LangChain: Claude, GPT, DeepSeek из Китая через API-агрегатор
Как вызывать Claude Sonnet 4.6, GPT-4.1, DeepSeek V3 через LangChain из Китая. Два параметра в ChatOpenAI, примеры кода Python, цепочки LCEL, переключение моделей и разбор ошибок.
Кратко
LangChain — популярный Python-фреймворк для создания AI-приложений, но прямое подключение к зарубежным API из Китая отличается высокой задержкой или недоступностью. Решение: через API-агрегатор с OpenAI-совместимым протоколом. В ChatOpenAI нужно изменить два параметра (base_url и api_key), чтобы вызывать Claude Sonnet 4.6, GPT-4.1, DeepSeek V3 и другие модели. Статья включает код на Python, примеры LCEL, переключение моделей и решение типичных ошибок.
Предыстория: типичные проблемы LangChain в Китае
Для разработчиков в Китае главная проблема LangChain — прямое подключение к зарубежным API крайне нестабильно. Типичные ошибки:
# Три самые распространённые ошибки
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='api.anthropic.com', port=443): Max retries exceeded
openai.APIConnectionError: Connection error.
httpx.ConnectError: [SSL: CERTIFICATE_VERIFY_FAILED]Причина проста: серверы API OpenAI (api.openai.com), Anthropic (api.anthropic.com), Google (generativelanguage.googleapis.com) расположены за рубежом, и прямое подключение из Китая часто приводит к:
- Таймаутам: сбой TCP- или SSL-рукопожатия, стандартный таймаут LangChain 60 секунд срабатывает ошибкой
- Обрывам потока: потоковая выдача прерывается посреди ответа, обработка partial response усложняется
- Высокой задержке: задержка первого байта (TTFT) 5-15 секунд, пользовательский опыт при streaming катастрофический
- Проблемам с квотами: регистрация и оплата в OpenAI/Anthropic неудобны для китайских разработчиков
Ключевое решение: единый уровень API-агрегации
Самое простое и стабильное решение — добавить промежуточный слой в виде API-агрегатора:
Ваш код LangChain
↓
API-агрегатор (узлы в Китае, низкая задержка)
↓ (маршрутизация запросов)
Claude API / OpenAI API / Gemini API / DeepSeek API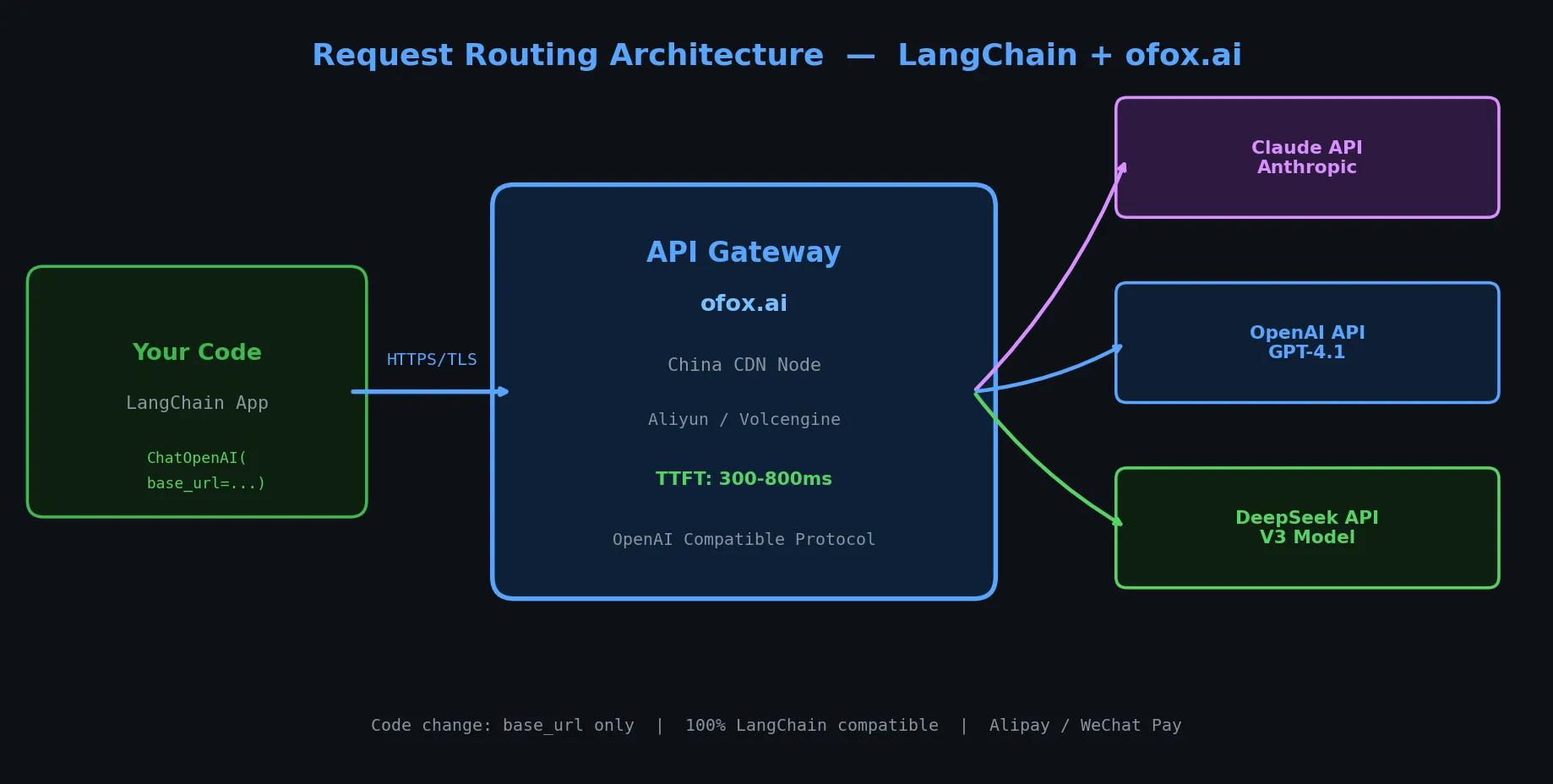
Ключевые преимущества такой архитектуры:
| Характеристика | Прямое подключение | API-агрегатор |
|---|---|---|
| Стабильность сети в Китае | Частые таймауты и обрывы | Ускорение через облачные узлы |
| Задержка первого байта (TTFT) | 5-15 секунд | 300-800 мс |
| Способ оплаты | Зарубежная банковская карта | Alipay/WeChat, рубли, крипто |
| Переключение моделей | Отдельная регистрация у каждого провайдера | Один API Key |
| Совместимость с LangChain | Нативная поддержка | 100% совместимость, меняется только base_url |
На примере Ofox — совместим с протоколом OpenAI, поэтому изменений в коде LangChain минимум.
Быстрый старт: первый диалог с Claude за пять минут
1. Установка зависимостей
# langchain-openai >= 0.2.0 | Документация: https://python.langchain.com/docs/integrations/chat/openai
pip install -U langchain langchain-openai langchain-anthropic2. Вызов Claude через OpenAI-совместимый протокол
Агрегаторы вроде Ofox предоставляют единый OpenAI-совместимый интерфейс (/v1/chat/completions), поэтому можно использовать ChatOpenAI, изменив только base_url и api_key:
# SDK: langchain-openai v0.3+ / документация: https://python.langchain.com/docs/integrations/chat/openaifrom langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# Меняются только два параметра, всё остальное — без изменений
llm = ChatOpenAI(
model="anthropic/claude-sonnet-4.6", # Полный список моделей: ofox.ai/ru/docs/develop
base_url="https://api.ofox.ai/v1",
api_key="your-ofox-api-key", # Получите в консоли Ofox
temperature=0.7,
max_tokens=2048,
)
# Обычный вызов
response = llm.invoke([HumanMessage(content="Объясни одним предложением, что такое LangChain")])
print(response.content)
# Вывод: LangChain — это фреймворк с открытым исходным кодом для создания приложений на базе LLM...
# Потоковый вывод
for chunk in llm.stream([HumanMessage(content="Напиши хайку о программировании")]):
print(chunk.content, end="", flush=True)3. Управление ключами через переменные окружения (рекомендуется)
import os
from langchain_openai import ChatOpenAI
# Рекомендуется хранить ключи в .env или переменных окружения, не хардкодить
llm = ChatOpenAI(
model=os.getenv("LLM_MODEL", "anthropic/claude-sonnet-4.6"),
base_url=os.getenv("OPENAI_API_BASE", "https://api.ofox.ai/v1"),
api_key=os.getenv("OFOX_API_KEY"),
)Соответствующий файл .env:
OFOX_API_KEY=your-ofox-api-key-here
LLM_MODEL=anthropic/claude-sonnet-4.6
OPENAI_API_BASE=https://api.ofox.ai/v1Переменные окружения позволяют переключать модели между средами и исключают утечку ключей в репозиторий.
Конфигурация нескольких моделей: Claude, GPT, DeepSeek
Через API-агрегатор один и тот же код работает со всеми основными моделями:
# SDK: langchain-openai v0.3+ / документация: https://python.langchain.com/docs/integrations/chat/openaifrom langchain_openai import ChatOpenAI
BASE_URL = "https://api.ofox.ai/v1"
API_KEY = "your-ofox-api-key"
# Claude Sonnet 4.6 — отличные общие способности, подходит для сложных рассуждений и длинных документов
claude_sonnet = ChatOpenAI(
model="anthropic/claude-sonnet-4.6",
base_url=BASE_URL,
api_key=API_KEY,
)
# Claude Opus 4.6 — сильнейшие рассуждения, для задач глубокого анализа
claude_opus = ChatOpenAI(
model="anthropic/claude-opus-4.6",
base_url=BASE_URL,
api_key=API_KEY,
)
# GPT-4.1 — флагман OpenAI, отличная работа с кодом и инструментами
gpt4 = ChatOpenAI(
model="openai/gpt-4.1",
base_url=BASE_URL,
api_key=API_KEY,
)
# DeepSeek V3 — китайская модель, очень низкая цена, сильное понимание китайского
deepseek = ChatOpenAI(
model="deepseek/deepseek-chat",
base_url=BASE_URL,
api_key=API_KEY,
)
# Haiku 4.5 — сверхбыстрая и дешёвая, подходит для классификации и извлечения данных
claude_haiku = ChatOpenAI(
model="anthropic/claude-haiku-4.5",
base_url=BASE_URL,
api_key=API_KEY,
)Полный список моделей — на ofox.ai/ru/docs/develop.
Сравнение возможностей и цен основных моделей 2026 года
| Модель | Сильные стороны | Цена ввода | Цена вывода | Задержка в Китае |
|---|---|---|---|---|
| Claude Sonnet 4.6 | Общие рассуждения, длинные документы | $3 / 1M токенов | $15 / 1M токенов | 300-600 мс |
| Claude Opus 4.6 | Самые сложные задачи | $5 / 1M токенов | $25 / 1M токенов | 400-800 мс |
| GPT-4.1 | Код, вызов инструментов | $2 / 1M токенов | $8 / 1M токенов | 300-600 мс |
| DeepSeek V3 | Китайский язык, низкая стоимость | Очень низкая | Очень низкая | <200 мс |
| Claude Haiku 4.5 | Лёгкая классификация | $1 / 1M токенов | $5 / 1M токенов | 200-400 мс |
Цены приведены для справки.
Цепочки LCEL на практике
LangChain 0.3+ рекомендует использовать LCEL (синтаксис с |) для построения цепочек:
Базовый пример: Prompt → Model → Parser
# SDK: langchain>=0.3.0 / документация: https://python.langchain.com/docs/concepts/lcelfrom langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(
model="anthropic/claude-sonnet-4.6",
base_url="https://api.ofox.ai/v1",
api_key="your-ofox-api-key",
)
# Создаём шаблон промпта
prompt = ChatPromptTemplate.from_messages([
("system", "Ты профессиональный {role}. Отвечай кратко на русском языке."),
("human", "{question}"),
])
# Конвейер LCEL: Prompt → LLM → строковый вывод
chain = prompt | llm | StrOutputParser()
# Вызов
result = chain.invoke({
"role": "эксперт по Python",
"question": "Объясни разницу между asyncio и многопоточностью. Когда что использовать?"
})
print(result)Продвинутый пример: структурированный вывод
# SDK: langchain>=0.3.0, pydantic>=2.0from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from typing import List
llm = ChatOpenAI(
model="anthropic/claude-sonnet-4.6",
base_url="https://api.ofox.ai/v1",
api_key="your-ofox-api-key",
)
# Определяем структуру вывода
class CodeReview(BaseModel):
issues: List[str] = Field(description="Список найденных проблем в коде")
suggestions: List[str] = Field(description="Рекомендации по улучшению")
severity: str = Field(description="Серьёзность: low/medium/high")
# Привязываем структурированный вывод
structured_llm = llm.with_structured_output(CodeReview)
prompt = ChatPromptTemplate.from_messages([
("system", "Ты опытный код-ревьюер. Проведи ревью следующего кода."),
("human", "Код:\n```python\n{code}\n```"),
])
chain = prompt | structured_llm
result = chain.invoke({
"code": """
def get_user(id):
sql = f"SELECT * FROM users WHERE id = {id}"
return db.execute(sql)
"""
})
print(f"Серьёзность: {result.severity}")
print(f"Проблемы: {result.issues}")
print(f"Рекомендации: {result.suggestions}")
# Вывод:
# Серьёзность: high
# Проблемы: ['Риск SQL-инъекции', 'Отсутствует валидация параметров', 'Нет обработки ошибок']
# Рекомендации: ['Использовать параметризованные запросы', 'Добавить проверку типа id', 'Добавить try-except для обработки ошибок БД']Асинхронные параллельные вызовы
# SDK: langchain>=0.3.0import asyncio
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(
model="anthropic/claude-haiku-4.5", # Для лёгких задач — Haiku: быстрее и дешевле
base_url="https://api.ofox.ai/v1",
api_key="your-ofox-api-key",
)
prompt = ChatPromptTemplate.from_messages([
("human", "Опиши ключевое преимущество продукта пятью словами: {product}"),
])
chain = prompt | llm | StrOutputParser()
async def batch_analyze(products: list[str]):
"""Параллельный анализ нескольких продуктов"""
tasks = [chain.ainvoke({"product": p}) for p in products]
results = await asyncio.gather(*tasks)
return dict(zip(products, results))
# Параллельное выполнение 5 задач — в 4-5 раз быстрее последовательного
products = ["Claude API", "GPT-4", "DeepSeek", "Gemini", "LangChain"]
results = asyncio.run(batch_analyze(products))
for product, keywords in results.items():
print(f"{product}: {keywords}")Продвинутый уровень: динамическое переключение моделей
В реальных проектах для разных задач подходят разные модели. LangChain позволяет переключать их на лету:
# SDK: langchain>=0.3.0 / документация: https://python.langchain.com/docs/how_to/configurefrom langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import ConfigurableField
BASE_CONFIG = {"base_url": "https://api.ofox.ai/v1", "api_key": "your-ofox-api-key"}
# По умолчанию Sonnet, с возможностью переключения в рантайме
llm = ChatOpenAI(model="anthropic/claude-sonnet-4.6", **BASE_CONFIG).configurable_alternatives(
ConfigurableField(id="model"),
default_key="sonnet",
opus=ChatOpenAI(model="anthropic/claude-opus-4.6", **BASE_CONFIG),
haiku=ChatOpenAI(model="anthropic/claude-haiku-4.5", **BASE_CONFIG),
gpt4=ChatOpenAI(model="openai/gpt-4.1", **BASE_CONFIG),
deepseek=ChatOpenAI(model="deepseek/deepseek-chat", **BASE_CONFIG),
)
prompt = ChatPromptTemplate.from_messages([("human", "{question}")])
chain = prompt | llm | StrOutputParser()
# По умолчанию — Sonnet
response = chain.invoke({"question": "Проанализируй временную сложность этого кода..."})
# Переключение на Opus для сложных задач
response = chain.with_config(configurable={"model": "opus"}).invoke({
"question": "Спроектируй архитектуру распределённой системы планирования задач..."
})
# Переключение на Haiku для простой классификации (дёшево и быстро)
response = chain.with_config(configurable={"model": "haiku"}).invoke({
"question": "Определи тональность отзыва: positive/negative/neutral"
})Практический кейс: RAG-система ответов по документам
Пример RAG-системы с использованием FAISS для поиска по документам:
# SDK: langchain>=0.3.0, langchain-community>=0.3.0, faiss-cpufrom langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
BASE_URL = "https://api.ofox.ai/v1"
API_KEY = "your-ofox-api-key"
# 1. Векторизация документов (модель эмбеддингов)
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small", # или openai/text-embedding-3-small
base_url=BASE_URL,
api_key=API_KEY,
)
# 2. Загрузка и разбиение документов
loader = TextLoader("your_document.txt", encoding="utf-8")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
# 3. Создание векторной базы
vectorstore = FAISS.from_documents(chunks, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 4. Построение QA-цепочки
llm = ChatOpenAI(
model="anthropic/claude-sonnet-4.6",
base_url=BASE_URL,
api_key=API_KEY,
)
prompt = ChatPromptTemplate.from_messages([
("system", "Ответь на вопрос на основе приведённого контекста. Если ответа в контексте нет, скажи об этом прямо.\n\nКонтекст: {context}"),
("human", "{question}"),
])
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Задаём вопрос
answer = rag_chain.invoke("Какова политика возврата товаров?")
print(answer)Типичные ошибки и их устранение
При возникновении проблем проверяйте в следующем порядке:
1. AuthenticationError: 401
# Проверьте, правильно ли передан API Key
print(llm.openai_api_key) # Только для локальной отладки, не выводите в логи
# Частая причина: переменная окружения OPENAI_API_KEY перезаписывает ваш ключ
# Решение: явно передавайте параметр api_key
llm = ChatOpenAI(model="...", base_url="...", api_key="your-key")2. openai.NotFoundError: model not found
# Проверьте формат идентификатора модели
# Обычно формат: provider/model-name
# Сверяйтесь со списком моделей на ofox.ai/ru/docs/develop3. Connection timeout / SSL Error
import httpx
from langchain_openai import ChatOpenAI
# Увеличьте таймаут (по умолчанию 60 с, для streaming можно увеличить)
llm = ChatOpenAI(
model="anthropic/claude-sonnet-4.6",
base_url="https://api.ofox.ai/v1",
api_key="your-key",
http_client=httpx.Client(timeout=120.0),
)4. RateLimitError: 429
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="anthropic/claude-sonnet-4.6",
base_url="https://api.ofox.ai/v1",
api_key="your-key",
max_retries=3, # Встроенный механизм повторных попыток LangChain
)Часто задаваемые вопросы (FAQ)
В: Нужна ли специальная настройка сети для вызова Claude/GPT API через LangChain из Китая?
Нет. При подключении через API-агрегатор достаточно изменить base_url — прямой доступ из Китая, задержка первого байта 300-800 мс.
В: Сколько кода нужно менять при переходе с официального API на агрегатор?
В ChatOpenAI меняются два параметра: base_url и api_key. Все цепочки LangChain, Agent, RAG — без изменений.
В: Поддерживает ли LangChain одновременную настройку нескольких провайдеров?
Да. В одной цепочке LCEL можно переключать модели через configurable_alternatives. Также можно создать несколько экземпляров ChatOpenAI для разных моделей.
В: В каком формате указываются модели на агрегаторе?
В формате provider/model-name, например anthropic/claude-sonnet-4.6, openai/gpt-4.1, deepseek/deepseek-chat. Актуальный список — на ofox.ai/ru/docs/develop.
В: Какие версии LangChain требуются?
Рекомендуется langchain>=0.3.0, langchain-openai>=0.2.0. Обновить: pip install -U langchain langchain-openai.
Итоги
ChatOpenAI+ кастомныйbase_urlпокрывает 90% сценариев — один код для всех моделей- Выбирайте модель по задаче: лёгкие задачи — Haiku/DeepSeek, сложные рассуждения — Sonnet/Opus, код — GPT-4.1
- LCEL +
configurable_alternativesдля динамического переключения моделей - Асинхронные параллельные вызовы (
asyncio.gather) для пакетных задач — в 4-5 раз быстрее последовательных
Полезные ссылки
- Документация LangChain ChatOpenAI
- Концепция LCEL в LangChain
- Anthropic Python SDK
- Документация Ofox API — список моделей и инструкции по подключению