DeepSeek V4 发布:1.6T 开源 MoE,1M 上下文,Apache 2.0——价格只有 GPT-5.5 的零头
DeepSeek 挑了 GPT-5.5 发布同一天出 V4 预览版。Pro 1.6T、Flash 284B、1M 上下文、Apache 2.0 权重,API 同步上线。Codeforces 3206,超过 GPT-5.4。Chinese-SimpleQA 84.4,超过除 Gemini 外所有闭源模型。价格便宜到离谱,ofox 正在第一时间接入。
先说结论 — DeepSeek 挑了 OpenAI 发 GPT-5.5 的同一天发 V4 预览版。1.6T Pro + 284B Flash,都给 1M 上下文,权重直接 Apache 2.0 开源,API 当天上线。V4-Pro 输出单价 $3.48,只有 GPT-5.5($30)的 1/8.6,Opus 4.7($75)的 1/21。Codeforces 拿到 3206,超过 GPT-5.4。ofox 正在第一时间接入。
新用户立享 5 美元体验金 — 在 ofox.ai 一键接入 DeepSeek V4,OpenAI 兼容端点。
这次 DeepSeek 到底发了什么
- 两个变体:
deepseek-v4-pro(1.6T 总参 / 49B 激活)和deepseek-v4-flash(284B 总参 / 13B 激活),都是 MoE。 - 1M 上下文,两个版本统一,max output 384K。
- 双模式:Thinking / Non-Thinking,三档推理强度(
high、max,以及非思考)。 - Apache 2.0 开源——V3 是 MIT,V4 升级到 Apache 2.0,商业部署的专利保护更清晰。
- API 同步上线。base_url 不变,改 model name 就行。兼容 OpenAI ChatCompletions 和 Anthropic 两种协议。
- 旧模型名淘汰:
deepseek-chat和deepseek-reasoner在 2026 年 7 月 24 日下线,目前都路由到deepseek-v4-flash。
发布时间不是偶然。OpenAI 同一天发 GPT-5.5——DeepSeek 需要一个”开源 1M 上下文 MoE 极致便宜”的叙事不会被”闭源大涨价”盖过去的时间窗口。同天发就是主动分掉媒体注意力。
架构:真正值得注意的部分
V4 引入了一套混合注意力机制:Compressed Sparse Attention (CSA) + Heavily Compressed Attention (HCA),搭配 Manifold-Constrained Hyper-Connections (mHC) 做残差信号传播和 Muon 优化器做训练稳定性。在 1M 上下文下的净效果:
- 单 token 推理 FLOPs 只有 V3.2 的 27%
- KV cache 只有 V3.2 的 10%
这才是真正的效率故事。长上下文推理最大的成本在 KV cache,V4 直接砍到十分之一——这是开源模型能把 1M 上下文做成普惠服务的关键。预训练用了 32T+ tokens,FP4 + FP8 混合精度——MoE expert 用 FP4,其余大部分用 FP8。
Flash 不是 Pro 的裁剪版,是单独训练的 284B / 13B MoE。Flash-Max(最大推理强度)在大多数 benchmark 上接近 Pro 水平,但服务成本低得多。
Arena Code 榜单
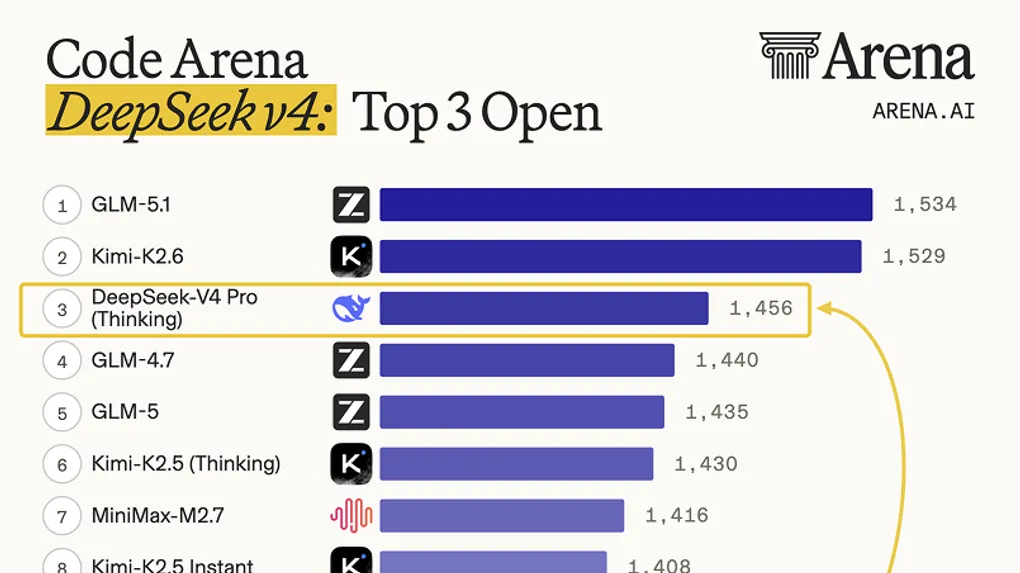
Arena AI 的代码榜直接把 V4-Pro Thinking 放到了开源模型第 3:
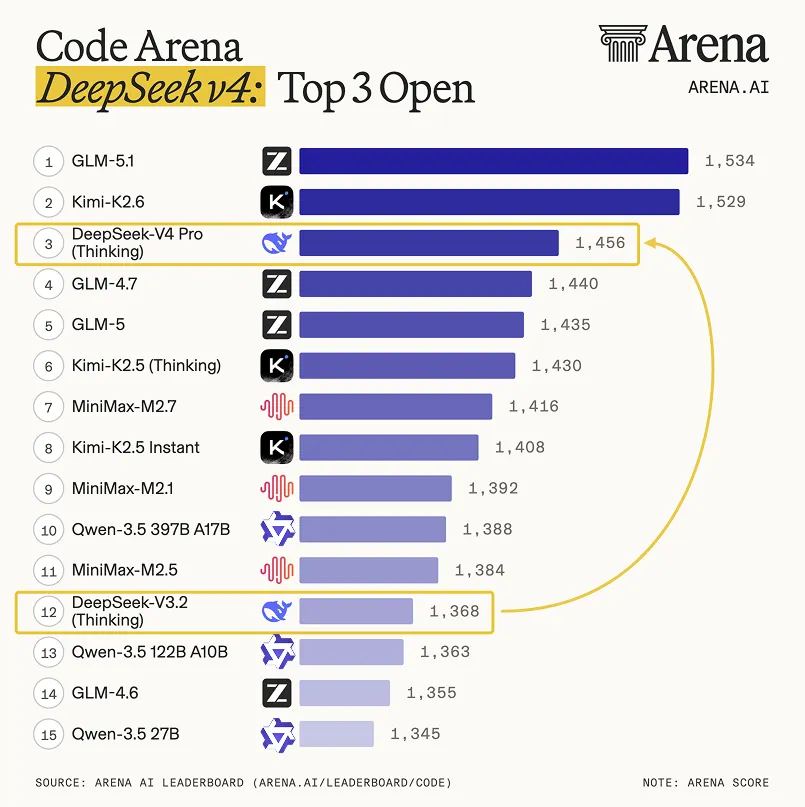
来源:Arena AI Code 榜单,2026 年 4 月 24 日
| 排名 | 模型 | Elo |
|---|---|---|
| 1 | GLM-5.1 | 1,534 |
| 2 | Kimi-K2.6 | 1,529 |
| 3 | DeepSeek-V4 Pro(Thinking) | 1,456 |
| 4 | GLM-4.7 | 1,440 |
| 12 | DeepSeek-V3.2(Thinking) | 1,368 |
V3.2 → V4-Pro 之间拉开了 88 分 Elo——差不多等于榜单上第 3 到第 13 的差距。这是真正的代际跳跃,不是小修小补。
但要诚实:V4-Pro 仍然落后 K2.6 73 分 Elo。代码榜上它排第 3,不是第 1。
完整 benchmark 对比
DeepSeek 放出了完整的横评,对手是 K2.6、GLM-5.1、Opus 4.6、GPT-5.4、Gemini 3.1 Pro:
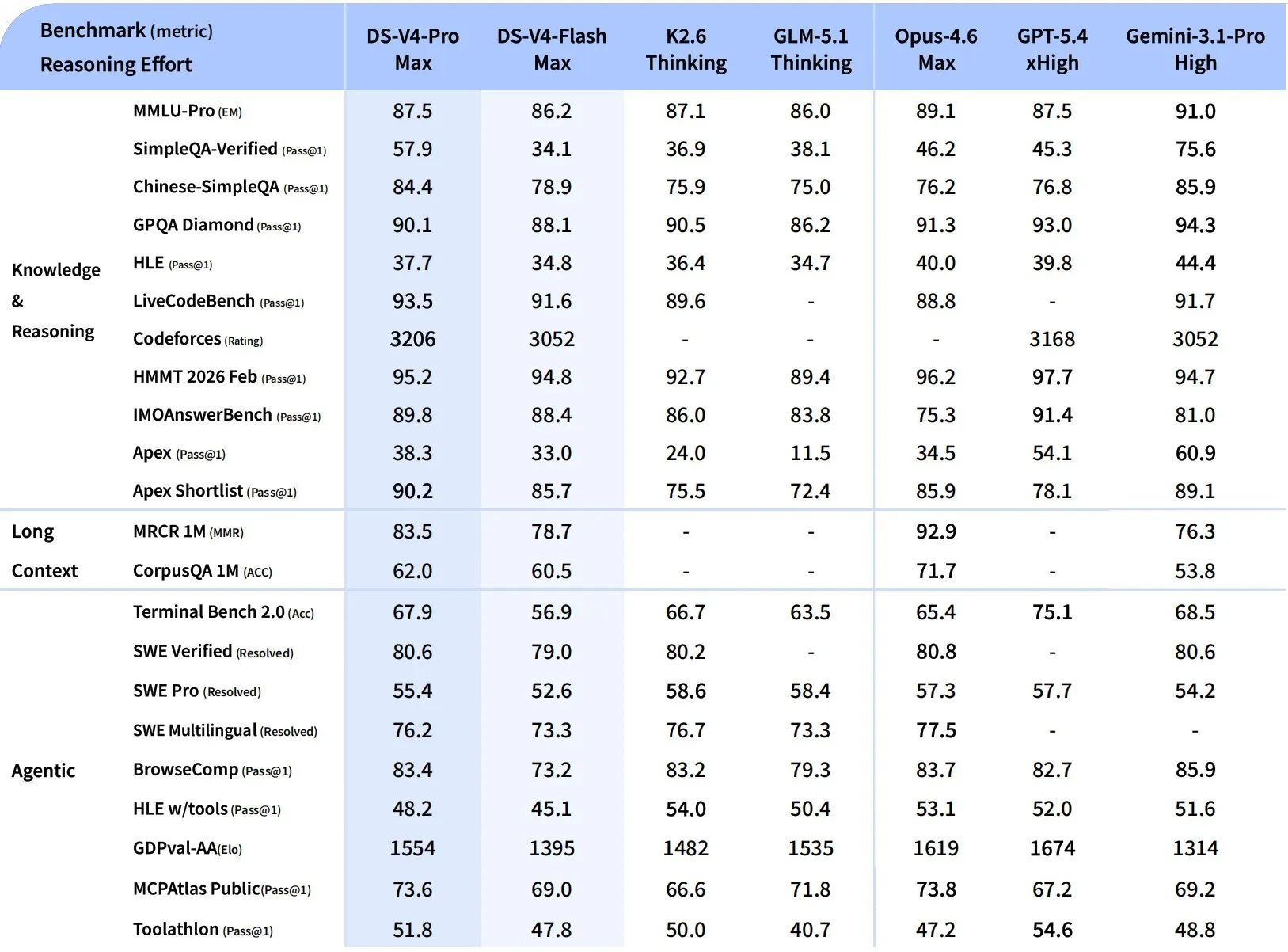
来源:DeepSeek V4 技术报告,2026 年 4 月 24 日
V4-Pro 领先的场景:
| Benchmark | V4-Pro Max | K2.6 Thinking | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Chinese-SimpleQA | 84.4 | 75.9 | 76.2 | 76.8 | 85.9 |
| LiveCodeBench | 93.5 | 89.6 | 88.8 | — | 91.7 |
| Codeforces(Elo) | 3206 | — | — | 3168 | 3052 |
| IMOAnswerBench | 89.8 | 86.0 | 75.3 | 91.4 | 81.0 |
| Apex Shortlist | 90.2 | 75.5 | 85.9 | 78.1 | 89.1 |
Codeforces 3206 是最硬的一个数字——比 GPT-5.4(xHigh)的 3168 还高。这是竞赛编程领域,之前一直被闭源旗舰把住。
中文 SimpleQA 84.4 也值得单独说:除 Gemini 3.1 Pro(85.9)之外,所有闭源和开源模型都被 V4 拉开明显差距。中文优先的产品第一次拿到了真正旗舰级的开源选项。
输给 K2.6 的场景:
| Benchmark | V4-Pro | K2.6 Thinking |
|---|---|---|
| SWE-Bench Pro(Resolved) | 55.4 | 58.6 |
| SWE-Bench Multilingual | 76.2 | 76.7 |
| HLE w/tools | 48.2 | 54.0 |
| GPQA Diamond | 90.1 | 90.5 |
SWE-Bench Pro 是最接近”读完真实开源项目源码 + 修掉一个 GitHub issue”的 benchmark。K2.6 赢 3 分——不大,但和 Arena Code 榜单的 73 Elo 差距方向一致。
输给闭源旗舰的场景:
- MRCR 1M(长上下文召回):83.5 vs Opus 4.6 的 92.9。Opus 在长上下文精确检索上仍然是王者。
- CorpusQA 1M:62.0 vs Opus 71.7。同上。
- GDPval-AA(Elo):1554 vs GPT-5.4 的 1674 和 Opus 的 1619。经济价值交付上闭源还是领先。
- HLE(不带工具):37.7 vs Gemini 3.1 Pro 的 44.4。
Flash-Max 的表现值得单说:
V4-Flash-Max 在 MMLU-Pro 拿 86.2(Pro 87.5)、LiveCodeBench 91.6(Pro 93.5)、SWE-Pro 52.6(Pro 55.4)。大部分 benchmark 上和 Pro 只差 1~3 分——但成本差一个数量级。
定价:这才是真正改变游戏规则的地方
| 模型 | 输入(未命中) | 输入(命中缓存) | 输出 |
|---|---|---|---|
deepseek-v4-flash | $0.14 / M | $0.028 / M | $0.28 / M |
deepseek-v4-pro | $1.74 / M | $0.145 / M | $3.48 / M |
横向对比(每百万 token 输出价):
| 模型 | 输入 | 输出 |
|---|---|---|
| DeepSeek V4-Pro | $1.74 | $3.48 |
| Kimi K2.6(非思考) | $1.40 | $5.60 |
| GPT-5.5 | $5.00 | $30.00 |
| Claude Opus 4.7 | $15.00 | $75.00 |
V4-Pro 输出比 GPT-5.5 便宜 8.6 倍,比 Opus 4.7 便宜 21 倍。Flash 输出 $0.28——基本等于免费。
这是本次发布最大的故事。1M 上下文 + Codeforces-3200 级推理 + 开源权重,现在的预算只要过去跑中端对话 API 的钱。
社区反馈
首日开源圈和研究圈的集中关注点:
- “Apache 2.0 是真正的升级”。V3 是 MIT,V4 升到 Apache 2.0——商业部署的专利保护更清晰。对企业用户这是比数字更重要的变化。
- “中文 SimpleQA 84.4 是一记警钟”。除 Gemini 3.1 Pro,所有其他模型被拉开明显差距。中文优先的应用现在第一次拿到了真正旗舰级的开源选项。
- “SWE-Pro 的差距比榜单显示的小”。K2.6 在 SWE-Pro 领先 3 分,但 V4 在 LiveCodeBench 和 Codeforces 反超。短代码生成 vs 长周期代码库修复——两个不同的能力分叉。
- “1M 上下文能用,但不是 Opus 级”。MRCR 和 CorpusQA 显示 Opus 4.6 在长上下文精确检索上仍领先。V4 的胜利在效率(10% KV cache),不在绝对召回质量。
通过 ofox 使用(即将)
ofox 当前提供的是 deepseek/deepseek-v3.2。V4-Pro 和 V4-Flash 正在第一时间接入,很快会出现在模型列表里。
如果你现在就要用 V4,可以直接调 DeepSeek 官方 API:
from openai import OpenAI
client = OpenAI(
api_key="your-deepseek-key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "把这个 Rust 服务翻译成 Go,保留并发语义"}],
extra_body={"thinking": {"type": "enabled"}}
)
print(response.choices[0].message.content)ofox 接入后切换只需改一行——同一把 ofox key、base_url 仍然是 https://api.ofox.ai/v1,model 改成 deepseek/deepseek-v4-pro 或 deepseek/deepseek-v4-flash 即可。还没有 ofox key?去 ofox.ai 注册——一把 key 之后就能同时覆盖 V4、GPT-5.5、Claude Opus 4.7、Kimi K2.6 等所有主流模型。
要不要换
换 V4-Pro 的理由:跑 Kimi K2.6 做中文任务、竞赛型代码生成、或 Codeforces 级别推理——中文 SimpleQA 和 Codeforces 的领先就是给这些场景准备的。
换 V4-Flash 的理由:目前在 $12/M 输出价位跑任何东西。Flash-Max 在大部分知识类 benchmark 上和 Pro 只差 13 分,但输出便宜 12 倍。
留在 K2.6 的理由:主力工作流是 SWE-Bench 类的代码库修复、高并发 agent 工具调用、或任何 Arena Code 上那 73 分 Elo 差距能直接映射到你任务的场景。
留在闭源旗舰(GPT-5.5 / Opus 4.7)的理由:长上下文精确检索(Opus MRCR 仍领先)、GDPval 级知识工作(GPT-5.4 仍领先)、或 agentic 终端自动化(GPT-5.5 Terminal-Bench 82.7% 自成一档)。