
- 模型评测和 benchmark
OpenAI Batch API 示例
import json
from openai import OpenAI
client = OpenAI()
# 1. 准备批量请求文件(JSONL 格式)
requests = []
for i, text in enumerate(texts_to_summarize):
requests.append({
"custom_id": f"summary-{i}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "用一句话总结以下内容"},
{"role": "user", "content": text}
],
"max_tokens": 200
}
})
# 保存为 JSONL
with open("batch_input.jsonl", "w") as f:
for req in requests:
f.write(json.dumps(req) + "\n")
# 2. 上传文件
batch_file = client.files.create(
file=open("batch_input.jsonl", "rb"),
purpose="batch"
)
# 3. 创建批处理任务
batch_job = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h" # 24 小时内完成
)
# 4. 等待完成后获取结果
# 成本:标准价格的 50%
print(f"批处理任务 ID: {batch_job.id}")降本效果:1000 篇文档摘要任务,标准 API 费用 $25,Batch API 只要 $12.5。
策略五:设置 Token 预算和自动截断
没有预算控制的 API 调用就像没有限速的高速公路——迟早出事。
max_tokens 控制
# 明确限制输出长度,避免模型"话痨"
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "简要介绍量子计算"}],
max_tokens=300, # 限制输出
temperature=0.3 # 低温度 = 更短更精确的输出
)月度预算告警
import os
class BudgetTracker:
"""简易 API 预算追踪器"""
def __init__(self, monthly_budget_usd=100):
self.budget = monthly_budget_usd
self.spent = 0.0
def track(self, input_tokens, output_tokens, model="gpt-4o"):
# 各模型单价(美元/token)
pricing = {
"gpt-4o": {"input": 2.5e-6, "output": 10e-6},
"gpt-4o-mini": {"input": 0.15e-6, "output": 0.6e-6},
"claude-sonnet-4-6": {"input": 3e-6, "output": 15e-6},
}
p = pricing.get(model, pricing["gpt-4o"])
cost = input_tokens * p["input"] + output_tokens * p["output"]
self.spent += cost
if self.spent > self.budget * 0.8:
print(f"⚠️ 已用 ${self.spent:.2f},接近月预算 ${self.budget}")
return cost
tracker = BudgetTracker(monthly_budget_usd=200)策略六:用聚合平台灵活切换最优模型
当你需要在不同模型之间灵活切换时,API 聚合平台的价值就体现出来了。不用对接多个 API、不用管理多把 Key,一个接口用所有模型。
聚合平台的降本优势
- 一键切模型:发现 Gemini 3 Flash 对你的场景够用?改一行 model 参数就行
- 避免供应商锁定:某家涨价了随时切走
- 统一监控:所有模型的用量一目了然,及时发现异常
- 额外优惠:部分平台提供注册送额度、按量付费、无月费
代码示例:通过 Ofox 聚合平台调用多模型
from openai import OpenAI
# 一个 base_url,一个 API Key,调用所有模型
client = OpenAI(
api_key="your-ofox-api-key",
base_url="https://api.ofox.ai/v1"
)
# 用 GPT-4o-mini 做分类(最便宜)
classify_result = client.chat.completions.create(
model="openai/gpt-4o-mini",
messages=[{"role": "user", "content": "分类这封邮件:投诉/咨询/表扬"}]
)
# 用 Claude Sonnet 写代码(性价比最佳)
code_result = client.chat.completions.create(
model="anthropic/claude-sonnet-4-6",
messages=[{"role": "user", "content": "实现一个 rate limiter"}]
)
# 用 Gemini 3 Flash 做大批量处理(超便宜 + 1M 上下文)
summary = client.chat.completions.create(
model="google/gemini-3-flash",
messages=[{"role": "user", "content": f"总结这篇长文:{long_document}"}]
)完整的接入文档可参考 Ofox 开发者文档。兼容 OpenAI 协议意味着现有代码只需改两行(base_url 和 api_key)就能接入。
策略七:监控分析,持续优化
降本不是一次性的事情,需要持续监控和迭代。
关键指标
| 指标 | 说明 | 优化方向 |
|---|---|---|
| 平均 Token/请求 | 每次请求的 Token 消耗 | Prompt 精简 |
| 缓存命中率 | 缓存生效的比例 | 优化缓存策略 |
| 模型利用率 | 各模型的使用占比 | 调整路由规则 |
| 单次请求成本 | 平均每次调用花多少钱 | 综合优化 |
| 月度趋势 | 费用增长曲线 | 预算预警 |
日志分析脚本
import json
from collections import defaultdict
def analyze_api_usage(log_file):
"""分析 API 使用日志,找出优化点"""
stats = defaultdict(lambda: {"calls": 0, "tokens": 0, "cost": 0})
with open(log_file) as f:
for line in f:
entry = json.loads(line)
model = entry["model"]
tokens = entry["total_tokens"]
cost = entry["cost"]
stats[model]["calls"] += 1
stats[model]["tokens"] += tokens
stats[model]["cost"] += cost
print("📊 API 使用分析报告")
print("-" * 60)
for model, data in sorted(stats.items(), key=lambda x: -x[1]["cost"]):
avg_tokens = data["tokens"] / data["calls"]
print(f"{model}:")
print(f" 调用次数: {data['calls']}")
print(f" 平均 Token: {avg_tokens:.0f}")
print(f" 总费用: ${data['cost']:.2f}")
print()实战案例:月费从 $2000 降到 $400
某 SaaS 团队的 AI 功能优化前后对比:
优化前:
- 所有请求统一使用 GPT-4o
- system prompt 约 3000 token,每次请求都发送
- 无缓存、无批处理
- 月费用:$2000
优化措施:
| 步骤 | 措施 | 节省比例 |
|---|---|---|
| 1 | 60% 简单任务切换到 GPT-4o-mini | -45% |
| 2 | system prompt 精简到 800 token | -15% |
| 3 | 开启 Prompt 缓存 | -20% |
| 4 | 数据报表改用 Batch API | -10% |
| 5 | 设置 max_tokens 限制输出 | -5% |
优化后月费用:约 $400,整体降低 80%。
关键是这五步的优先级:先做模型分级(效果最大、改动最小),再做缓存,最后做精细优化。
常见问题(FAQ)
Q:用便宜的模型会不会影响效果?
不会,前提是任务匹配。GPT-4o-mini 在分类、摘要、格式转换等任务上的准确率与 GPT-4o 相差不到 3%,但成本差了 16 倍。关键是做好任务分级,而不是一刀切。
Q:Prompt 缓存有什么限制?
Anthropic 的缓存要求至少 1024 token(Haiku 为 2048),且缓存有时效性(5 分钟或 1 小时)。OpenAI 的自动缓存要求前缀至少 1024 token 完全一致。频繁变动的 prompt 不适合缓存。
Q:如何估算 Token 数量?
中文大约 1 个汉字 ≈ 1.5-2 个 token,英文大约 1 个单词 ≈ 1-1.5 个 token。OpenAI 提供 Tokenizer 工具 可精确计算。
Q:按量付费和包月哪个更划算?
日调用量稳定且较高时包月更划算,波动大或处于测试阶段时按量付费更灵活。大部分 API 聚合平台(如 Ofox)采用按量付费模式,用多少算多少,没有月费门槛。
总结与行动建议
AI API 成本优化不需要复杂的架构改造,从今天就可以开始:
- 今天就做:审计当前 API 用量,识别哪些请求在用”大炮打蚊子”
- 本周完成:实现模型分级路由,把简单任务切到轻量模型
- 下周推进:开启 Prompt 缓存,精简 system prompt
- 持续迭代:建立监控看板,每月复盘优化效果
如果你还在为多个模型分别管理 API Key 和对接代码而头疼,可以试试 Ofox 聚合平台——一个接口接入 100+ 模型,按需切换,中国区阿里云/火山云加速直连。
参考资料
- OpenAI API Pricing — OpenAI 官方定价页
- Claude API Pricing — Anthropic 官方定价
- Anthropic Prompt Caching 文档 — 缓存配置指南
- OpenAI Batch API Guide — 批处理 API 官方文档
- Vertex AI Pricing — Google Gemini 定价
- LLM API Pricing Comparison — 300+ 模型价格实时对比
- Ofox 开发者文档 — 聚合平台接入指南