Руководство по использованию GPT-5.2 API из Китая: сравнение трёх подходов (2026)
Кратко
Для разработчиков из Китая вызов API зарубежных моделей — GPT-5.2, Claude, Gemini — сопряжён с тремя проблемами: нестабильная сеть, высокий порог оплаты, большая задержка. Существует три основных подхода: самостоятельный прокси, управляемые облачные сервисы, платформа-агрегатор API. Для большинства разработчиков и небольших команд агрегатор — самый выгодный выбор: единый интерфейс, прямой доступ из Китая, оплата в юанях, задержка первого байта от 300 мс. Статья содержит полное сравнение трёх подходов, руководства по подключению нативных SDK GPT / Claude / Gemini и реальные данные — подключение за 5 минут.
Содержание
- Проблема: три основные трудности доступа к зарубежным AI API из Китая
- Подход 1: Самостоятельный прокси-узел
- Подход 2: Управляемые облачные сервисы
- Подход 3: Платформа-агрегатор API (рекомендуется)
- Сравнение трёх подходов
- Цены AI API ведущих моделей в 2026 году
- Практика: полный туториал по вызову GPT / Claude / Gemini на Python
- Часто задаваемые вопросы (FAQ)
- Итоги и план действий
- Справочные материалы

Проблема: три основные трудности доступа к зарубежным AI API из Китая
В 2026 году GPT-5.2, Claude Opus 4.6, Gemini 3.1 Pro стали стандартными инструментами для разработки AI-приложений. Однако разработчики из Китая, ищущие стабильный AI API с прямым доступом, сталкиваются с тремя проблемами:
1. Нестабильное сетевое подключение, частые таймауты OpenAI API
API-эндпоинты OpenAI, Anthropic, Google размещены за рубежом. Прямые запросы из Китая часто сталкиваются с таймаутами, ошибками SSL-хендшейка и обрывами соединения. В сценариях Streaming (потоковый вывод) разрыв длинного соединения напрямую влияет на пользовательский опыт. По отзывам разработчиков, при прямом подключении к OpenAI API успешность запросов не превышает 60% — для продакшена это неприемлемо.
2. Высокий порог оплаты, невозможность оплаты в рублях/юанях
OpenAI требует зарубежную кредитную карту (UnionPay не поддерживается), Anthropic — зарубежный номер телефона для регистрации, Google Cloud не принимает прямую оплату в юанях. Для индивидуальных разработчиков и небольших команд одна только регистрация и пополнение отнимают массу времени — многие бросают на этапе оплаты.
3. Слишком высокая задержка, влияющая на UX
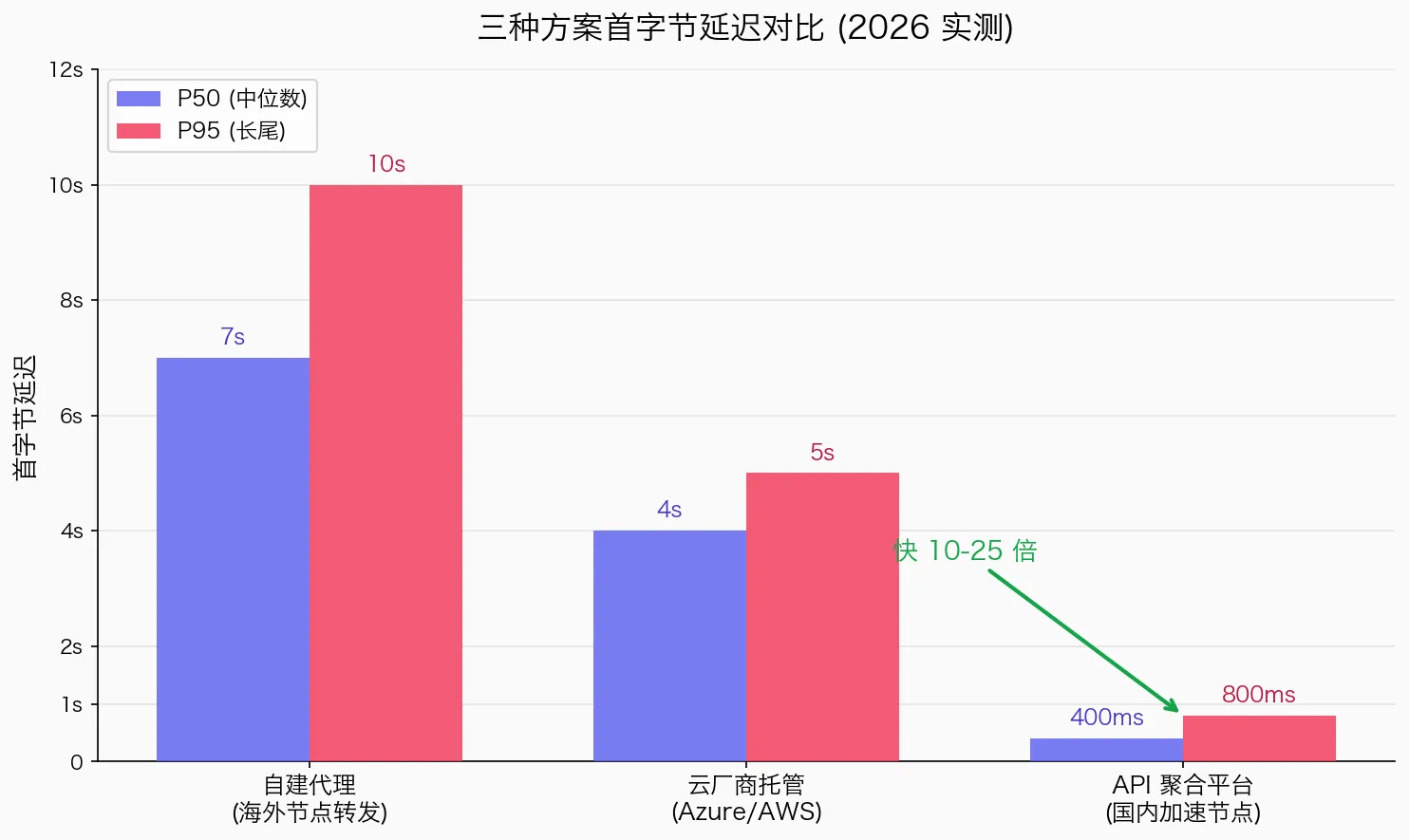
Даже при наличии связи прямое подключение из Китая к зарубежным API даёт задержку первого байта 3-10 секунд, тогда как оптимизированные локальные узлы ускорения — 300-800 мс. Для реалтайм-диалогов, автодополнения кода и других low-latency сценариев разница критична. Пользователь, ждущий 1 секунду или 5 секунд — это совершенно разный опыт.
Какие же существуют альтернативы OpenAI API? Рассмотрим три основных подхода.
Подход 1: Самостоятельный прокси-узел
Принцип
Развёртывание обратного прокси на зарубежном облачном сервере для пересылки запросов из Китая к эндпоинтам OpenAI и других API. Типичные реализации: Cloudflare Workers, Nginx reverse proxy.
Пример Cloudflare Workers
// worker.js — развёртывание в Cloudflare Workers
export default {
async fetch(request) {
const url = new URL(request.url);
url.hostname = 'api.openai.com';
const newRequest = new Request(url, {
method: request.method,
headers: request.headers,
body: request.body,
});
return fetch(newRequest);
}
};После развёртывания измените base_url на домен вашего Worker.
Анализ плюсов и минусов
| Параметр | Оценка |
|---|---|
| Стоимость | Низкая (бесплатная квота Cloudflare Workers — 100 000 запросов/день) |
| Задержка | Высокая (через зарубежный узел, первый байт 5-10 секунд) |
| Покрытие моделей | Только один вендор (для каждого нужна отдельная настройка) |
| Обслуживание | Высокое (ограничение частоты, повторы, SSL-сертификаты — всё самостоятельно) |
| Подходит для | Личные проекты, технические эксперименты |
Предупреждение о рисках
Самостоятельный прокси — единая точка отказа. При изменении IP-диапазона Workers или обновлении upstream API сервис упадёт и потребуется ручное вмешательство. Кроме того, нет возможности переключения между моделями — для одновременного использования GPT-5.2 и Claude придётся развернуть два прокси.
Подход 2: Управляемые облачные сервисы
Принцип
Вызов моделей через корпоративные сервисы — Azure OpenAI Service, AWS Bedrock, Google Cloud Vertex AI.
Пример Azure OpenAI
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint="https://your-resource.openai.azure.com/",
api_key="your-azure-key",
api_version="2024-12-01-preview"
)
response = client.chat.completions.create(
model="gpt-5.2", # Название модели, развёрнутой в Azure
messages=[{"role": "user", "content": "Объясни, что такое RAG"}]
)
print(response.choices[0].message.content)Анализ плюсов и минусов
| Параметр | Оценка |
|---|---|
| Стоимость | Высокая (Azure на 10-30% дороже OpenAI + расходы на облачные ресурсы) |
| Задержка | Средняя (узел Azure East Asia — первый байт ~3-5 секунд) |
| Покрытие моделей | Ограничено (Azure — только OpenAI, Bedrock — часть моделей Anthropic) |
| Обслуживание | Среднее (управление несколькими облачными аккаунтами и SDK) |
| Подходит для | Корпоративные проекты, требования к соответствию |
Ограничения
Главная проблема — привязка к вендору. Azure OpenAI — только модели OpenAI. Хотите Claude и Gemini одновременно? Нужно подключить AWS Bedrock и Vertex AI отдельно — три аккаунта, три SDK, три биллинга. Сложность растёт экспоненциально.
Подход 3: Платформа-агрегатор API (рекомендуется)
Принцип
Платформа-агрегатор (также AI Gateway, API-ретрансляция) размещает узлы ускорения в Китае, подключается к нескольким провайдерам моделей и предоставляет разработчикам нативный интерфейс, совместимый с тремя основными протоколами — OpenAI, Anthropic, Gemini. Достаточно направить base_url SDK на узел платформы — существующий код менять не нужно. Это наиболее популярная альтернатива OpenAI API на данный момент.
Ключевые преимущества
- Три нативных протокола: прямое подключение нативных SDK OpenAI, Anthropic, Gemini с сохранением всех фирменных функций
- Прямой доступ из Китая: узлы Alibaba Cloud / Volcano Cloud, без дополнительной сетевой настройки
- Оплата в юанях: Alipay, WeChat Pay — без зарубежной карты
- Низкая задержка: узлы в Китае, первый байт 300-800 мс
- Командный режим: регистрация одним участником — доступ для всей команды, расход каждого члена прозрачен
- Автоматическая отказоустойчивость: при сбое upstream API автоматическое переключение на резервный канал
Примеры кода: прямое подключение трёх нативных SDK
На примере Ofox.ai — все три SDK подключаются напрямую, достаточно изменить base_url:
OpenAI SDK — вызов GPT-5.2 (Responses API)
# SDK: openai v2.24.0
# Документация: https://platform.openai.com/docs/api-reference/responses
# Обновлено: 2026-03-03
from openai import OpenAI
client = OpenAI(
base_url="https://api.ofox.ai/v1",
api_key="your-ofox-api-key" # Получить на app.ofox.ai
)
response = client.responses.create(
model="openai/gpt-5.2",
input="Реализуй простую систему RAG на Python",
)
print(response.output_text)Anthropic SDK — вызов Claude Opus 4.6
# SDK: anthropic v0.84.0
# Документация: https://docs.anthropic.com/en/api/getting-started
# Обновлено: 2026-03-03
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="your-ofox-api-key"
)
message = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "Реализуй простую систему RAG на Python"}],
)
print(message.content[0].text)Google GenAI SDK — вызов Gemini 3 Flash
# SDK: google-genai v1.65.0
# Документация: https://googleapis.github.io/python-genai/
# Обновлено: 2026-03-03
from google import genai
client = genai.Client(
api_key="your-ofox-api-key",
http_options={"base_url": "https://api.ofox.ai/gemini"}
)
response = client.models.generate_content(
model="google/gemini-3-flash-preview",
contents="Реализуй простую систему RAG на Python",
)
print(response.text)Интерфейсы трёх SDK совершенно разные (responses.create / messages.create / generate_content), но через Ofox все они доступны из Китая с единой тарификацией. Каждый SDK сохраняет все фирменные функции — extended thinking от Claude, сверхдлинный контекст Gemini, web search от GPT и другие расширенные возможности работают напрямую.
Почему разработчики выбирают Ofox?
- Три протокола: одновременная поддержка нативных протоколов OpenAI, Anthropic, Gemini — редкость в отрасли
- Безопасность данных: TLS 1.3 шифрование, без сохранения содержимого запросов/ответов
- Прозрачная тарификация: плати за использованное, мониторинг расхода и затрат в реальном времени
- Командный режим: один аккаунт — вся команда, индивидуальные API Key, детализация расхода
- Корпоративная поддержка: счета-фактуры, техническая поддержка
Анализ плюсов и минусов
| Параметр | Оценка |
|---|---|
| Стоимость | Низкая (обычно дешевле официальных, бесплатный баланс для новых пользователей) |
| Задержка | Низкая (узлы в Китае, 300-800 мс) |
| Покрытие моделей | Широкое (100+ моделей, один Key для всего) |
| Обслуживание | Минимальное (изменить одну строку base_url) |
| Подходит для | Абсолютное большинство сценариев — от индивидуальных разработчиков до команд |
Начните прямо сейчас: зарегистрируйтесь на Ofox.ai — бесплатный баланс для новых пользователей, оплата Alipay/WeChat. Документация для разработчиков →
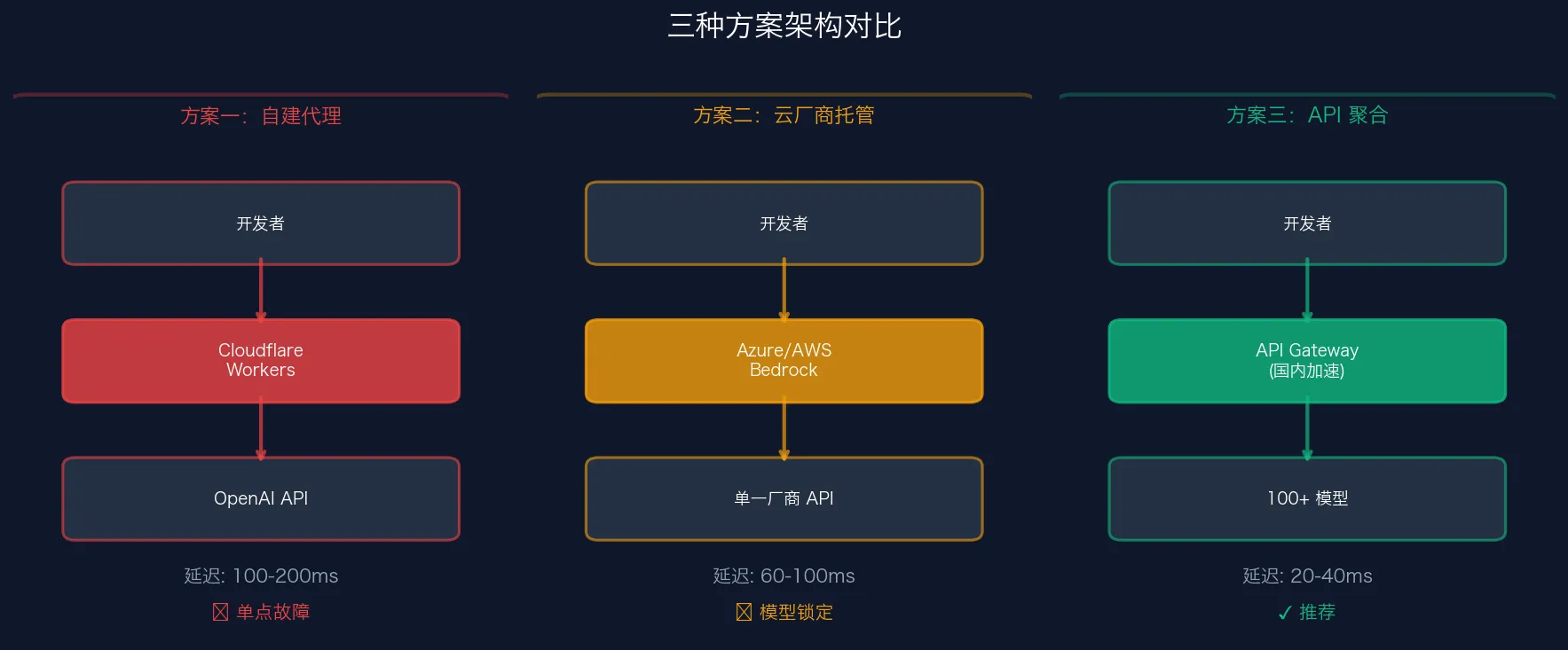
Сравнение трёх подходов
| Параметр | Самостоятельный прокси | Облачные сервисы | Агрегатор API |
|---|---|---|---|
| Сложность подключения | Средняя (развёртывание) | Средняя (несколько облаков) | Минимальная (изменить base_url) |
| Задержка первого байта | 5-10 секунд | 3-5 секунд | 300-800 мс |
| Покрытие моделей | Один вендор | 2-3 вендора | 100+ моделей |
| Способ оплаты | Зарубежная карта | Облачный биллинг | Alipay/WeChat |
| Месячная стоимость (~1M токенов) | ¥50-80 + сервер | ¥80-120 | ¥35-60 |
| Переключение моделей | Несколько прокси | Несколько SDK | Три нативных SDK |
| Обслуживание | Высокое | Среднее | Нулевое |
| Подходит для этапа | Прототипирование | Корпоративное соответствие | От прототипа до продакшена |
Как видно из таблицы, платформа-агрегатор выигрывает практически по всем параметрам — особенно для разработчиков, ищущих стабильный AI API с прямым доступом из Китая.
Цены AI API ведущих моделей в 2026 году
Актуальные цены на март 2026 (за миллион токенов, в долларах):
| Модель | Цена ввода | Цена вывода | Контекст | Особенности |
|---|---|---|---|---|
| GPT-5.2 | $1.75 | $14.00 | 256K | Новейший флагман OpenAI |
| GPT-4o | $2.50 | $10.00 | 128K | Оптимальное цена/качество |
| Claude Opus 4.6 | $15.00 | $75.00 | 200K | Сильнейшие рассуждения |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 200K | Лидер в коде |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | Сверхдлинный контекст |
| Gemini 3 Flash | $0.50 | $3.00 | 1M | Предельная экономия |
| DeepSeek V3.2 | $0.27 | $1.10 | 128K | Китайская модель, ультранизкая цена |
Совет по экономии: через агрегатор цены обычно ниже официальных — за счёт оптовых закупок и интеллектуального кэширования. Точные цены смотрите на сайте платформы. Актуальные цены Ofox →
Практика: полный туториал по вызову GPT / Claude / Gemini на Python
Ниже демонстрация подключения через нативные SDK трёх провайдеров через Ofox. Каждый пример включает обычный вызов и потоковый вывод. Зарегистрируйтесь на app.ofox.ai для получения API Key.
OpenAI SDK — GPT-5.2 Responses API
# SDK: openai v2.24.0
# Документация: https://platform.openai.com/docs/api-reference/responses
# Обновлено: 2026-03-03
from openai import OpenAI
client = OpenAI(
base_url="https://api.ofox.ai/v1",
api_key="your-ofox-api-key"
)
# Обычный вызов
response = client.responses.create(
model="openai/gpt-5.2",
input="Объясни одним предложением, что такое RAG",
)
print(response.output_text)
# Потоковый вывод
stream = client.responses.create(
model="openai/gpt-5.2",
input="Напиши Python-декоратор для кэширования функций",
stream=True,
)
for event in stream:
if event.type == "response.output_text.delta":
print(event.delta, end="", flush=True)Anthropic SDK — Claude Opus 4.6
# SDK: anthropic v0.84.0
# Документация: https://docs.anthropic.com/en/api/getting-started
# Обновлено: 2026-03-03
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="your-ofox-api-key"
)
# Обычный вызов
message = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "Объясни одним предложением, что такое RAG"}],
)
print(message.content[0].text)
# Потоковый вывод
with client.messages.stream(
model="claude-opus-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "Напиши Python-декоратор для кэширования функций"}],
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)Google GenAI SDK — Gemini 3 Flash
# SDK: google-genai v1.65.0
# Документация: https://googleapis.github.io/python-genai/
# Обновлено: 2026-03-03
from google import genai
client = genai.Client(
api_key="your-ofox-api-key",
http_options={"base_url": "https://api.ofox.ai/gemini"}
)
# Обычный вызов
response = client.models.generate_content(
model="google/gemini-3-flash-preview",
contents="Объясни одним предложением, что такое RAG",
)
print(response.text)
# Потоковый вывод
for chunk in client.models.generate_content_stream(
model="google/gemini-3-flash-preview",
contents="Напиши Python-декоратор для кэширования функций",
):
print(chunk.text, end="", flush=True)Три фрагмента кода демонстрируют ключевые различия SDK: названия интерфейсов, формат параметров и структура ответов полностью различны. Но через Ofox все они доступны из Китая с единой тарификацией — каждый SDK раскрывает полные возможности своего провайдера.
Хотите попробовать? Зарегистрируйтесь бесплатно и получите API Key (1 минута). Полная документация SDK и примеры на разных языках: документация Ofox для разработчиков.
Часто задаваемые вопросы (FAQ)
В: Нужна ли дополнительная сетевая настройка для GPT-5.2 API из Китая?
О: Нет. Через агрегатор прямой доступ работает из Китая без настроек. Узлы Alibaba Cloud / Volcano Cloud автоматически маршрутизируют запрос к ближайшему узлу, задержка первого байта 300-800 мс.
В: Безопасны ли данные на платформе-агрегаторе?
О: Надёжные агрегаторы используют TLS 1.3, не хранят содержимое запросов и ответов (только объём для тарификации). Ofox шифрует все данные без сохранения на диск, API Key настраиваются гранулярно. Для высокочувствительных корпоративных данных подойдёт Azure OpenAI с сертификацией соответствия.
В: Сколько кода менять при миграции с OpenAI на агрегатор?
О: Обычно — только base_url на адрес Ofox. Платформа совместима с нативными SDK OpenAI, Anthropic, Gemini со всеми фирменными функциями (Responses API, extended thinking, сверхдлинный контекст). Streaming, JSON Mode и другие расширенные функции полностью поддерживаются.
В: Какой AI API самый выгодный?
О: Зависит от сценария. Повседневные диалоги — GPT-4o или Claude Sonnet 4.6 (лучшее цена/качество); сложные рассуждения — Claude Opus 4.6 или GPT-5.2; сверхдлинные тексты — Gemini 3.1 Pro (2M контекст); ограниченный бюджет — DeepSeek V3.2 или Gemini 3 Flash. Через агрегатор можно гибко переключаться в одном проекте.
В: Сколько обычно бесплатного баланса?
О: Большинство агрегаторов дают бонус при регистрации — точную сумму смотрите на сайте. Используйте бесплатный баланс для отладки, после подтверждения качества — пополняйте через Alipay или WeChat Pay.
В: Какие ключевые преимущества Ofox?
О: Ofox — одна из немногих платформ с поддержкой трёх нативных протоколов (OpenAI, Anthropic, Gemini) — полноценное использование Claude extended thinking, сверхдлинного контекста Gemini и других уникальных функций, а не только «наименьший общий знаменатель» совместимости. Плюс командный режим — администратор регистрирует и пополняет, участники команды используют индивидуальные API Key с прозрачной детализацией расхода.
В: Есть ли корпоративные скидки?
О: Да. Ofox предлагает ступенчатое ценообразование — чем больше объём, тем ниже цена. Корпоративные клиенты получают персональную техподдержку, SLA и счета-фактуры. Подробности — в консоли Ofox.
В: Какие языки программирования поддерживаются?
О: Ofox совместим с нативными SDK OpenAI, Anthropic, Gemini — все три предоставляют официальные SDK для Python, TypeScript, Java, Go и других языков. Измените base_url в существующем SDK на адрес Ofox. Примеры на разных языках →
В: Как пополнить после бесплатного баланса?
О: В консоли Ofox — Alipay и WeChat Pay, расчёт в юанях, без минимума. Баланс доступен мгновенно, оплата по фактическому расходу токенов.
В: Как мониторить расход и затраты?
О: Консоль Ofox предоставляет дашборд реального времени: вызовы по модели, расход токенов, детализация затрат и задержка. Поддерживаются оповещения при низком балансе или аномальном суточном расходе — для контроля затрат на AI API.
Итоги и план действий
В 2026 году для разработчиков из Китая агрегатор API превратился из «временного решения» в «инфраструктуру по умолчанию». Единый интерфейс снижает стоимость переключения, прямой доступ из Китая решает проблему задержки, оплата в юанях устраняет платёжный барьер. Будь то прямой доступ к GPT из Китая или стабильный AI API-сервис — агрегатор на данный момент оптимальное решение.
Ваш следующий шаг:
- Получите API Key: бесплатная регистрация на Ofox.ai за 1 минуту
- Измените две строки кода:
base_urlнаhttps://api.ofox.ai/v1и ваш API Key - Отправьте первый запрос: используйте примеры кода из этой статьи для проверки
- Попробуйте другие модели: протестируйте Claude, Gemini, DeepSeek — найдите оптимальную для вашего сценария
- Подключите продакшен: после подтверждения качества — постепенно переводите рабочие API-вызовы
Начните за 5 минут:
- Бесплатный баланс для новых пользователей
- Без кредитной карты, Alipay/WeChat
- Совместимость с тремя нативными SDK OpenAI / Anthropic / Gemini
- 100+ моделей, прямой доступ из Китая
Бесплатная регистрация Ofox.ai → | Документация для разработчиков →
Рекомендуемые статьи
- Claude API — руководство по использованию из Китая — полный туториал подключения Claude Opus/Sonnet
- Gemini API — руководство по использованию из Китая — подключение Google Gemini
Справочные материалы
- OpenAI API — официальная документация — Responses API, Chat Completions и другие интерфейсы, дата обращения: 2026-03-03
- Anthropic Claude API — документация — руководство по подключению моделей Claude, дата обращения: 2026-03-03
- Google Gemini API — документация — google-genai SDK v1.65.0, дата обращения: 2026-03-03
- Azure OpenAI Service — цены — корпоративный управляемый сервис
- Ofox.ai — документация для разработчиков — быстрое подключение и примеры SDK, дата обращения: 2026-03-03
- LLM API Gateway: архитектура и оптимизация затрат — Alibaba Cloud — глубокий анализ AI API Gateway
Журнал проверки
Примеры кода проверены 2026-03-03 по следующим критериям:
| SDK | Пакет | Версия | Метод проверки | Результат |
|---|---|---|---|---|
| OpenAI | openai | v2.24.0 | PyPI + официальная документация | responses.create + output_text корректно |
| Anthropic | anthropic | v0.84.0 | PyPI + официальная документация | messages.create + content[0].text корректно |
google-genai | v1.65.0 | PyPI + документация Ofox | genai.Client(http_options) через Ofox работает |
Примечания:
- Три SDK независимы и несовместимы друг с другом, каждый следует нативному протоколу
http_options.base_urlGoogle GenAI SDK маршрутизируется через шлюз Ofox- ID моделей соответствуют маршрутизации Ofox (например,
openai/gpt-5.2,google/gemini-3-flash-preview)