Claude Opus 4.8 登場:ベンチマーク、Fast Mode、本当に変わった点
Claude Opus 4.8 は 2026 年 5 月 28 日にリリース。価格は 4.7 と同額のまま、独立系の GDPval-AA 実務リーダーボードで 1890 Elo を獲得し首位に。SWE-bench Pro 69.2%、新しい Fast Mode、dynamic workflows、そして ofox.ai 経由のアクセス方法までを整理する。

TL;DR — Anthropic は 2026 年 5 月 28 日に Claude Opus 4.8 をリリース。価格は 4.7 と同じ $5/$25。Artificial Analysis の GDPval-AA 実務リーダーボードで 1890 Elo を獲得して首位(GPT-5.5 比 +121、4.7 比 +137)、SWE-bench Pro は 69.2%、しかも同じタスクの出力トークンが 4.7 より約 35% 少ない——性能が上がって運用も安い。今回の新機能は Fast Mode(出力 2.5 倍速)、会話途中の system メッセージ、Claude Code の dynamic workflows。Anthropic はこれを「最も正直なモデル」とも称している。
今回リリースされたもの
Claude Opus 4.8 は 2026 年 5 月 28 日に公開された。GPT-5.5(4 月 23 日リリース)がリーダーボードの頂点を塗り替えてから約 5 週間後のことだ。モデル ID は claude-opus-4-8。Claude API ではデフォルトで完全な 1M トークンのコンテキストウィンドウ(Microsoft Foundry は 200K)、最大出力 128K トークンを備え、予算計画上重要な点として 表示価格は Opus 4.7 と完全に同額(入力 $5、出力 $25 / 100 万トークン) だ。
今回の主役は値下げでもコンテキスト拡張でもない。Opus 4.8 が、実務エージェントタスクで GPT-5.5 世代と明確に差をつけた最初のモデルであり、しかもそれをより少ないトークンで達成している点だ。
GDPval-AA の結果
最も注目すべき数字は Anthropic 発ではなく、独立評価機関 Artificial Analysis によるものだ。彼らの GDPval-AA リーダーボードは、実際の経済的価値を持つタスク(OpenAI の GDPval データセット、9 産業・44 職種)でモデルを採点する。各モデルにシェルアクセスと Web ブラウジングを与え、オープンソースの Stirrup ハーネスでエージェントループとして動かし、ブラインドのペア比較から Elo を導出する。
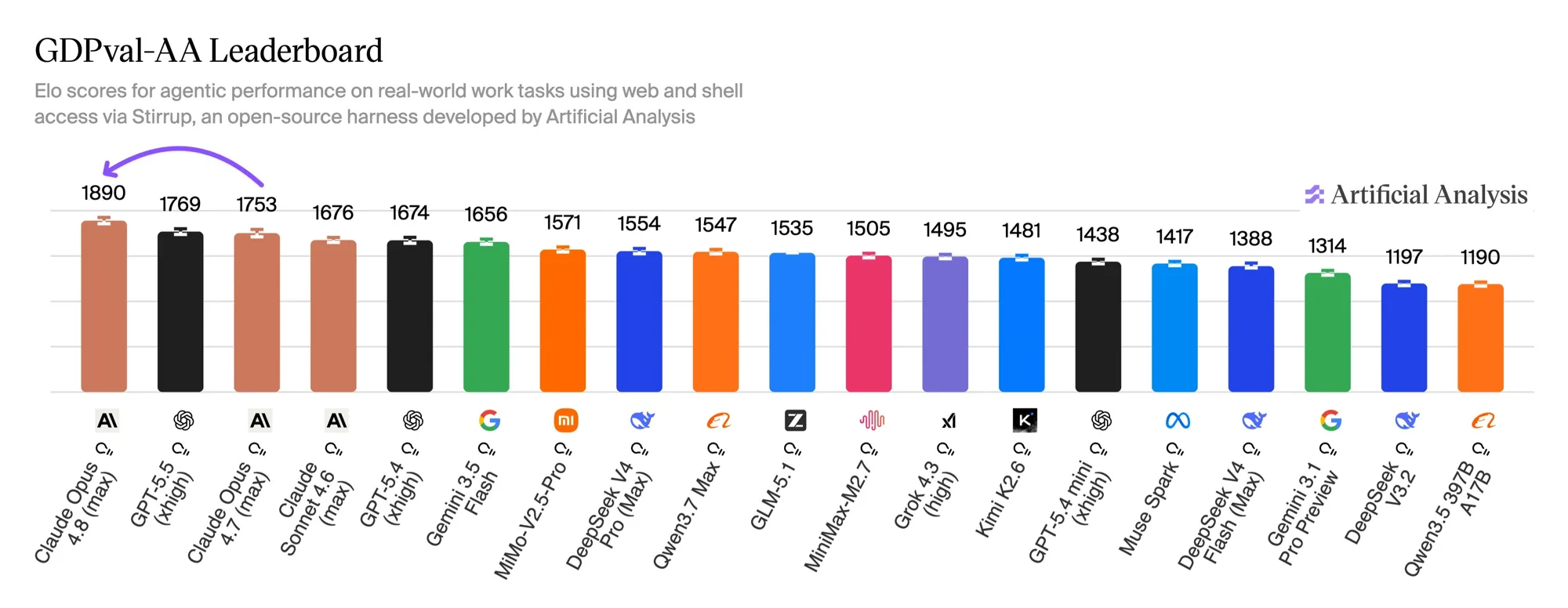
Opus 4.8(max effort)は 1890 Elo でデビュー首位、2 位の GPT-5.5 に 121 点差、前世代に +137 点。この差は GPT-5.5(xhigh)に対する暗黙の勝率にしておよそ 67% に相当する。トップ 4 のうち 3 つが Claude モデルだ。
単なるベンチマークの百分率より信頼できる点がある。Artificial Analysis によれば、Opus 4.8 はこのスコアを タスクあたりのターン数 4.7 比 15% 減・出力トークン 35% 減 で達成している。代償として、同じタスクの完了に GPT-5.5 より約 30% 多くのターンを要する——Opus は動く前により多く考える。出力トークンが請求の大半を占めるエージェントパイプラインでは、「少ないトークンで高い勝率」という組み合わせこそが月次請求額を実際に動かす。
同世代フラッグシップとの比較
Anthropic 自社の数字は、コーディングとコンピュータ操作で独立結果と一致する。ただし正直に挙げるべき例外が 1 つある。
| ベンチマーク | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| OSWorld-Verified(コンピュータ操作) | 83.4% | 82.8% | 78.7% | 76.2% |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| Humanity’s Last Exam(ツールあり) | 57.9% | — | — | — |
| Finance Agent v2 | 53.9% | — | — | — |
| GDPval-AA(Elo) | 1890 | 1753 | 1769 | — |
SWE-bench Pro は合成タスクではなく実在の OSS リポジトリを使う。その 69.2% は、前世代の同クラス最強だった Opus 4.7 を 5 ポイント近く上回る。OSWorld-Verified(実際のデスクトップ操作)は、Opus が以前から着実に首位を保ってきた領域だ。
挙げておくべき例外:Terminal-Bench 2.1 は依然 GPT-5.5 が勝つ(78.2% vs 74.6%)。生のターミナルコマンド列が中心のワークロードなら、これは誤差ではなく、実際に出ている差だ。とはいえ大半のエージェント系コーディング——複数ファイルのリファクタ、長時間の自律実行、リポジトリ全体のタスク——では Opus 4.8 が現時点で最強の選択肢だ。
API レベルの新機能
スコア以外に、Opus 4.8 上で開発する人にとって重要な API レベルの変更が 4 つある。
Fast Mode。 リサーチプレビュー。同じ Opus 4.8 モデルを最大 2.5 倍の毎秒出力トークン速度で提供する(プレミアム料金)。API で speed: "fast"、Claude Code で /fast。誤解しやすい点:Fast Mode は小型の安価なモデルではなく、フル性能の Opus 4.8 が速く動くものだ。レイテンシがトークン単価より重要なときに使う。
会話途中の system メッセージ。 messages 配列内で、ユーザーのターンの後に role: "system" メッセージを挿入できるようになった。長いエージェントループで、システムプロンプト全文を再掲せずに更新指示を追記できる——これにより前のターンの prompt cache ヒットが保たれ、入力コストが下がる。1,024 トークンに下がったキャッシュ最小長(4.7 より低い)と組み合わせれば、これまで短すぎてキャッシュできなかったシステムプロンプトもキャッシュ対象になる。
Adaptive thinking、effort デフォルト high。 4.7 と同様、Opus 4.8 は明示的な thinking budget を受け付けない——thinking: {"type": "enabled", "budget_tokens": N} は 400 を返す。代わりに thinking: {"type": "adaptive"} と effort パラメータを使う。adaptive thinking を有効にすると、モデルがターンごとに推論の要否を判断し、単純な参照では思考トークンの浪費が減る。effort のデフォルトは Claude Code を含む全環境で high になった。
from openai import OpenAI
client = OpenAI(base_url="https://api.ofox.ai/v1", api_key="your-ofox-key")
response = client.chat.completions.create(
model="anthropic/claude-opus-4.8",
messages=[{"role": "user", "content": "このモジュールをリファクタして…"}],
)ツール起動と圧縮処理の改善。 Anthropic が挙げる改善領域は、長時間エージェントコーディング(圧縮が減り、圧縮後の回復も向上)、推論 effort のキャリブレーション、そしてツール起動だ。具体的には、タスクが必要としたツール呼び出しを飛ばすケースが減った——4.7 で一部ユーザーが指摘していた点だ。
Opus 4.8 のプロンプト:何が変わったか
Anthropic のプロンプトガイドには、4.8 特有の挙動がいくつか挙げられている。プロンプトをそのまま移行すると引っかかる点だ。本番投入前に押さえておきたいのは次の 4 つ。
effort が主役のダイヤルになった——しかも過去のどの Opus より重要だ。 コーディングやエージェント用途では xhigh から始め、知能が問われるタスクは最低でも high を保つ。max は性能向上をもたらすこともあるが、考えすぎに陥りやすく効果は逓減する。一方で 4.8 は low と medium を厳密に守る——求められた範囲ちょうどに作業を絞るので、レイテンシには有利だが、中程度に複雑なタスクでは思考不足のリスクがある。推論が浅いと感じたら、プロンプトで回避するのではなく effort を上げること。high/xhigh では出力予算を大きめに(まず 64K トークン)取り、モデルが思考と実行に使える余地を確保する。
指示を字義どおりに解釈する。 Opus 4.8 は、特定の箇所に向けた指示を、明示されていない他の箇所へ勝手に拡大適用しない。頼んでいない作業を先回りで補うこともない。構造化抽出やパイプラインには好都合だが、ある指示を広く適用したいなら範囲を明示すること——「この書式を最初のセクションだけでなくすべてのセクションに適用して」のように。
ツール呼び出しより推論を優先する。 4.8 はデフォルトでツールを呼ぶより考える方に傾く。多くの場合これは良い方向だが、エージェントの検索やファイル読み込みが足りないと感じたら、effort を high/xhigh に上げるとツール使用が大幅に増える。どのツールをいつ・なぜ使うかを直接指示してもよい。
コードレビューの再現率(recall)の罠。 これはチームを驚かせる。Opus 4.8 はバグ発見が本当に上手くなった(Anthropic の内部評価では精度も再現率も向上)。だが、レビューハーネスに「高深刻度の問題だけ報告して」「保守的に」と書いてあると、4.8 は旧モデルより忠実にそれに従う——バグは見つけた上で、設定した基準を下回るものを落とすのだ。結果として再現率が下がったように見えるが、実際にはバグ発見能力は向上している。対策は「発見」と「フィルタリング」を分けること:
見つけた問題はすべて報告すること。低深刻度や不確実なものも含む。
この段階では重要度でフィルタしない——別の工程でランク付けする。
各指摘に確信度と推定深刻度を添えること。「最も正直なモデル」という主張
Anthropic は Opus 4.8 を「これまでで最も正直なモデル」と位置づけている——自信ありげな捏造が減り、迎合が減り、拒否がより明確になった。最後の点について、拒否応答の stop_details オブジェクト(4.7 から存在)が正式にドキュメント化され、アプリ側はリクエストがなぜ拒否されたかを把握してユーザーを適切に誘導できる。すべての拒否を同一に扱う必要がなくなる。無人運用のエージェントにとって、捏造が少なく自らの不確実性をより明確に示すモデルは、安全性をうたう以上の、運用上の信頼性向上として効いてくる。
同時リリース:Claude Code の Dynamic Workflows
Opus 4.8 は dynamic workflows と同日にリリースされた。これはリサーチプレビューで、Claude が 1 つのセッション内で数十〜数百の並列サブエージェントをオーケストレーションできる。Claude が自らオーケストレーションスクリプトを書き、作業を扇形に展開し、納品前に結果を検証する(他のエージェントの結論を反証する役割のエージェントも含む)。中断したジョブは最初からやり直さず、途中から再開する。
目玉のデモ:Jarred Sumner が dynamic workflows を使い、Bun を Zig から Rust へ移植——約 75 万行、テストスイート 99.8% 合格、11 日間で達成した。想定ユースケースはリポジトリ全体のバグ探索、セキュリティ監査、数千ファイルにまたがる大規模移行だ。
冷静に見るべき注意点が 2 つ。第一に、プラン制限がある:dynamic workflows は Claude Code の Max・Team・Enterprise プランで動作し(Enterprise は管理者の有効化が必要)、素の API では使えない。第二に、Anthropic はトークン消費が通常セッションより大幅に多いと明言しており、スコープを絞ったタスクから始めることを推奨している。最も難しい仕事のための新能力であって、デフォルトで常時オンの便利機能ではない。
ofox.ai 経由で Opus 4.8 にアクセスする
モデル ID は anthropic/claude-opus-4.8。ofox.ai 経由なら、他の全モデルと同じ OpenAI 互換エンドポイントで使える——Anthropic 個別アカウントも別請求も不要だ。
adaptive thinking・effort 制御を使うには Anthropic ネイティブプロトコルを使う:
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="your-ofox-key",
)
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=4096,
thinking={"type": "adaptive"},
messages=[{"role": "user", "content": "このサービスの競合状態を監査して…"}],
)アグリゲータ経由なら、「移行すべきか」をデータで判断できる。1 つの key・1 つのエンドポイントで同じプロンプトを Opus 4.8・4.7・GPT-5.5 に通し、自分のワークロードで品質とトークン数を比較してから決められる。請求書(適格請求書を含む)を 1 社にまとめられる点も、情シス審査を通す上で実務的に効く。
結論
Opus 4.8 は、デメリットらしいデメリットの見当たらない珍しいアップグレードだ:同じ $5/$25、コーディングとコンピュータ操作でほぼ全面的に高いスコア、独立系実務リーダーボードで首位、しかもタスクあたりの出力トークンは少ない。正直な注意点は狭い——GPT-5.5 は生のターミナルベンチではまだ勝つ、dynamic workflows はプラン制限ありかつトークン大食い、effort はデフォルト high なのでレイテンシ予算を要確認。
新規プロジェクトは 4.8 から始めるとよい。4.7 で本番を回しているなら、これは Anthropic が近年出した中で最もクリーンな移行だ——同価格・トークン減で、計算はたいてい有利に出る。代表的なサンプルでテストし、ツール呼び出しのプロンプトに注意しつつ、切り替えよう。
関連記事:Claude Opus 4.7 API レビュー —— 前世代の振り返り。Claude vs GPT vs Gemini フラッグシップ比較 —— 主要モデル横断比較。日本語 LLM ベンチマーク —— 国産勢を含む日本語性能。日本企業向け AI ゲートウェイと JPY 請求 —— 適格請求書・情シス審査の論点。


