Claude Opus 4.8 发布:基准、Fast Mode 与真正的变化
Claude Opus 4.8 于 2026 年 5 月 28 日发布,价格与 4.7 持平,在独立的 GDPval-AA 真实工作榜单上以 1890 Elo 登顶。本文拆解:SWE-bench Pro 69.2%、新增 Fast Mode、dynamic workflows,以及如何通过 ofox.ai 接入。

TL;DR —— Anthropic 于 2026 年 5 月 28 日发布 Claude Opus 4.8,价格与 4.7 持平($5/$25)。它在 Artificial Analysis 的 GDPval-AA 真实工作榜单上以 1890 Elo 登顶(领先 GPT-5.5 121 分,领先 4.7 137 分),SWE-bench Pro 拿下 69.2%,而且完成同样任务的输出 token 比 4.7 少约 35%——更强,跑起来还更省。本次新增 Fast Mode(2.5 倍输出速度)、会话中途 system 消息,以及 Claude Code 的 dynamic workflows。Anthropic 还称它是迄今最诚实的模型。
Anthropic 这次发了什么
Claude Opus 4.8 于 2026 年 5 月 28 日上线,距 GPT-5.5(4 月 23 日发布)刷新榜单顶端约五周。模型 ID 为 claude-opus-4-8,在 Claude API 上默认携带完整的 1M token 上下文窗口(Microsoft Foundry 为 200K),最大输出 128K token,并且——对预算规划很重要——挂牌价与 Opus 4.7 完全相同:输入 $5、输出 $25 / 百万 token。
这次的主线既不是降价,也不是加上下文,而是:Opus 4.8 是第一个在真实 agent 工作上明显拉开与 GPT-5.5 一代差距的模型,而且用更少的 token 做到。
GDPval-AA 的结果
最值得看的数字不来自 Anthropic,而来自独立评测机构 Artificial Analysis。他们的 GDPval-AA 榜单用真实经济工作任务(取自 OpenAI 的 GDPval 数据集,覆盖 9 大行业 44 种职业)给模型打分:在 agent 循环中给每个模型 shell 访问和网页浏览能力(通过他们开源的 Stirrup 框架),再用盲对比的胜负推导 Elo 评分。
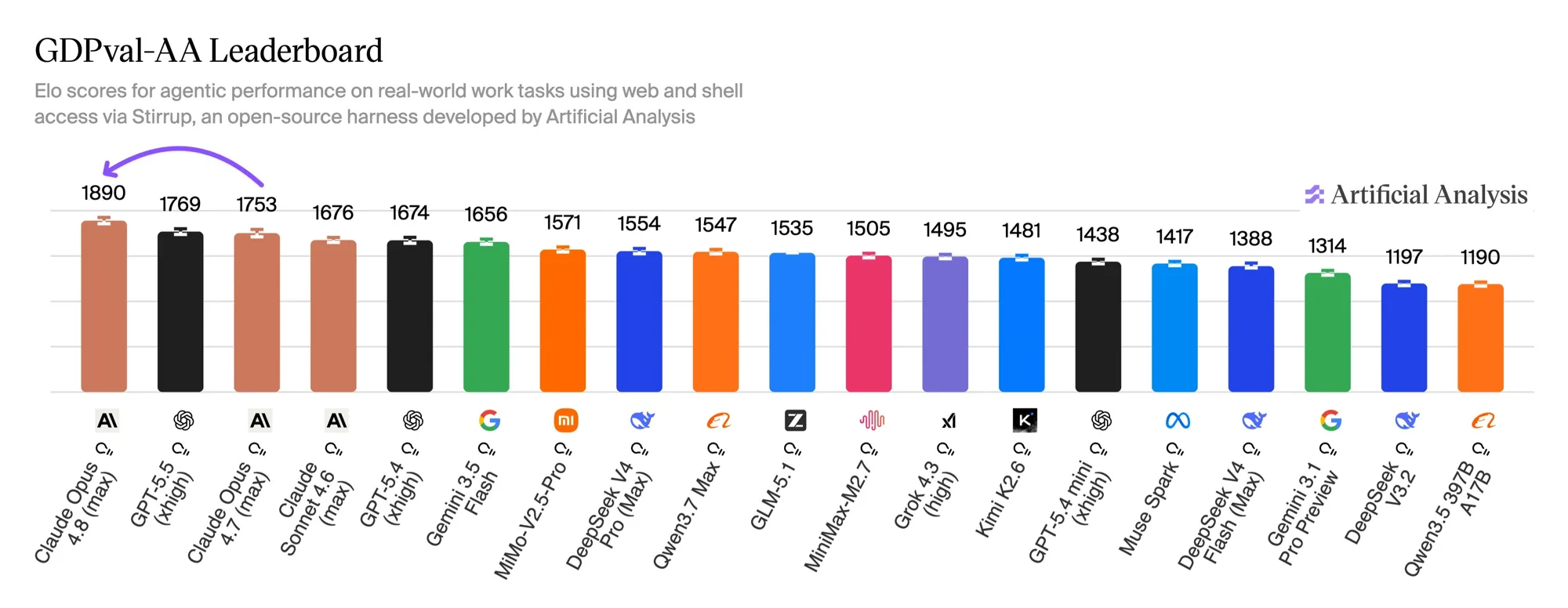
Opus 4.8(max effort)以 1890 Elo 首发登顶,比第二名的 GPT-5.5 高出 121 分,比自家前代 高出 137 分。这个差距换算成对 GPT-5.5(xhigh)的隐含胜率约为 67%。榜单前四名里有三个是 Claude 模型。
比单纯的基准百分比更可信的一点:Artificial Analysis 指出,Opus 4.8 拿到这个分数时,每个任务的轮次比 4.7 少 15%、输出 token 少 35%。代价是它仍比 GPT-5.5 多约 30% 的轮次才能完成同样任务——Opus 在动手前思考得更多。对于输出 token 占账单大头的 agent 流水线来说,更少的 token + 更高的胜率,才是真正能压低月度账单的组合。
与同代旗舰的基准对比
Anthropic 自家数据在编码和电脑操作上与独立结果吻合,只有一处需要如实指出的例外。
| 基准 | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| OSWorld-Verified(电脑操作) | 83.4% | 82.8% | 78.7% | 76.2% |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| Humanity’s Last Exam(带工具) | 57.9% | — | — | — |
| Finance Agent v2 | 53.9% | — | — | — |
| GDPval-AA(Elo) | 1890 | 1753 | 1769 | — |
SWE-bench Pro 用的是真实开源仓库而非合成任务,69.2% 比上一代的同类标杆 Opus 4.7 高出近 5 个点。OSWorld-Verified(直接驱动真实桌面)则是 Opus 一直低调领先的项目。
值得点出的例外:Terminal-Bench 2.1 仍是 GPT-5.5 赢(78.2% vs 74.6%)。如果你的负载大量是原始终端命令序列,这是个真实数据点,不是误差。但对大多数 agent 类编码——多文件重构、长时自主运行、整库级任务——Opus 4.8 现在是最强选项。
引擎盖下的新东西
除了分数,有四个 API 层面的变化对在 Opus 4.8 上做开发的人很重要。
Fast Mode。 这是个研究预览,用同一个 Opus 4.8 模型提供最高 2.5 倍的每秒输出 token 速度,按溢价计费。API 里设 speed: "fast",Claude Code 里用 /fast。容易误解的一点:Fast Mode 不是更小更便宜的模型,而是完整的 Opus 4.8 跑得更快——当延迟比单 token 成本更重要时用它。
会话中途的 system 消息。 现在可以在 messages 数组里、用户回合之后插入 role: "system" 消息。在长 agent 循环里,这让你能追加更新后的指令而不必重述整个系统提示词——从而保住前面回合的 prompt cache 命中、降低输入成本。配合降到 1,024 token 的缓存最小长度(4.7 更高),之前太短无法缓存的系统提示词现在也能缓存了。
Adaptive thinking,effort 默认 high。 和 4.7 一样,Opus 4.8 不接受显式 thinking budget——thinking: {"type": "enabled", "budget_tokens": N} 会返回 400。改用 thinking: {"type": "adaptive"} 加 effort 参数。开启 adaptive thinking 后,模型按回合自行决定是否需要推理,在简单查询上少浪费思考 token。effort 默认值在所有平台(含 Claude Code)现在都是 high。
from openai import OpenAI
client = OpenAI(base_url="https://api.ofox.ai/v1", api_key="your-ofox-key")
response = client.chat.completions.create(
model="anthropic/claude-opus-4.8",
messages=[{"role": "user", "content": "重构这个模块……"}],
)更好的工具触发与压缩处理。 Anthropic 列出的改进方向是长时 agent 编码(更少压缩、压缩后恢复更好)、推理 effort 校准,以及工具触发——具体是更少出现「该调工具却跳过」的情况,这正是部分用户对 4.7 的抱怨。
Opus 4.8 提示词:到底变了什么
Anthropic 的提示词指南点出了几个 4.8 专属的行为变化——提示词原样迁移过来可能踩坑。上线前有四点值得知道。
effort 现在是主旋钮,而且比以往任何一代 Opus 都更重要。 编码和 agent 类用例从 xhigh 起步,任何对推理质量敏感的任务至少保持 high。max 能带来提升,但容易过度思考、收益递减。反过来,4.8 严格遵守 low 和 medium——它把工作范围精确收敛到你要求的范围,对延迟很友好,但在中等复杂任务上有思考不足的风险。如果推理显得浅,提高 effort,而不是绕着提示词打转。在 high/xhigh 下,设一个大的输出预算(从 64K token 起),让模型有空间思考和行动。
它严格按字面执行指令。 Opus 4.8 不会把一条指令从一个对象悄悄推广到另一个,也不会脑补你没提的需求。这对结构化抽取和流水线是好事——但如果你想让某条指令广泛适用,要显式说清范围:「把这个格式应用到每一个章节,不只是第一个」。
它偏好推理而非调用工具。 4.8 默认更倾向思考而非调工具,多数情况下这更好——但如果你的 agent 搜索或读文件不够,把 effort 提到 high/xhigh 会显著增加工具使用。你也可以直接告诉它何时、为何使用某个工具。
代码审查的召回率陷阱。 这点会让团队意外。Opus 4.8 找 bug 确实更强(Anthropic 的内部评测里精确率和召回率都更高),但如果你的审查框架写着「只报高严重度问题」或「保守一点」,4.8 会比旧模型更忠实地照做——它找到了 bug,然后把低于你设定门槛的丢掉。结果看起来像召回率下降,其实找 bug 的能力提升了。解法是把「发现」和「过滤」拆开:
报告你发现的每一个问题,包括低严重度或不确定的。
这一阶段不要按重要性过滤——后续会有单独的步骤排序。
每条发现都附上置信度和预估严重度。「最诚实模型」这个说法
Anthropic 把 Opus 4.8 定位为迄今最诚实的模型——更少一本正经的编造、更少迎合、更清晰的拒答。就最后一点,拒答响应上的 stop_details 对象(4.7 起就有)现在正式公开文档化,你的应用可以知道请求为什么被拒、据此引导用户,而不是把所有拒答一视同仁。对无人值守运行的 agent 来说,一个更少编造、更清楚地表达自身不确定性的模型,是实打实的可靠性提升,而不只是安全层面的说辞。
同期发布:Claude Code 的 Dynamic Workflows
Opus 4.8 与 dynamic workflows 同日发布。这是一个研究预览,让 Claude 在单个会话里编排数十到数百个并行子 agent。Claude 自己写编排脚本、把工作扇出、在交付前验证结果(包括专门负责反驳其他 agent 结论的 agent),并能在中断后从断点续跑而不是重头来。
旗舰演示:Jarred Sumner 用 dynamic workflows 把 Bun 从 Zig 移植到 Rust——约 75 万行代码、测试套件 99.8% 通过率、11 天完成。目标用例是整库级 bug 排查、安全审计,以及跨数千文件的大型迁移。
但有两点要提醒。其一,它受套餐限制:dynamic workflows 跑在 Claude Code 的 Max、Team、Enterprise 套餐上(Enterprise 需管理员启用),不支持直接走 API。其二,Anthropic 明确警告 token 消耗比普通会话高得多——建议从范围明确的小任务开始。它是给最难的活儿的全新能力,不是默认开启的便利功能。
通过 ofox.ai 接入 Opus 4.8
模型 ID 是 anthropic/claude-opus-4.8。通过 ofox.ai,它和其他所有模型一样在同一个 OpenAI 兼容端点上——无需单独的 Anthropic 账号、无需单独计费。
要用 adaptive thinking 和 effort 控制,走 Anthropic 原生协议:
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="your-ofox-key",
)
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=4096,
thinking={"type": "adaptive"},
messages=[{"role": "user", "content": "审计这个服务的竞态条件……"}],
)走聚合网关还能让「要不要迁移」这个问题用数据说话:你可以用一把 key、一个端点,把同样的提示词分别跑过 Opus 4.8、4.7 和 GPT-5.5,在你自己的负载上对比质量和 token 数,再决定。
结论
Opus 4.8 是少见的、价格上没有任何附加条件的升级:同样的 $5/$25、编码与电脑操作上几乎全面领先的分数、独立真实工作榜单登顶,而且每个任务输出 token 更少。需要如实说明的注意点很有限——GPT-5.5 仍在原始终端基准上领先、dynamic workflows 受套餐限制且耗 token、effort 现在默认 high 所以要留意延迟预算。
新项目直接上 4.8。在 4.7 上跑生产的,这是 Anthropic 近期最干净的一次迁移——同价、更省 token,账算下来通常对你有利。用有代表性的样本测一遍、留意工具调用相关的提示词,然后放心切过去。
相关阅读:Claude Opus 4.7 完整指南 —— 前代及其特点。GPT-5.4 vs Claude Opus vs Gemini 旗舰对比 —— 旗舰横评。多模型路由与成本优化 —— 如何按任务分流省钱。AI 模型排名与选型指南 —— Opus 4.8 在整体格局里的位置。


