Gemini 3.1 Flash Lite против DeepSeek V4 Flash для агентских циклов
DeepSeek V4 Flash дешевле за токен, но 76,5% Flash Lite по BFCL v3 часто выигрывают по итоговой стоимости. Разбираем арифметику агентского цикла и надёжность tool-call.
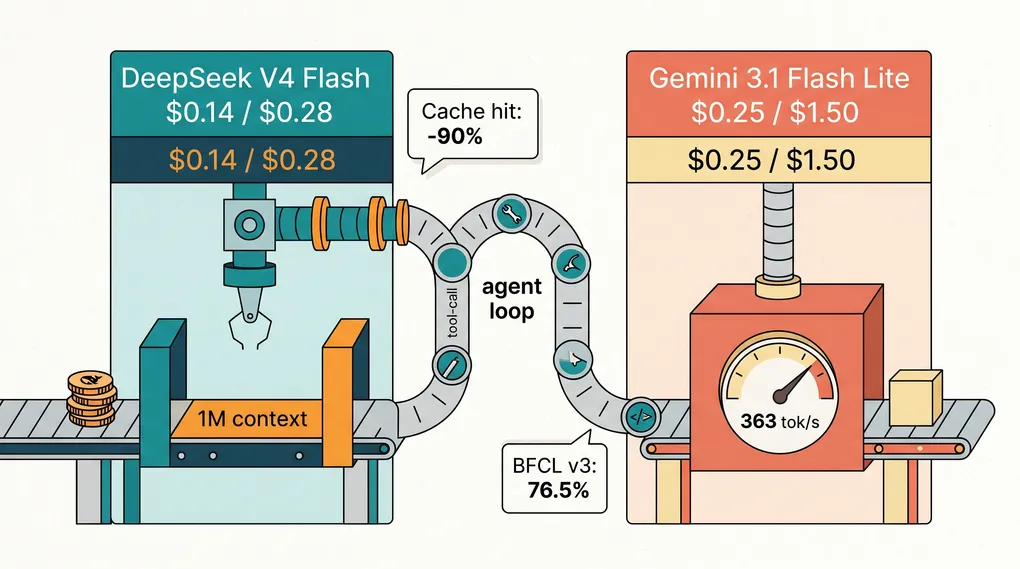
Кратко — DeepSeek V4 Flash — это более дешёвый сырой API; Gemini 3.1 Flash Lite — более надёжный агент. Правильный вопрос не «что стоит меньше за токен», а «какая модель сжигает меньше токенов в сумме, чтобы завершить ваш цикл». На ограниченных циклах со стабильными системными промптами DeepSeek выигрывает по обеим осям, как только подключается cache hit. На длинных цепочках вызовов инструментов и незнакомых API результат Flash Lite в 76,5% по BFCL v3 и более быстрый time-to-first-token отбивают наценку, завершая задачу с первого раза. Если запуск вашего агентского цикла стоит $0.50, и Flash Lite справляется за одну попытку там, где DeepSeek нужны две, вы уже потеряли всю экономию.
РАСПРОДАЖА — $5 бесплатных кредитов новым пользователям — Запускайте DeepSeek V4 Flash и Gemini 3.1 Flash Lite с одного ключа ofox.ai, без переписывания SDK.
Две модели — без маркетинга
Сразу проясним одно: «Gemini 3.1 Flash» как отдельного уровня в мае 2026 не существует. Google выпускает Gemini 3.1 Flash Lite Preview и Gemini 3 Flash Preview. Когда в бенчмарках говорят «3.1 Flash», обычно имеют в виду именно Flash Lite. Стандартная линейка «Flash» по-прежнему на релизе 3.0 и стоит $0.50 на входе и $3.00 на выходе за миллион токенов. Для бюджетных агентских циклов релевантный продукт Google — это Flash Lite.
| Модель | Архитектура | Контекст | Лимит вывода | Прайс (вход / выход за M) |
|---|---|---|---|---|
| Gemini 3.1 Flash Lite Preview | Dense | 1,048,576 | 65,536 | $0.25 / $1.50 |
| DeepSeek V4 Flash | MoE (284B всего, 13B активных) | 1,000,000 | 384,000 | $0.14 / $0.28 |
Обе модели доступны на ofox по прайсовой цене (каталог моделей ofox, проверено 2026-05-14). У DeepSeek V4 Flash к тому же щедрая скидка за cache hit: кешированный вход по $0.0028 за миллион, скидка 98% относительно cache miss (опущена до 1/10 от стартового тарифа 2026-04-26). Gemini 3.1 Flash Lite тоже даёт чтение из текстового кеша по $0.025 за миллион (и аудио по $0.05), но это примерно в 9 раз дороже кешированного тарифа DeepSeek (прайс Google Gemini API, проверено 2026-05-14).
Разницу в лимите вывода стоит обозначить сразу. DeepSeek V4 Flash выдаёт до 384K выходных токенов за один ход; Flash Lite ограничена 65K. Для агентских циклов, которые генерируют длинные структурированные отчёты — развёрнутые тест-планы, многофайловые рефакторинги одним ответом — у DeepSeek больше запаса, прежде чем придётся резать вывод на куски.
Сколько на самом деле стоят 100M токенов
Посчитаем на реалистичной агентской нагрузке. Предположим, кодинг-агент обрабатывает 70M входных токенов и выдаёт 30M выходных в месяц — типичная команда среднего объёма с автоматическими прогонами рефакторинга, генерацией тестов и задачами по документации.
По прайсовой цене, без cache hit:
| Модель | Стоимость входа | Стоимость выхода | Итого в месяц |
|---|---|---|---|
| DeepSeek V4 Flash | $9.80 | $8.40 | $18.20 |
| Gemini 3.1 Flash Lite | $17.50 | $45.00 | $62.50 |
DeepSeek дешевле в 3,4 раза по совокупности. Разрыв раскрывается именно на выходе — тариф Flash Lite в $1.50/M на выходе становится реальным налогом для агентских циклов, которые выдают многословные обоснования вызовов инструментов или длинные блоки кода.
Теперь учтём cache hit. Большинство агентских циклов со стабильным системным промптом укладываются в диапазон 60-75% — каждый результат инструмента инвалидирует часть контекста, поэтому показатели 90%+ из маркетинговых материалов не выдерживают столкновения с реальными нагрузками (это подробно разобрано в нашем анализе V4 Pro против Flash).
При cache hit в 70% фактический тариф входа DeepSeek V4 Flash падает примерно до $0.044/M, а у Flash Lite — примерно до $0.093/M:
| Модель | Фактический вход (cache 70%) | Выход | Итого в месяц |
|---|---|---|---|
| DeepSeek V4 Flash | $3.08 | $8.40 | $11.48 |
| Gemini 3.1 Flash Lite | $6.48 | $45.00 | $51.48 |
Это уже 4,5-кратный разрыв. Если у вашего агентского цикла стабильный системный промпт, и вы действительно получаете скидку за кеш, DeepSeek V4 Flash ближе к бесплатному, чем к ценовому диапазону Flash Lite — широким суммарный разрыв держит именно множитель по выходу, ведь у Flash Lite нет рычага кеша на выходной стороне.
Где более дешёвая модель тихо проигрывает
Арифметика за токен — это первый слой. Второй слой — суммарно потреблённые токены, а это зависит от того, сколько попыток модели нужно, чтобы завершить задачу.
Надёжность вызова инструментов. Gemini 3.1 Flash Lite набирает 76,5% по BFCL v3 (карточка модели Google DeepMind), с уверенным запасом над ориентировочной планкой производственной пригодности в 70%. DeepSeek V4 Flash набирает 86.2 по MMLU Pro и 79 по SWE-bench Verified (карточка модели DeepSeek V4 Flash), но заметно проседает на многошаговых трассах вызова инструментов Terminal Bench 2.0 по сравнению с V4 Pro. Картина по результатам тестирования сообществом сходится в одном: Flash чисто отрабатывает цепочки в 4-6 вызовов инструментов и начинает накапливать ошибки после 8. Flash Lite держится дольше на той же глубине трассы.
Time to first token. Flash Lite — более быстрая модель в цикле. Опубликованные Google цифры — в 2,5 раза быстрее Time to First Answer Token и прирост скорости вывода на 45% относительно Gemini 2.5 Flash; Artificial Analysis измеряет примерно 347 выходных токенов в секунду на API Google. DeepSeek V4 Flash не публикует сопоставимую спецификацию, но полевые отчёты в недавних ветках про агентские бенчмарки ставят её в диапазон 150-200 tok/s на стандартных провайдерах. Для интерактивных кодинг-агентов, где человек ждёт ответа, разрыв ощутим. Для пакетных ночных прогонов он незаметен.
Незнакомые схемы инструментов. Обучение Gemini на собственных трассах использования инструментов Google даёт Flash Lite преимущество на незнакомых сигнатурах функций — она, как правило, корректно следует схеме с первого раза, даже для инструментов, которых не видела в бенчмарках. DeepSeek V4 Flash отлично работает на стандартных вызовах функций по JSON-Schema, но чуть хуже восстанавливается, когда инструмент возвращает некорректный ответ. Если ваш агент использует длинный хвост внутренних инструментов с самописными схемами, этот разрыв имеет значение.
Дисциплина по многословности вывода. Flash Lite по умолчанию выдаёт более лаконичный вывод — ближе к тому, что написал бы senior-инженер в комментарии к код-ревью. DeepSeek V4 Flash склонна добавлять пояснительный текст вокруг блоков кода, что нормально для документации, но раздувает счёт за токены в агентских циклах, где потребитель — другая LLM, а не человек. Это можно обуздать промптом, но это трение.
Суть здесь не в том, что одна модель лучше. Суть в том, что заголовочный разрыв в цене сжимается, как только учесть частоту повторных попыток и многословность токенов. Если DeepSeek нужно в среднем 1,4 попытки на задачу там, где Flash Lite хватает 1,0, фактическое соотношение стоимости схлопывается с 3,4x примерно до 2,4x. Если нужно 2,0 попытки — разрыв по сути исчезает.
Правила выбора
После прогона обеих моделей на нескольких неделях смешанных агентских нагрузок вот правило, которое мы бы записали:
Выбирайте DeepSeek V4 Flash, когда:
- Ваши циклы ограничены (4-6 вызовов инструментов, укладываются в один-два файла)
- У вас стабильный системный промпт, и вы можете подтвердить cache hit rate в 60%+ по своему дашборду
- Объём вывода на задачу высок (длинная генерация кода, многофайловый вывод, структурированные отчёты)
- Стоимость — связывающее ограничение, и сбои можно перенаправить в другое место
Выбирайте Gemini 3.1 Flash Lite, когда:
- Ваши циклы выстраивают цепочки из 6-12 вызовов инструментов или задействуют незнакомые схемы инструментов
- Важна интерактивная задержка (IDE-агенты для разработчиков, copilot-ы в стиле чата)
- Вывод короткий и структурированный (JSON-ответы, вызовы инструментов, сжатые сводки)
- Вы ещё не профилировали cache hit rate и не хотите закладывать бюджет на оптимистичных допущениях
Маршрутизируйте обе, когда у вас смешанные нагрузки. Поставьте перед ними классификатор (или используйте единый endpoint ofox, чтобы переключаться по названию модели без касания кода SDK) и отправляйте ограниченные задачи на DeepSeek, а многошаговые или насыщенные схемами — на Flash Lite. Логика маршрутизации ценнее выбора любой из моделей — это разобрано в нашем гайде по паттерну гибридной маршрутизации и в более широком материале о выборе модели для агентов.
Что на самом деле значит «бюджетный агентский цикл»
Сноска по терминологии, поскольку «бюджетный» в маркетинговых текстах растягивают как угодно. Есть три формы нагрузки, которые называют «бюджетными агентскими циклами»:
- Высокочастотные малозначимые — триаж в чате, классификация намерений, извлечение данных из полуструктурированных документов. Обе модели здесь — колоссальный перебор; прежде чем платить за любую из них, стоит рассмотреть бесплатные тарифы.
- Ограниченные кодинг-задачи в масштабе — автоматическая генерация тестов, скаффолдинг, однофайловые рефакторинги. DeepSeek V4 Flash выигрывает по стоимости, а качество достаточно близко, чтобы вопрос маршрутизации почти не возникал.
- Многошаговое исследование или планирование — прочитать 10 документов, синтезировать, выдать план. Здесь надёжность вызова инструментов у Flash Lite отбивает свою наценку, особенно если вы выходите на незнакомые инструменты.
Если ваш «высокообъёмный агентский цикл» на деле означает категорию 1 или 2, ответ — DeepSeek. Если это категория 3 с более длинными цепочками, надёжность Flash Lite тихо накапливает преимущество.
Как гонять обе через один endpoint
Если вы работаете на ofox, обе модели доступны через один и тот же OpenAI-совместимый endpoint. Меняете название модели, всё остальное в форме запроса оставляете идентичным:
from openai import OpenAI
client = OpenAI(api_key=OFOX_KEY, base_url="https://api.ofox.ai/v1")
resp = client.chat.completions.create(
model="deepseek-v4-flash", # or "google/gemini-3.1-flash-lite-preview"
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_msg}],
tools=TOOL_SCHEMA,
)Перед деплоем сверьте точные ID моделей в каталоге ofox — названия preview-моделей могут меняться по мере того, как Google переводит Flash Lite из preview в GA. Для более широкого контекста по диспетчеризации нескольких моделей через один ключ см. обзор агрегирующего шлюза.
Итог
DeepSeek V4 Flash — более дешёвый API из представленных, и как только подключается cache hit, суммарные месячные траты держатся в диапазоне 4-5x — текстовый кеш Flash Lite сужает разрыв по входу, но множитель по выходу держит суммарный широким. Для ограниченных кодинг-агентов это выбор по умолчанию — Flash Lite заставляет платить за возможности, которыми вы не воспользуетесь. Для многошаговых циклов с вызовом инструментов, насыщенных схемами рабочих процессов и везде, где частота повторных попыток важнее стоимости за токен, надёжность Gemini 3.1 Flash Lite стоит наценки. Самая дешёвая модель — та, что завершает задачу с первого раза — и для бюджетных агентских циклов это ответ, зависящий от конкретной нагрузки, а не глобальный.
Контекст по ценам всего семейства DeepSeek — в разборе прайсинга DeepSeek API. По старшему уровню Gemini — глубокое погружение в Gemini 3.1 Pro, где разобрано пространство компромиссов против Flash Lite. Более широкая картина по вендорам — в сравнении моделей Claude vs GPT vs Gemini и в матрице выбора LLM API.