OpenClaw: сравнение 8 моделей — GPT-5/Claude/Gemini/DeepSeek, кто лучший? (2026)
Кратко
В 2026 году AI-модели переживают бурный расцвет, и пользователи OpenClaw сталкиваются с приятной проблемой: моделей слишком много — какую выбрать? В этой статье мы практически протестировали 8 моделей — GPT-5.4, GPT-4o, Claude Opus 4.6, Claude Sonnet 4.6, Gemini 3 Pro, Gemini 3 Flash, DeepSeek V3.2, Qwen3.5 — по пяти параметрам: рассуждения, генерация кода, вызов инструментов, скорость отклика, стоимость. Даём полную сводную таблицу, матрицу сценариев и рейтинг по соотношению цена/качество. Без маркетинга — только данные.
Содержание
- Методология тестирования
- Обзор 8 моделей
- Параметр 1: Рассуждения
- Параметр 2: Генерация кода
- Параметр 3: Вызов инструментов
- Параметр 4: Скорость отклика
- Параметр 5: Стоимость
- Общая сводная таблица по пяти параметрам
- Матрица рекомендаций по сценариям
- Рейтинг по соотношению цена/качество
- Оптимальные конфигурации моделей для OpenClaw
- Часто задаваемые вопросы (FAQ)
- Итоги
Методология тестирования
Сначала — о методике, чтобы не было вопросов «оценки придуманы».
Тестовая среда
- Платформа: OpenClaw v2.4, все модели подключены через Ofox API
- Период: март 2026
- Сеть: узел Alibaba Cloud в Китае, для исключения сетевых артефактов
- Temperature: единообразно 0 для воспроизводимости результатов
Параметры оценки
| Параметр | Вес | Содержание тестов |
|---|---|---|
| Рассуждения | 25% | Математика, логика, многошаговый анализ |
| Генерация кода | 25% | Генерация функций Python/JS/Go, исправление багов, рефакторинг |
| Вызов инструментов | 20% | Точность Function Calling, оркестрация нескольких инструментов |
| Скорость отклика | 15% | Задержка до первого токена, пропускная способность |
| Стоимость | 15% | Цена за миллион токенов |
Максимум по каждому параметру — 10 баллов, итоговая оценка — средневзвешенная.
Тестовый набор
Для каждого параметра подготовлено 30+ тестовых кейсов трёх уровней сложности: простой, средний, сложный. Мы не используем публичные бенчмарки (их данные давно попали в обучающие выборки моделей) — тесты построены на реальных бизнес-задачах.
Обзор 8 моделей
Краткое знакомство с восемью участниками:
| Модель | Разработчик | Позиционирование | Контекстное окно | Дата выпуска |
|---|---|---|---|---|
| GPT-5.4 | OpenAI | Флагман рассуждений | 1M токенов | 02.2026 |
| GPT-4o | OpenAI | Мультимодальная, оптимальная цена | 128K токенов | 05.2025 |
| Claude Opus 4.6 | Anthropic | Флагман-универсал | 1M токенов | 01.2026 |
| Claude Sonnet 4.6 | Anthropic | Универсал, отличная цена | 200K токенов | 01.2026 |
| Gemini 3 Pro | Флагман для длинных текстов | 2M токенов | 02.2026 | |
| Gemini 3 Flash | Сверхбыстрая, сверхдешёвая | 1M токенов | 01.2026 | |
| DeepSeek V3.2 | DeepSeek | Лучшая цена среди китайских | 128K токенов | 01.2026 |
| Qwen3.5 | Alibaba Cloud | Китайская универсальная | 128K токенов | 02.2026 |
Три эшелона:
- Флагманский: GPT-5.4, Claude Opus 4.6, Gemini 3 Pro — потолок возможностей, потолок цен
- Оптимальный по цене: GPT-4o, Claude Sonnet 4.6 — 80% возможностей за 30% цены
- Экономичный: Gemini 3 Flash, DeepSeek V3.2, Qwen3.5 — дёшево и для повседневных задач достаточно
Параметр 1: Рассуждения
Способность к рассуждению определяет, может ли модель «разобраться» в сложной задаче. Тестировались: математические вычисления, логические рассуждения, причинно-следственный анализ, многошаговое планирование.
Результаты
| Модель | Математика | Логика | Причинный анализ | Многошаговое планирование | Итого |
|---|---|---|---|---|---|
| GPT-5.4 | 9,5 | 9,5 | 9,0 | 9,5 | 9,5 |
| Claude Opus 4.6 | 9,0 | 9,5 | 9,5 | 9,5 | 9,5 |
| Gemini 3 Pro | 9,0 | 8,5 | 8,5 | 8,0 | 8,5 |
| Claude Sonnet 4.6 | 8,0 | 8,5 | 8,5 | 8,0 | 8,0 |
| GPT-4o | 8,0 | 8,0 | 8,0 | 8,0 | 8,0 |
| DeepSeek V3.2 | 8,5 | 8,0 | 7,5 | 7,5 | 8,0 |
| Qwen3.5 | 8,0 | 7,5 | 7,5 | 7,5 | 7,5 |
| Gemini 3 Flash | 7,0 | 7,0 | 7,0 | 6,5 | 7,0 |
Ключевые выводы
- GPT-5.4 и Claude Opus 4.6 делят первое место, но с разными акцентами: GPT-5.4 сильнее в математических рассуждениях, Opus стабильнее в длинных причинно-следственных цепочках и многошаговом планировании
- DeepSeek V3.2 выделяется в математике (8,5 балла) — даже превосходит GPT-4o, что связано с глубокой оптимизацией команды DeepSeek в области математических рассуждений
- Gemini 3 Flash слабее в рассуждениях — на сложных логических задачах часто ошибается, но для простых рассуждений вполне годится
Параметр 2: Генерация кода
Одно из самых востребованных применений OpenClaw — написание кода. Тестировались: генерация функций, исправление багов, рефакторинг, написание тестов.
Результаты
| Модель | Генерация функций | Исправление багов | Рефакторинг | Написание тестов | Итого |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 9,5 | 9,5 | 9,5 | 9,0 | 9,5 |
| GPT-5.4 | 9,5 | 9,0 | 9,0 | 9,0 | 9,0 |
| Claude Sonnet 4.6 | 9,0 | 8,5 | 8,5 | 8,5 | 8,5 |
| Gemini 3 Pro | 8,5 | 8,0 | 8,0 | 8,0 | 8,0 |
| DeepSeek V3.2 | 8,0 | 8,0 | 7,5 | 7,5 | 7,5 |
| GPT-4o | 8,0 | 7,5 | 7,5 | 7,5 | 7,5 |
| Qwen3.5 | 8,0 | 7,5 | 7,0 | 7,5 | 7,5 |
| Gemini 3 Flash | 7,0 | 6,5 | 6,5 | 6,5 | 6,5 |
Ключевые выводы
- Claude Opus 4.6 — король кода: будь то генерация с нуля, исправление багов или рефакторинг — качество кода неизменно наивысшее. Глубина понимания контекста кода заметно превосходит конкурентов
- Claude Sonnet 4.6 — впечатляющее соотношение цена/качество: 8,5 балла за код при цене в пять раз ниже Opus
- DeepSeek V3.2 и GPT-4o наравне по коду, но DeepSeek значительно дешевле
Параметр 3: Вызов инструментов
Вызов инструментов (Function Calling) — ключевая способность AI Agent: может ли модель правильно определить нужный инструмент, передать верные параметры, обработать результат.
Результаты
| Модель | Один инструмент | Оркестрация нескольких | Точность параметров | Обработка ошибок | Итого |
|---|---|---|---|---|---|
| GPT-5.4 | 10,0 | 9,5 | 9,5 | 9,0 | 9,5 |
| Claude Opus 4.6 | 9,5 | 9,0 | 9,0 | 9,0 | 9,0 |
| Claude Sonnet 4.6 | 9,0 | 8,5 | 8,5 | 8,0 | 8,5 |
| Gemini 3 Pro | 9,0 | 8,5 | 8,0 | 8,0 | 8,5 |
| GPT-4o | 9,0 | 8,0 | 8,5 | 7,5 | 8,0 |
| DeepSeek V3.2 | 8,0 | 7,0 | 7,5 | 7,0 | 7,5 |
| Qwen3.5 | 8,0 | 7,0 | 7,0 | 6,5 | 7,0 |
| Gemini 3 Flash | 7,5 | 6,5 | 7,0 | 6,5 | 7,0 |
Ключевые выводы
- GPT-5.4 — лидер по вызову инструментов: накопленный OpenAI опыт в Function Calling действительно глубок — формат параметров практически безошибочный
- Линейка Claude — близкое второе место, особенно хороша в оркестрации нескольких инструментов (одновременный вызов, принятие решений по результатам)
- Заметное отставание китайских моделей: DeepSeek V3.2 и Qwen3.5 при оркестрации нескольких инструментов допускают ошибки — пропуск параметров, путаница в порядке вызовов. Это главная слабость китайских моделей в сценариях AI Agent
Параметр 4: Скорость отклика
OpenClaw при выполнении задач обращается к модели многократно — задержка каждого вызова накапливается. Измерялись задержка до первого токена (TTFT) и пропускная способность (tokens/s).
Результаты
| Модель | Задержка до первого токена | Пропускная способность (tokens/s) | Оценка скорости |
|---|---|---|---|
| Gemini 3 Flash | ~0,3 с | ~180 | 9,5 |
| GPT-4o | ~0,5 с | ~120 | 9,0 |
| Claude Sonnet 4.6 | ~0,6 с | ~110 | 8,5 |
| DeepSeek V3.2 | ~0,8 с | ~100 | 8,0 |
| Qwen3.5 | ~0,8 с | ~95 | 8,0 |
| Gemini 3 Pro | ~1,0 с | ~80 | 7,5 |
| GPT-5.4 | ~1,5 с | ~60 | 6,5 |
| Claude Opus 4.6 | ~1,8 с | ~50 | 6,0 |
Примечание: данные получены через узел ускорения Ofox в Китае. При прямом подключении к зарубежным API задержка будет выше.
Ключевые выводы
- Gemini 3 Flash — абсолютный чемпион по скорости: первый токен за 0,3 секунды, пропускная способность 180 tokens/s — для простых задач ощущение мгновенного отклика
- Флагманские модели заметно медленнее: GPT-5.4 и Claude Opus 4.6 работают втрое медленнее Flash-моделей. Для сложных задач ожидание неизбежно, но для простых — флагман не нужен
- DeepSeek V3.2 — хорошая скорость для своей цены: учитывая стоимость, это отличный результат
Параметр 5: Стоимость
Стоимость напрямую влияет на желание использовать OpenClaw в долгосрочной перспективе. Цены приведены в $/млн токенов (по официальным тарифам провайдеров).
Сравнение цен
| Модель | Ввод ($/M токенов) | Вывод ($/M токенов) | Примерная общая стоимость | Оценка |
|---|---|---|---|---|
| Gemini 3 Flash | ~$0,15 | ~$0,60 | Крайне низкая | 10,0 |
| DeepSeek V3.2 | ~$0,27 | ~$1,10 | Крайне низкая | 9,5 |
| Qwen3.5 | ~$0,40 | ~$1,20 | Очень низкая | 9,0 |
| GPT-4o | ~$2,50 | ~$10,00 | Средняя | 7,0 |
| Claude Sonnet 4.6 | ~$3,00 | ~$15,00 | Средняя | 6,5 |
| Gemini 3 Pro | ~$2,50 | ~$10,00 | Средняя | 7,0 |
| GPT-5.4 | ~$10,00 | ~$30,00 | Выше средней | 4,5 |
| Claude Opus 4.6 | ~$15,00 | ~$75,00 | Высокая | 3,5 |
Примечание: цены по данным провайдеров на март 2026 года. Фактические расходы могут отличаться за счёт попадания в кэш, пакетных скидок и т.д. Через Ofox цены близки к официальным.
Ключевые выводы
- Gemini 3 Flash и DeepSeek V3.2 — чемпионы по стоимости: в 50–100 раз дешевле флагманских моделей
- Claude Opus 4.6 — самый дорогой: $75/M токенов на выводе, при интенсивном использовании месячный счёт легко превысит тысячу юаней. Но если вам нужен наилучший код — оно того стоит
- Средний эшелон (Sonnet/GPT-4o/Gemini Pro) — близкие цены: выбор здесь определяется скорее возможностями, а не ценой
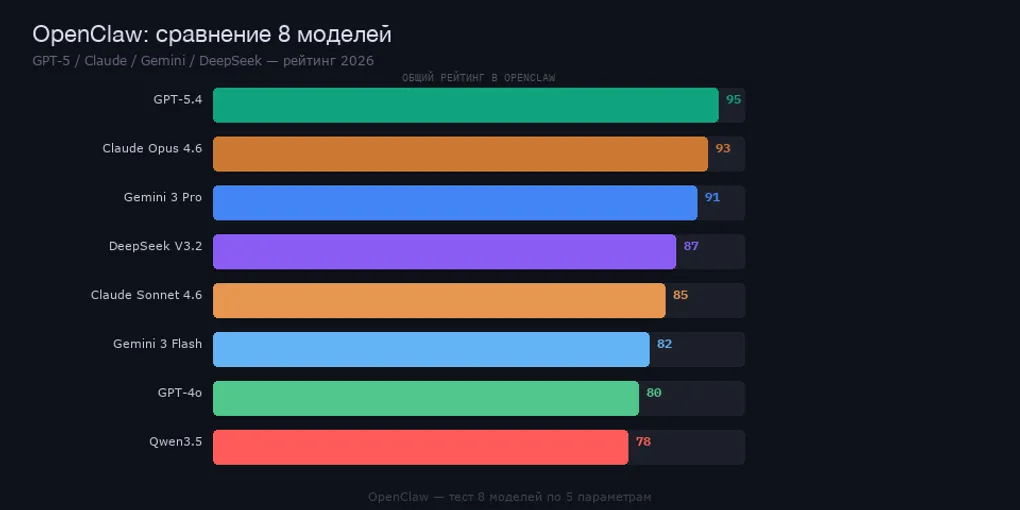
Общая сводная таблица по пяти параметрам
Самый важный раздел. Полные оценки и взвешенный итог по всем 8 моделям:
| Модель | Рассуждения (25%) | Код (25%) | Инструменты (20%) | Скорость (15%) | Стоимость (15%) | Итого |
|---|---|---|---|---|---|---|
| Claude Opus 4.6 | 9,5 | 9,5 | 9,0 | 6,0 | 3,5 | 8,0 |
| GPT-5.4 | 9,5 | 9,0 | 9,5 | 6,5 | 4,5 | 8,0 |
| Claude Sonnet 4.6 | 8,0 | 8,5 | 8,5 | 8,5 | 6,5 | 8,0 |
| GPT-4o | 8,0 | 7,5 | 8,0 | 9,0 | 7,0 | 7,9 |
| Gemini 3 Pro | 8,5 | 8,0 | 8,5 | 7,5 | 7,0 | 8,0 |
| DeepSeek V3.2 | 8,0 | 7,5 | 7,5 | 8,0 | 9,5 | 8,0 |
| Qwen3.5 | 7,5 | 7,5 | 7,0 | 8,0 | 9,0 | 7,7 |
| Gemini 3 Flash | 7,0 | 6,5 | 7,0 | 9,5 | 10,0 | 7,7 |
Как читать таблицу:
- Если важен только потолок возможностей: Claude Opus 4.6 и GPT-5.4 делят первое место
- Если важно соотношение цена/качество: Claude Sonnet 4.6 и DeepSeek V3.2 — оптимальный выбор
- Если нужна минимальная цена: Gemini 3 Flash — самая дешёвая при достаточном базовом уровне
Матрица рекомендаций по сценариям
Какую модель использовать для какого сценария — сводная таблица:
| Сценарий | Первый выбор | Альтернатива | Причина |
|---|---|---|---|
| Сложная генерация / рефакторинг кода | Claude Opus 4.6 | GPT-5.4 | Наивысшее качество кода |
| Математика / логические рассуждения | GPT-5.4 | Claude Opus 4.6 | GPT чуть сильнее в математике |
| Повседневные офисные задачи | Claude Sonnet 4.6 | GPT-4o | Достаточные возможности, разумная цена |
| Мультиинструментальные Agent-задачи | GPT-5.4 | Claude Opus 4.6 | Наиточнейший вызов инструментов |
| Создание контента на китайском | DeepSeek V3.2 | Qwen3.5 | Отличный китайский, дёшево |
| Высокочастотные простые вопросы | Gemini 3 Flash | DeepSeek V3.2 | Максимальная скорость, минимальная цена |
| Анализ очень длинных документов | Gemini 3 Pro | Claude Opus 4.6 | Контекст 2 млн токенов |
| Мультимодальность (понимание изображений) | GPT-4o | Gemini 3 Pro | Наиболее сбалансированные мультимодальные возможности |
| Крайне ограниченный бюджет | DeepSeek V3.2 | Gemini 3 Flash | Минимальная цена |
| Автоматизация 24/7 | Claude Sonnet 4.6 | GPT-4o | Стабильная, быстрая, не слишком дорогая |
Рейтинг по соотношению цена/качество
Соотношение цена/качество = возможности / стоимость. Рейтинг учитывает, сколько возможностей вы получаете на каждый потраченный рубль:
| Место | Модель | Оценка возможностей | Оценка стоимости | Индекс цена/качество | Комментарий |
|---|---|---|---|---|---|
| 1 | DeepSeek V3.2 | 7,8 | 9,5 | ★★★★★ | Гордость китайского AI — в 50 раз дешевле флагманов при достаточных возможностях |
| 2 | Gemini 3 Flash | 7,2 | 10,0 | ★★★★★ | Предельная дешевизна, лучший выбор для простых задач |
| 3 | Claude Sonnet 4.6 | 8,3 | 6,5 | ★★★★☆ | Сильнейший в среднем сегменте — и код, и рассуждения |
| 4 | Qwen3.5 | 7,5 | 9,0 | ★★★★☆ | Китайский универсал с поддержкой экосистемы Alibaba |
| 5 | GPT-4o | 7,9 | 7,0 | ★★★★☆ | Классика OpenAI, хорошая мультимодальность |
| 6 | Gemini 3 Pro | 8,1 | 7,0 | ★★★☆☆ | Уникальный сверхдлинный контекст, но чуть дороговат |
| 7 | GPT-5.4 | 8,5 | 4,5 | ★★★☆☆ | Один из сильнейших, но окупается только на сложных задачах |
| 8 | Claude Opus 4.6 | 8,8 | 3,5 | ★★☆☆☆ | Потолок возможностей, удар по кошельку — используйте по необходимости |
Вывод очевиден: самое дорогое — не значит лучшее. DeepSeek V3.2 и Gemini 3 Flash далеко впереди по соотношению цена/качество. 80% повседневных задач — их территория. Флагманские модели — для действительно сложных случаев.
Оптимальные конфигурации моделей для OpenClaw
На основе тестов — три варианта конфигурации для разных бюджетов:
Вариант 1: Флагманская конфигурация (бюджет 500+ юаней/мес.)
Primary: Claude Opus 4.6 # Основная модель — лучший код и рассуждения
Secondary: GPT-5.4 # Резерв для математики и вызова инструментов
Fallback: Claude Sonnet 4.6 # Деградация для простых задачПодходит для: профессиональных разработчиков, команд с высокими требованиями к качеству кода.
Вариант 2: Сбалансированная конфигурация (100–300 юаней/мес.) — рекомендуемая
Primary: Claude Sonnet 4.6 # Повседневная рабочая лошадка, универсальные возможности
Secondary: GPT-4o # Для мультимодальных задач
Economy: DeepSeek V3.2 # Экономия на простых задачах
Fallback: Gemini 3 Flash # Последний рубеж — никогда не останавливаетсяПодходит для: большинства разработчиков и команд — баланс возможностей и стоимости.
Вариант 3: Экономичная конфигурация (до 100 юаней/мес.)
Primary: DeepSeek V3.2 # Основная — дёшево и функционально
Secondary: Qwen3.5 # Дополнение для задач на китайском
Fallback: Gemini 3 Flash # Резерв для простейших задачПодходит для: индивидуальных пользователей, ограниченный бюджет, преимущественно задачи на китайском.
Все перечисленные модели доступны через Ofox по единому интерфейсу — зарегистрируйте один аккаунт, получите один API Key, укажите https://api.ofox.ai/v1 как base_url в конфигурации OpenClaw — и переключайтесь между моделями свободно. Не нужно отдельно регистрироваться в OpenAI, Anthropic, Google и DeepSeek, не нужно разбираться с зарубежными платежами.
Часто задаваемые вопросы (FAQ)
Какая модель лучше для OpenClaw?
Однозначного ответа нет — зависит от сценария. По совокупности возможностей лидируют Claude Opus 4.6 и GPT-5.4, лучшее соотношение цена/качество — у DeepSeek V3.2, самая быстрая — Gemini 3 Flash. Рекомендуем использовать матрицу сценариев из этой статьи.
Достаточно ли китайских моделей для AI Agent?
Для повседневных задач — да, но вызов инструментов — слабое место. DeepSeek V3.2 и Qwen3.5 хорошо справляются с одиночными вызовами, но в оркестрации нескольких инструментов и формировании сложных параметров уступают GPT/Claude. Рекомендация: китайские модели — основная экономичная модель, сложные Agent-задачи — переключение на GPT/Claude.
Где можно использовать все эти модели через один интерфейс?
Через агрегатор API. Ofox поддерживает все 8 моделей из этого теста и ещё 100+ других — единый OpenAI-совместимый протокол, одна настройка.
Почему оценки отличаются от публичных бенчмарков?
Тестовые наборы публичных бенчмарков (MMLU, HumanEval и т.д.) широко использовались в обучении моделей — проблема загрязнения данных. Мы используем собственные тесты на основе реальных бизнес-задач, отражающие фактический опыт работы. Оценки характеризуют производительность именно в сценариях OpenClaw Agent, а не общие возможности.
Как часто нужно пересматривать выбор модели?
Рекомендуем — каждые 3–6 месяцев. AI-модели развиваются стремительно, лидер 2025 года в 2026-м может уступить новичку. Через агрегатор смена модели — изменение одного параметра, минимальные затраты.
Итоги
По результатам тестирования 8 моделей — три ключевых вывода:
- Потолок возможностей: Claude Opus 4.6 (лучший код) и GPT-5.4 (лучшие рассуждения и вызов инструментов) делят первенство, но и цена самая высокая
- Оптимальный выбор на каждый день: Claude Sonnet 4.6 — наиболее сбалансированная модель; в паре с DeepSeek V3.2 как экономичным резервом — лучшая комбинация для большинства пользователей OpenClaw
- Не ограничивайтесь одной моделью: гибридная стратегия позволяет снизить расходы на 60–70% без потери качества
Практический совет напоследок: через агрегатор Ofox все 8 моделей доступны по одному API Key — без хлопот с регистрацией, управлением ключами и оплатой на разных платформах. Начните с бесплатного баланса, найдите свою оптимальную комбинацию, а затем решайте о долгосрочных инвестициях.
Модели постоянно совершенствуются, и через полгода этот рейтинг наверняка изменится. Но методология выбора останется прежней: сначала — сценарий, затем — возможности, и только потом — стоимость.