Claude Opus 4.8: 1890 Elo, Fast Mode и SWE-bench 69,2%
Claude Opus 4.8 вышел 28 мая 2026 по цене 4.7 и возглавил лидерборд GDPval-AA. Разбор: Fast Mode ×2,5, dynamic workflows в Claude Code, честность модели и доступ из России.

TL;DR — Anthropic выпустила Claude Opus 4.8 28 мая 2026 года по той же цене $5/$25, что и 4.7. Модель возглавила независимый лидерборд реальной работы GDPval-AA от Artificial Analysis с 1890 Elo (+121 к GPT-5.5, +137 к 4.7), берёт 69,2% на SWE-bench Pro и делает это примерно на 35% меньшим числом выходных токенов, чем 4.7 — то есть сильнее и дешевле в работе. Новое в релизе: Fast Mode (скорость вывода ×2,5), системные сообщения в середине диалога и dynamic workflows в Claude Code. Anthropic также называет её своей самой честной моделью.
Что именно выпустила Anthropic
Claude Opus 4.8 вышла 28 мая 2026 года — примерно через пять недель после того, как поколение GPT-5.5 (релиз 23 апреля) переписало вершину лидербордов. ID модели — claude-opus-4-8. На Claude API она по умолчанию несёт полное контекстное окно на 1M токенов (200K на Microsoft Foundry), до 128K выходных токенов и — что важно для планирования бюджета — тот же прайс, что и Opus 4.7: $5 за вход и $25 за выход за миллион токенов.
Главная новость здесь не снижение цены и не рост контекста. Дело в том, что Opus 4.8 — первая модель, которая заметно оторвалась от поколения GPT-5.5 на реальной агентной работе, и сделала это меньшим числом токенов.
Результат на GDPval-AA
Самая интересная цифра — не от Anthropic, а от независимой группы Artificial Analysis. Их лидерборд GDPval-AA оценивает модели на реальных экономических задачах (44 профессии в 9 отраслях из датасета GDPval от OpenAI): каждой модели дают доступ к шеллу и веб-браузингу внутри агентного цикла через их open-source-харнесс Stirrup, а рейтинг Elo выводят из слепых попарных сравнений.
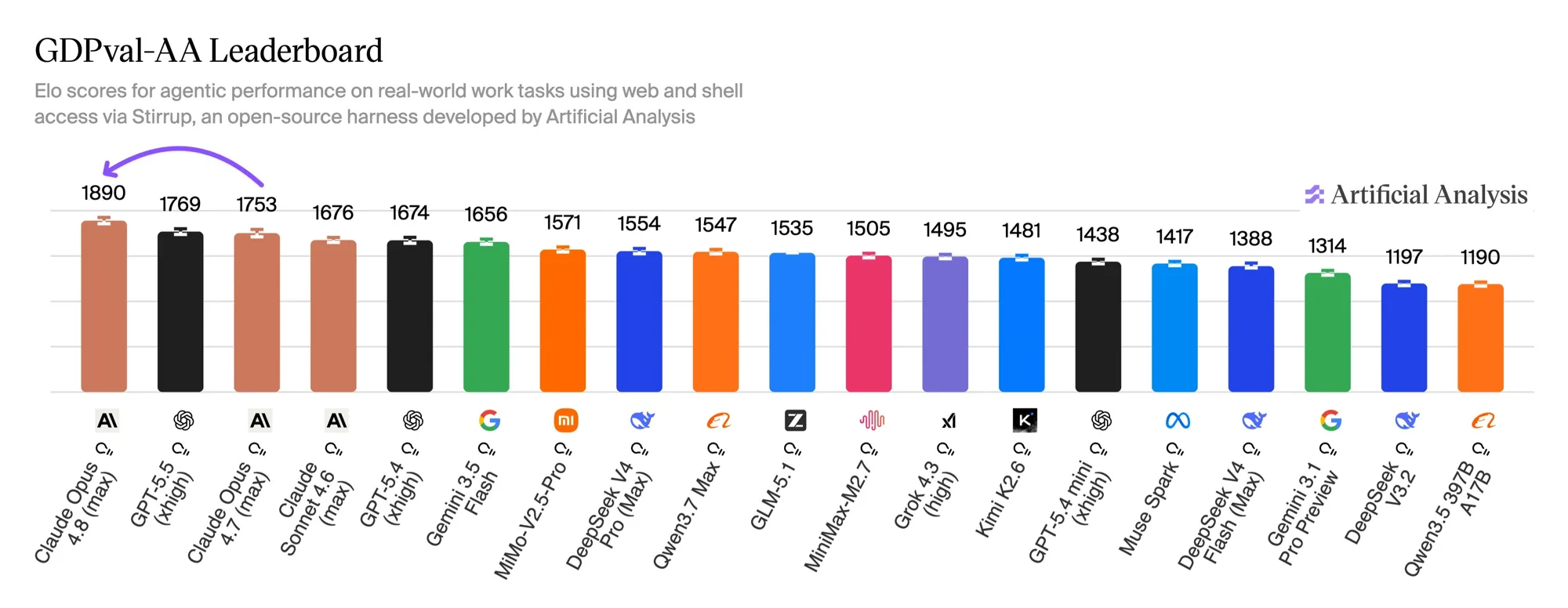
Opus 4.8 (effort max) дебютирует с 1890 Elo, опережая идущий вторым GPT-5.5 на 121 очко и собственного предшественника — на 137. В пересчёте этот отрыв соответствует расчётной вероятности победы около 67% в прямых сравнениях с GPT-5.5 на настройке xhigh. Три из четырёх верхних строк — модели Claude.
Что делает результат убедительнее голого процента в бенчмарке: Artificial Analysis отмечает, что Opus 4.8 достигла этого счёта, тратя на задачу на 15% меньше ходов и на 35% меньше выходных токенов, чем Opus 4.7. Расплата за это — модели нужно примерно на 30% больше ходов, чем GPT-5.5, чтобы завершить ту же задачу: Opus больше рассуждает, прежде чем действовать. Для агентных конвейеров, где счёт определяют выходные токены, сочетание «меньше токенов при более высокой доле побед» — именно то, что реально двигает месячный счёт.
Бенчмарки на фоне конкурентов
Собственные цифры Anthropic совпадают с независимым результатом по кодингу и работе с компьютером — с одной оговоркой.
| Бенчмарк | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69,2% | 64,3% | 58,6% | 54,2% |
| OSWorld-Verified (работа с компьютером) | 83,4% | 82,8% | 78,7% | 76,2% |
| Terminal-Bench 2.1 | 74,6% | 66,1% | 78,2% | 70,3% |
| Humanity’s Last Exam (с инструментами) | 57,9% | — | — | — |
| Finance Agent v2 | 53,9% | — | — | — |
| GDPval-AA (Elo) | 1890 | 1753 | 1769 | — |
SWE-bench Pro использует настоящие open-source-репозитории, а не синтетические задачи, и 69,2% — это отрыв почти в 5 пунктов от Opus 4.7, прежнего лидера класса. OSWorld-Verified (управление реальным рабочим столом) — область, где Opus давно и без лишнего шума держит первенство.
Исключение, о котором стоит сказать честно: Terminal-Bench 2.1 по-прежнему за GPT-5.5 (78,2% против 74,6%). Если ваша нагрузка — это в основном цепочки сырых терминальных команд, это реальный аргумент, а не погрешность. Но для большинства агентного кодинга — рефакторинг по нескольким файлам, долгие автономные прогоны, задачи на уровне всего репозитория — Opus 4.8 сейчас самый сильный вариант.
Что нового под капотом
Помимо цифр, четыре изменения на уровне API важны всем, кто строит на Opus 4.8.
Fast Mode. Research preview, отдающий ту же модель Opus 4.8 со скоростью до ×2,5 выходных токенов в секунду по премиальной цене. Включается через speed: "fast" в API или /fast в Claude Code. Здесь часто ошибаются: Fast Mode — это не уменьшенная дешёвая модель, а полный Opus 4.8, работающий быстрее, для случаев, когда задержка важнее стоимости токена.
Системные сообщения в середине диалога. Теперь можно вставлять сообщения с role: "system" после пользовательского хода в массиве messages. В длинном агентном цикле это позволяет дописывать обновлённые инструкции, не повторяя весь системный промпт — а значит, сохраняются попадания в prompt cache на ранних ходах и снижается стоимость входа. Вместе со сниженным до 1024 токенов минимумом кэширования (ниже, чем у 4.7) короткие системные промпты, которые раньше нельзя было кэшировать, теперь кэшируются.
Adaptive thinking, effort по умолчанию high. Как и 4.7, Opus 4.8 не принимает явный thinking budget — thinking: {"type": "enabled", "budget_tokens": N} вернёт 400. Используйте thinking: {"type": "adaptive"} и параметр effort. При включённом adaptive thinking модель сама решает на каждом ходу, нужно ли рассуждать, и меньше тратит токенов мышления на простые запросы. Значение effort по умолчанию теперь high везде, включая Claude Code.
from openai import OpenAI
client = OpenAI(base_url="https://api.ofox.ai/v1", api_key="your-ofox-key")
response = client.chat.completions.create(
model="anthropic/claude-opus-4.8",
messages=[{"role": "user", "content": "Отрефактори этот модуль…"}],
)Лучшее срабатывание инструментов и компакция. В списке улучшений Anthropic — долгий агентный кодинг (меньше компакций и лучшее восстановление после них), калибровка усилий рассуждения и срабатывание инструментов: модель реже пропускает вызов инструмента, которого требовала задача, — на это жаловались некоторые пользователи 4.7.
Промптинг Opus 4.8: что реально изменилось
В руководстве Anthropic по промптингу есть несколько специфичных для 4.8 моментов, на которых легко обжечься, если перенести промпты как есть. Четыре стоит знать до выкатки.
Effort теперь главная ручка — и важнее, чем в любом прошлом Opus. Для кодинга и агентных сценариев начинайте с xhigh, для всего, что чувствительно к интеллекту, держите минимум high. max иногда даёт прирост, но склонен к перемышлению с убывающей отдачей. Обратная сторона: 4.8 строго соблюдает low и medium — сужает работу ровно до того, о чём попросили, что хорошо для задержки, но рискует недомышлением на умеренно сложных задачах. Если рассуждение выглядит поверхностным, поднимайте effort, а не обходите это промптом. На high/xhigh задавайте большой бюджет вывода (начните с 64K токенов), чтобы у модели было место думать и действовать.
Она следует инструкциям буквально. Opus 4.8 не переносит молча инструкцию с одного объекта на другой и не додумывает запросы, которых вы не делали. Для структурированного извлечения и конвейеров это плюс — но если нужно применить указание широко, прописывайте охват явно: «Примени это форматирование к каждой секции, а не только к первой».
Она предпочитает рассуждение вызову инструментов. По умолчанию 4.8 склоняется к размышлению, а не к вызову инструментов, и обычно это к лучшему — но если ваш агент мало ищет или мало читает файлы, повышение effort до high/xhigh заметно увеличивает использование инструментов. Можно и прямо указать, когда и зачем применять конкретный инструмент.
Ловушка с recall в код-ревью. Этот момент удивляет команды. Opus 4.8 действительно лучше находит баги (в оценках Anthropic выше и точность, и полнота), но если в вашем ревью-харнессе написано «сообщай только о серьёзных проблемах» или «будь консервативнее», 4.8 следует этому добросовестнее старых моделей: баги находит, а затем отбрасывает то, что ниже заданной планки. Со стороны это выглядит как падение recall, хотя способность находить баги выросла. Решение — разделить поиск и фильтрацию:
Сообщай о каждой найденной проблеме, включая малозначимые и сомнительные.
На этом этапе не фильтруй по важности — ранжировать будет отдельный шаг.
Для каждой находки указывай уровень уверенности и предполагаемую серьёзность.Заявление о «самой честной модели»
Anthropic позиционирует Opus 4.8 как самую честную свою модель: меньше уверенных выдумок, меньше угодливости, более внятные отказы. По последнему пункту объект stop_details в ответах-отказах (есть с 4.7) теперь официально задокументирован, так что приложение может понять, почему запрос отклонён, и направить пользователя дальше, вместо того чтобы обрабатывать все отказы одинаково. Для агентов, работающих без присмотра, модель, которая меньше выдумывает и чётче сигнализирует о собственной неуверенности, — это практический выигрыш в надёжности, а не абстрактные рассуждения о безопасности.
Вышло вместе: Dynamic Workflows в Claude Code
Opus 4.8 вышла в один день с dynamic workflows — research preview, позволяющим Claude оркестрировать от десятков до сотен параллельных субагентов в рамках одной сессии. Claude сам пишет скрипт оркестрации, разворачивает работу веером, проверяет результаты перед выдачей (включая агентов, чья задача — опровергнуть выводы других) и возобновляет прерванные задания с места остановки, а не с начала.
Флагманская демонстрация: Джарред Самнер с помощью dynamic workflows портировал Bun с Zig на Rust — около 750 000 строк кода, 99,8% прохождения тестового набора, за 11 дней. Целевые сценарии — поиск багов по всему репозиторию, аудиты безопасности и крупные миграции на тысячи файлов.
Две оговорки. Первая: функция привязана к тарифу — dynamic workflows работают на планах Claude Code Max, Team и Enterprise (для Enterprise нужно включение администратором), а не на голом API. Вторая: Anthropic прямо предупреждает, что расход токенов существенно выше обычной сессии, и рекомендует начинать с узких задач. Это новая возможность для самой тяжёлой работы, а не удобство по умолчанию.
Как получить доступ к Opus 4.8 через ofox.ai
ID модели — anthropic/claude-opus-4.8. Через ofox.ai она доступна на том же OpenAI-совместимом эндпоинте, что и все остальные модели, — без отдельного аккаунта и биллинга Anthropic, что снимает и проблему оплаты для пользователей из России.
Для adaptive thinking и управления effort используйте нативный протокол Anthropic:
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="your-ofox-key",
)
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=4096,
thinking={"type": "adaptive"},
messages=[{"role": "user", "content": "Проверь этот сервис на состояния гонки…"}],
)Через агрегатор и сам вопрос «переходить ли» решается на данных: одним ключом и одним эндпоинтом можно прогнать одни и те же промпты через Opus 4.8, 4.7 и GPT-5.5 и сравнить качество и расход токенов на вашей нагрузке, прежде чем решаться.
Вердикт
Opus 4.8 — редкий апгрейд без звёздочки в цене: те же $5/$25, выше показатели по кодингу и работе с компьютером, первое место в независимом лидерборде реальной работы и меньше выходных токенов на задачу. Честные оговорки узкие: GPT-5.5 всё ещё выигрывает сырые терминальные бенчмарки, dynamic workflows привязаны к тарифу и прожорливы по токенам, а effort теперь по умолчанию high — проверьте бюджет по задержке.
Для новых проектов начинайте с 4.8. Если продакшен на 4.7, это самая чистая миграция Anthropic за последнее время: та же цена и меньше токенов обычно работают вам на руку. Прогоните репрезентативную выборку, последите за промптами по вызову инструментов — и переключайтесь.
Читайте также: Доступ к Claude API из России: Opus и Sonnet — как подключиться и оплатить. Полный гайд по доступу к Claude API в России. Gemini 3.1 Pro: полный гайд для России — флагман от Google. Мультимодельная стратегия и оптимизация затрат — как маршрутизировать модели по задачам.


