苹果第三代基础模型解读:WWDC 2026 之后,开发者真正要看的几件事
WWDC 2026 苹果发布 AFM 3 五模型矩阵:端侧 20B 稀疏 LLM 用 Instruction-Following Pruning、Private Cloud Compute 扩展到 Google Cloud 上的 NVIDIA GPU。哪些是事实、哪些是话术、对开发者意味着什么。
摘要 — 2026 年 6 月 8 日,苹果发布了第三代基础模型,同步重新命名了 “Siri AI”。五个模型。最亮眼的是 200 亿参数稀疏端侧模型(AFM 3 Core Advanced),每个 prompt 只激活 1–4B 参数,背后用的是苹果研究院称为 Instruction-Following Pruning 的技术。另一条更安静、但对开发者更重要的消息:苹果最强的云端模型 AFM 3 Cloud Pro 跑在 Google Cloud 中的 NVIDIA GPU 上,并使用 Google Gemini 前沿模型的输出做精调。苹果坚持这模型是自家的;苹果高管也很小心地区分”使用 Gemini 训练”和”就是 Gemini”。把端侧模型暴露给任意 Swift app 的 Foundation Models 框架,现在支持图像输入。所有这些在欧盟的 iPhone/iPad 和中国大陆首发时都用不了。
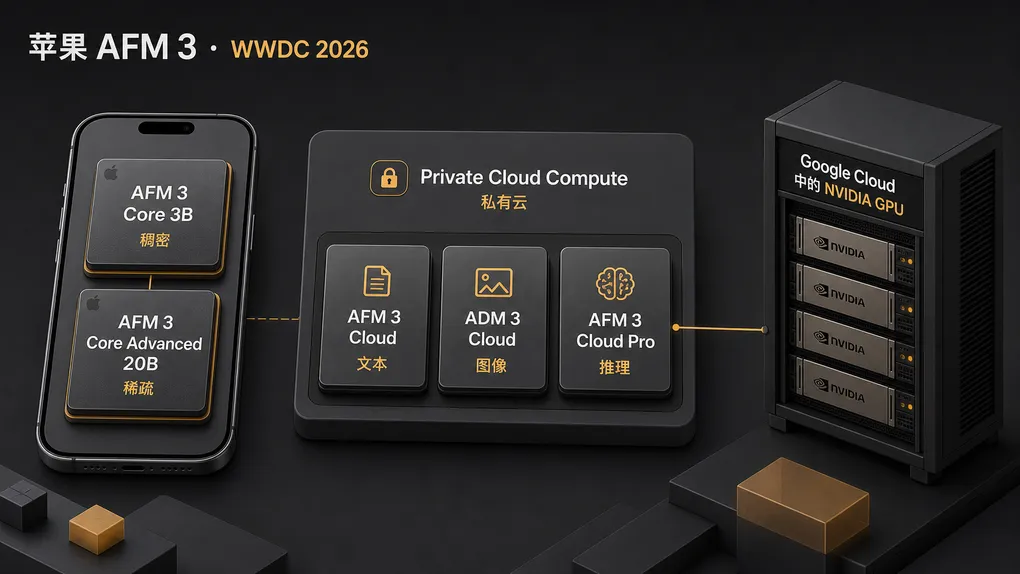
五模型矩阵
苹果的研究博客明确点名五个不同模型。这次命名比 2024 年的 “AFM-on-device / AFM-server” 二元组更有条理,也透露出苹果希望开发者怎么理解这套堆栈:端侧两层、Private Cloud Compute 三层。
| 模型 | 运行位置 | 规模 | 单次激活 | 角色 |
|---|---|---|---|---|
| AFM 3 Core | 端侧 | 3B(稠密) | 3B | 轻量文本、路由、快速 NLU |
| AFM 3 Core Advanced | 端侧 | 20B(稀疏) | 1–4B/prompt | 新 Siri / 听写 / TTS;图像理解 |
| AFM 3 Cloud | Private Cloud Compute | 未公布 | — | 云端主力文本 / 图像理解 |
| ADM 3 Cloud | Private Cloud Compute | 未公布 | — | 图像生成(Image Playground、Reframe、Extend、Cleanup) |
| AFM 3 Cloud Pro | Google Cloud 中的 NVIDIA GPU(Private Cloud Compute 扩展) | 未公布 | — | 复杂推理、Agent 工具调用 |
云端三个模型的参数量苹果一个都没公布。只有端侧两个模型披露了规模。
20B 稀疏模型,以及它为什么重要
技术上最有意思的是 AFM 3 Core Advanced。它是一个 200 亿参数的模型,能装进手机、跑在手机里——靠的是单次激活不超过约 4B 参数。
诀窍是 Instruction-Following Pruning(IFP),苹果研究院 2025 年 1 月在 arXiv 论文 里首次发表。思路:与其把稀疏当作训练时设定好的静态结构决策,不如让一个小预测器读取 prompt,为这次请求动态选择要激活的 FFN 矩阵行和列。论文的核心结果:他们的 3B 激活模型在数学和编程任务上比 3B dense 基线高 5–8 个绝对分,并追平 9B dense 模型的表现。也就是说,同样的 3B 激活算力,买到了 9B 级别的质量。
进到生产模型,故事变成内存层面的:苹果把完整模型放在闪存(NAND)里,把一小撮”始终激活的共享 expert”留在 DRAM,只在预测器选中时才把对应 expert 调进 DRAM。这就是 20B 模型能塞进端侧、又不烧电池的方式。
直白说:苹果给 iPhone 装上了第一个面向消费者大规模量产的动态稀疏 LLM。它不是经典意义上的 MoE(没有学到的 router 在每个 token 上选 K-of-N expert),但是近亲——而且工程落地是首次。
苹果没有做的事:没有把 AFM 3 Core Advanced 拉去和 GPT-5.5、Claude Opus 4.8、Gemini 3.1 Pro、Qwen 3.7 或 Llama 4 比。所有对比都是和苹果自家 2025 年基线比。下面的评测数据,应该被读作代际进步的证据,不是竞品排名。
苹果的人工评测到底说了什么
苹果的评测方法是盲测情况下与上一代 AFM 的两两人工偏好对比。下面是研究博客里逐字摘出来的数字:
| 评测 | 新模型偏好率 | 2025 基线偏好率 |
|---|---|---|
| 文本(AFM 3 Core,端侧) | 45.6% | 23.3% |
| 文本(AFM 3 Cloud) | 64.7% | 8.7% |
| 图像理解(AFM 3 Core) | >61% | — |
| 图像理解(AFM 3 Cloud) | 37.8% | 9.6% |
| 听写总体质量(AFM 3 Core Advanced) | 44.7% | 17.6% |
Cloud Pro 相对 Cloud 在文本上多 +10% 相对偏好,数学上多 +14%,图像理解上多 +14%。
新端侧 TTS 的 Mean Opinion Score:
| 嗓音 | 当前 TTS | AFM 3 Core Advanced |
|---|---|---|
| 通用 | 3.87 | 4.15 |
| 对话式 | 3.82 | 4.24 |
引用这些数字时有两个 caveat 必须记住:
- 没有第三方基准。没有 MMLU、没有 SWE-bench、没有 GPQA。苹果公布的所有数字都是对 2025 基线的偏好对比。
- 两两偏好评测对技术任务来说是粗的。它衡量的是”人类是不是更喜欢这个答案”,对聊天很说明问题,对代码和推理说服力弱。
Gemini 之争:哪些是事实
苹果和 Google 的合作产生了两条平行叙事,外界报道里一直没对齐。下面是两位苹果高管的原话:
“我们使用的 Google Assistant 数量是零。” — Craig Federighi,软件工程高级副总裁(9to5Mac)
“所有这些模型都是专为 Apple Silicon 定制构建,使用专有数据训练,并使用 Gemini 前沿模型的输出进行精调。” — Amar Subramanya,苹果 AI 副总裁(CNBC)
调和后:苹果没有在生产环境跑 Gemini 服务 Apple Intelligence。苹果确实把 Gemini 的输出当作后训练(蒸馏式精调)的一部分。具体到 AFM 3 Cloud Pro,多家报道描述了更深的 Google 参与——Gemini 衍生的训练基础设施、苹果负责预训练和后训练、NVIDIA 提供推理。苹果没有反驳这个说法,但也没在台上主动讲。
诚实的总结:Gemini 是教师信号,不是运行时模型。 这是 2026 年一个真实且在扩张的模式——前沿实验室训教师模型,下游玩家做蒸馏——而苹果是公开采用这种模式的最大分发渠道。
Private Cloud Compute,现在跑在 Google 数据中心的 NVIDIA 上
苹果 Private Cloud Compute(PCC)2024 年上线时拿出了一套挺猛的安全架构:运行被审计代码的 Apple Silicon 服务器,加密保证用户数据连苹果自己也碰不到。2026 年的扩展是个意外:PCC 现在也跑在 Google Cloud 内部托管的 NVIDIA GPU 上,苹果说同样的数据处理保证依然适用。
两个相关细节值得标出:
- 为什么用 Google 的数据中心? 报道显示苹果先试图用自家 PCC 硬件跑新的 Cloud Pro 模型,结果太慢。Google Cloud 上的 NVIDIA 容量是最后跑通的方案。
- 为什么主题演讲里一句没提? 苹果 keynote 提了 NVIDIA,没提 Google。Google 只出现在研究博客和事后的高管采访里。苹果想让你听到的品牌故事是”苹果模型、NVIDIA 硬件、苹果隐私”。完整的供应链比这更纠缠。
对评估苹果隐私承诺的开发者来说,工程实质是加密验证链路,不是 GPU 的物理位置。底层挪到 Google Cloud 上的 NVIDIA 并不打破这一点——但确实意味着信任模型现在涉及更多供应商。
Foundation Models 框架:2026 加了什么
这是发布会里报道最少、但和开发者关系最直接的部分。
Foundation Models 框架在 2025 年首次推出,是一个 Swift API,让任何第三方 app 都能直接调用苹果端侧约 3B 的模型——不需要 API key、不需要网络、按 token 没有任何成本。2026 的更新加了 图像输入:开发者现在可以把图像和文本一起传给端侧模型,让端侧视觉任务成为可能(给照片配文、从收据里提取结构化数据、识别 UI 元素),全程不走云端。
框架擅长的:
- 结构化输出(强类型 Swift 值,不是纯文本)
- 工具调用 / function calling
- 隐私敏感的嵌入式智能(笔记摘要、端侧搜索、智能建议)
- 离线可靠性(不依赖网络)
框架按设计不擅长的:
- 通用知识问答(它不是 chatbot 后端)
- 任何需要最新世界知识的场景
- 需要前沿推理、超长上下文或多步 Agent 工具调用的任务
对一个 2026 年秋天发布的 iOS app,现实的模式是混合:端侧任务用 Foundation Models 框架,因为快、免费、离线;其他都 fallback 到云端模型。 这种 fallback 路径就是多服务商网关(包括 ofox.ai)发挥作用的地方——你希望 OpenAI/Anthropic/Google/Qwen/DeepSeek 都藏在同一个 API 后面,这样可以切换服务商而不用重新发版。
哪些地区首发用不上
地理限制比苹果以往的 AI 发布更严:
- 🇪🇺 欧盟:Siri AI 在 iPhone 和 iPad 上首发不可用。Mac、Apple Watch、Vision Pro 包含在内。苹果给出的理由是 DMA 合规工作仍在推进。
- 🇨🇳 中国大陆:所有 Apple Intelligence,包括 Siri AI,等待监管批准前都不可用。
- 硬件门槛:iPhone 16 系列、iPhone 15 Pro / 15 Pro Max、搭载 A17 Pro 的 iPad mini、M1 或更新的 iPad、M1 或更新的 Mac、Apple Vision Pro。Apple Watch 上 watchOS 27 支持 Series 10、Series 11、Ultra 2、Ultra 3、SE 3——Watch 端 Apple Intelligence 还需要配对 iPhone 15 Pro / Pro Max 或更新机型。
- 上线节奏:Siri AI 2026 年晚些时候以 beta 形式先支持英语,32 个支持的语言地区会逐步加入。语种覆盖英语(美 / 英 / 澳 / 印)、PFIGSCJK(葡 / 法 / 意 / 德 / 西 / 中 / 日 / 韩)、DNNSTV(丹 / 荷 / 挪 / 瑞 / 土 / 越)、AFIHHMPRTU(阿 / 芬 / 印尼 / 希 / 印地 / 马来 / 波 / 俄 / 泰 / 乌克兰)。
欧盟/中国的缺口意味着 Apple Intelligence 在地理上正式成为部分产品——同样的硬件,根据 Apple ID 区域不同会做明显不同的事,开发者文档也得按能力可用性分叉。
这对开发者实际意味着什么
如果你在 2026 年底要发 AI 功能,这三件事值得收下:
- 端侧 LLM 跨过了可用性门槛。 一个 20B 稀疏模型在手机上、支持图像输入、对 app 开发者免费,已经足够处理 app 内 AI 任务的一大块——结构化提取、分类、嵌入式摘要、工具路由。原本为了做这些事掏钱调云端 API 的 app,可以停了。
- 前沿任务依然属于云端。 Cloud Pro 存在是有理由的。长上下文、Agent 循环、前沿推理、多图像跨模态——所有这些通过云端 LLM 仍然更便宜、更强,或者两者都是。构建决策现在变成”什么不能跑在端侧”,而不是”我要多大的模型”。
- 多服务商接入是更安全的默认。 苹果现在出货的端侧模型部分由 Gemini 蒸馏而来,云端跑在 Google Cloud 中的 NVIDIA 上。模型层的供应商绑定,连苹果都不再当可选项。如果你做跨平台产品,应用层只押注单一模型供应商,这个赌注越来越难证明合理。
主线:苹果把端侧 LLM 变成了 iOS 上的基础能力。有意思的工作往上挪——挪到决定何时用它、何时绕过它,以及怎么做到这件事而不把 app 绑死在任何一家供应商身上。
延伸阅读
- AI API 高可用 fallback 指南 2026 — 多服务商网关下的容错策略
- cc-switch:多 CLI 切换 Claude Code / Codex / Gemini 教程 2026 — 同 prompt 多家模型并发对照
- AI 模型排名与选型指南 2026 — 端侧 vs 云端 vs 前沿三层选型
信源核对
- Apple Machine Learning Research — Introducing the Third Generation of Apple’s Foundation Models(模型矩阵、IFP、评测数据,逐字摘)
- Apple Newsroom — Apple unveils next generation of Apple Intelligence, Siri AI, and more(硬件列表、语言列表、地区可用性)
- 9to5Mac — Federighi details Apple’s collaboration with Google for Siri AI(Federighi “Google Assistant 用量为零”原话)
- CNBC — Apple partnering with Google and Nvidia for most advanced AI model(Subramanya 原话、NVIDIA-in-GCP 安排)
- AppleInsider — Apple’s new foundation models don’t contain a drop of Gemini(关于 Gemini 关系的独立解读)
- MacRumors — Siri AI not available in EU/China initially(地区限制)
- arXiv 2501.02086 — Instruction-Following Pruning for Large Language Models(IFP 技术,苹果原论文)
- MarkTechPost — Apple Researchers Introduce IFPruning(第三方 IFP 解读)