GPT-5.5 发布:自 GPT-4.5 之后首次完整重训,100 万 token 上下文,涨价一倍
OpenAI 4 月 23 日发布 GPT-5.5——自 GPT-4.5 以来第一次从零重训的基座模型。API 支持 1M 上下文,Terminal-Bench 2.0 拿到 82.7%,价格直接翻倍到 $5/$30。拆一下这次到底变了什么、哪些场景值得升级。

先说结论 — 这次 GPT-5.5 的版本号是 0.1 的跳跃,但底层是自 GPT-4.5 之后第一次重训的基座模型,所以实际能力的变化比版本号暗示的要大。Terminal-Bench 2.0 拿到 82.7%,Artificial Analysis 的 Intelligence Index 榜首,价格翻倍到 $5/$30。ofox 已经上线,把 model ID 换成 openai/gpt-5.5 就能用。
这次 OpenAI 到底动了什么
官方宣告里反复强调的一点:这是自 GPT-4.5 以来第一次完整重训的基座模型。中间的 5.1、5.2、5.3、5.4 都是基于同一个底模做后训练迭代出来的——这次不是。架构、预训练语料、训练目标全换了。
训练目标的变化比架构更值得注意。GPT-5.5 被明确定位为一个 agent 模型——OpenAI 的原话是”模型会执行一连串动作、调用工具、自检、持续推进直到任务完成”,过程中不需要人在每个环节重新 prompt。
简单说:前几代是”对话大模型+工具能力”,GPT-5.5 是”agent 基座+对话能力”,训练目标的优先级颠倒了。
两个变体,价格差 6 倍
| 变体 | API model ID | 上下文 | 输入 / 输出(每百万 token) |
|---|---|---|---|
| GPT-5.5 Thinking | openai/gpt-5.5 | 1M(Codex 内 400K) | $5 / $30 |
| GPT-5.5 Pro | openai/gpt-5.5-pro | 1M | $30 / $180 |
Thinking 是默认版,替代的是 ChatGPT 里的 GPT-5.4。Pro 是高精度变体,贵 6 倍,换来几个百分点的可靠性提升——是否值得取决于你的任务。
Batch / Flex 价格是标准的一半,和 5.x 系列其他型号一致。
Benchmark:哪里领先,哪里并没有
OpenAI 这次放出了完整的对比图,数据本身可以直接看:
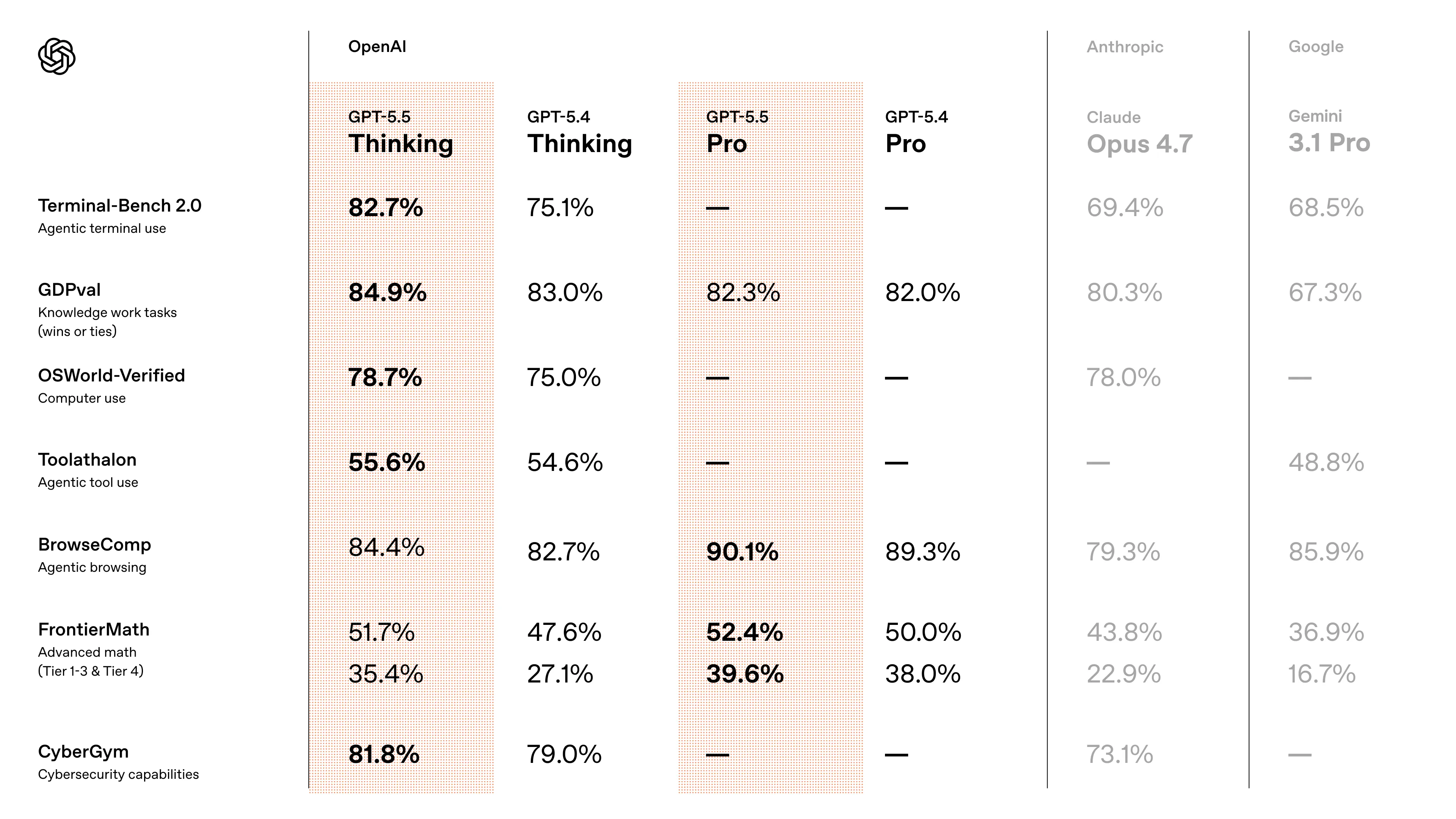
来源:OpenAI 官方 benchmark,2026 年 4 月 23 日
最显眼的几个数字:
| Benchmark | GPT-5.5 Thinking | GPT-5.4 Thinking | Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0(终端 agent) | 82.7% | 75.1% | 69.4% | 68.5% |
| GDPval(知识工作) | 84.9% | 83.0% | 80.3% | 67.3% |
| OSWorld-Verified(Computer Use) | 78.7% | 75.0% | 78.0% | — |
| BrowseComp(Pro 变体) | 90.1% | 89.3% | 79.3% | 85.9% |
| FrontierMath Tier 4(Pro 变体) | 39.6% | 38.0% | 22.9% | 16.7% |
| CyberGym(漏洞复现) | 81.8% | 79.0% | 73.1% | — |
Terminal-Bench 2.0 的 13 分领先是最显眼的——这个 benchmark 直接衡量”模型能否在沙盒终端里独立完成一连串命令行任务”,正好是 agent 训练目标的核心场景。
GDPval 是 OpenAI 自己提的经济价值评测,覆盖 44 种知识工作职业的典型任务输出,84.9% 说明 GPT-5.5 在”交付可用成果”这个层面,比上一代又前进了一步。
Artificial Analysis 的 Intelligence Index 上,GPT-5.5(xhigh)拿了 60,领先 Claude Opus 4.7 和 Gemini 3.1 Pro Preview(两者并列 57)3 分,结束了此前三家平分榜首的局面。
但有些指标 GPT-5.5 并没赢
第三方聚合了一份更诚实的横评:
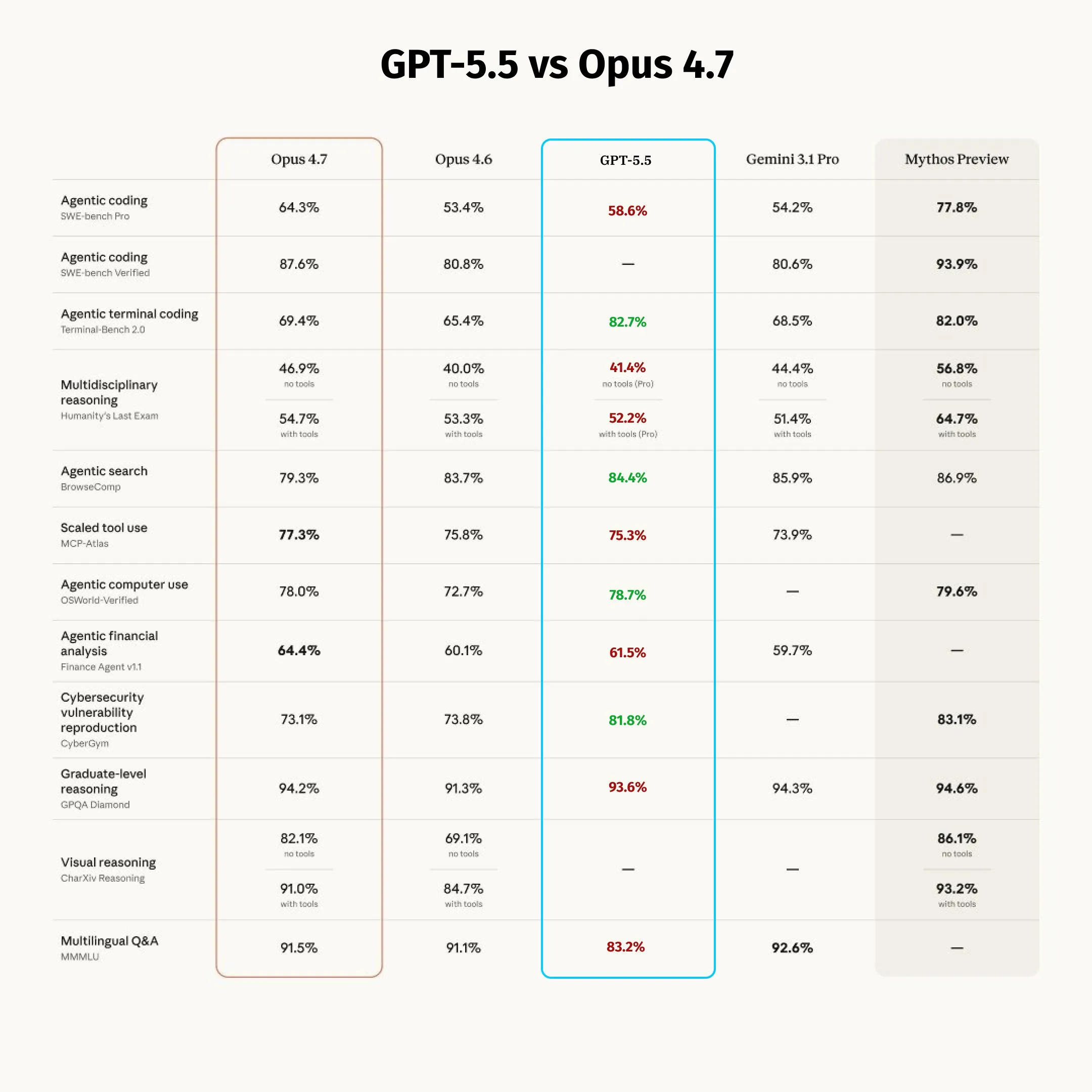
来源:社区 benchmark 聚合,2026 年 4 月 23 日
诚实地说:
- SWE-Bench Pro:Opus 4.7 拿 64.3%,GPT-5.5 只有 58.6%——这个 benchmark 最接近”读完一个真实开源项目的代码,修掉一个 GitHub issue”的场景。Opus 赢得明显。
- SWE-Bench Verified:Opus 4.7 87.6%,GPT-5.5 这次没跑(OpenAI 的对比里是一格横线)。
- MCP-Atlas(大规模工具调用):Opus 4.7 77.3% vs GPT-5.5 75.3%。
- 多语言 Q&A(MMMLU):83.2%——比 Opus 4.7(91.5%)和 Gemini 3.1 Pro(92.6%)都落后一大截,对中文场景尤其值得注意。
- 金融 agent(Finance Agent v1.1):Opus 4.7 64.4% vs GPT-5.5 61.5%。
规律很清楚。GPT-5.5 赢的是规划 + 执行类任务——终端、工具调用、Computer Use、长周期编码。Opus 4.7 赢的是读懂代码库并修复类任务——SWE-Bench、MCP-Atlas、多语言理解。两者不在同一个维度上竞争,按任务选,不要按榜单选。
幻觉率:一个不该被遮住的数字
在换掉 GPT-5.4 之前,有一个数字值得单独拎出来看:Artificial Analysis 的 AA-Omniscience benchmark 上,GPT-5.5(xhigh)拿到了有记录以来最高的准确率 57%——但同时也拿到了最高的幻觉率 86%。作为对比,Opus 4.7(max)幻觉率 36%,Gemini 3.1 Pro Preview 50%。
这不是矛盾。AA-Omniscience 衡量的是”模型说出自信的错误答案”的频率。GPT-5.5 知道的时候答得更准,但不知道的时候更愿意编——而不是停下来说”我不确定”。对会自己评估结果的 agent 工作流,这是个实打实的风险:一个自信的错误动作比一次”我要再确认一下”代价大得多。
合规、引用生成、事实问答这类对幻觉零容忍的场景,换之前一定要跑自己的数据集验证。
价格:单 token 价格翻倍
GPT-5.4 是 $2.50 / $15,GPT-5.5 是 $5 / $30。单 token 直接 2×,是 GPT-5.x 系列里单次发布最大的一次涨幅。
OpenAI 的理由是 token 效率:GPT-5.5 在 Codex 任务上用的 token 数明显少于 5.4。Artificial Analysis 的实测显示,跑完整套 Intelligence Index,token 总量减少约 40%,所以实际每次 Index 评测的费用只涨了约 20%。
这样算下来 GPT-5.5 仍然比 Opus 4.7 便宜:按 AA 的测算,GPT-5.5(medium)能用 Opus 4.7(max)四分之一的钱,拿到相同的 Intelligence Index 分数(约 $1,200 vs $4,800)。Gemini 3.1 Pro Preview 在同样分数下约 $900,所以 GPT-5.5 不是成本冠军,但也没掉队。
但是——短 prompt、高并发的场景下这 2× 是真金白银的涨价。如果你的业务是每天几百万次短对话,不要无脑升级,先算一笔账。
1M 上下文,Codex 里是 400K
API 的 Responses 和 Chat Completions 接口都给 1M。Codex 里只给 400K。为什么差这么多?
Codex 在内部跑着大量并行的 agent 会话,400K 是吞吐量和成本的权衡,不是能力的上限。如果你要一次性塞进一个中型代码库的全部源码 + 一年的 commit history + 文档,用 API,别用 Codex。
另外 1M 是真的很贵。按 $5/M 输入算,塞满整个窗口一次就是 $5——还没开始 output。长上下文是给真正需要它的任务用的工具,不是默认开关。
社区怎么看
发布一天内的开发者反馈,几个反复出现的判断:
- “这次跳跃比 5.4 → 5.5 听起来大”。因为是底模重训,实际能力差距比版本号暗示的大。HN 上不止一个评论指出这才是真正的故事。
- “Terminal-Bench 不等于 SWE-Bench”。VentureBeat 的报道指出:Terminal-Bench 2.0 的领先是真的,但相对 Anthropic 未发布的 Mythos Preview(82.0%)只有窄幅优势,不要把单一 benchmark 的领先当做全方位超越。
- “涨价会劝退一批 Plus 用户”。发布时 Plus 用户被限制为每周 200 条 GPT-5.5 消息,Reddit 上多条讨论把这看作 ChatGPT 端实际体验的降级。
社区的综合观感:能力提升是真实的,agent 场景尤其明显,但不是无脑升级。短 prompt、紧预算的场景下,GPT-5.4 还会继续活很久。
通过 ofox 使用
发布当天 ofox 已经上线,如果你已经在用 ofox,一行改动:
from openai import OpenAI
client = OpenAI(
api_key="sk-of-your-api-key",
base_url="https://api.ofox.ai/v1"
)
response = client.chat.completions.create(
model="openai/gpt-5.5",
messages=[{"role": "user", "content": "把这个服务重构成用 structured tool calls"}]
)
print(response.choices[0].message.content)Pro 变体同一个端点:
response = client.chat.completions.create(
model="openai/gpt-5.5-pro",
messages=[{"role": "user", "content": "追查所有消费者里这个 race condition 的路径"}]
)还没有 ofox key?去 ofox.ai 注册——一个 key 直通 GPT-5.5、Claude、Gemini、Kimi 等所有主流模型。
升不升级,分场景决定
目前在生产上跑 GPT-5.4:
Agent 工作流(多步工具调用、终端自动化、浏览器操作、Computer Use)——升级。Terminal-Bench 和 OSWorld 的差距大到值得切。
长上下文分析(代码库、财报、研究文献)——为 1M 窗口升级,但先把预算算清楚。
代码库级别的修复任务——先测再说。SWE-Bench Pro 显示 Opus 4.7 可能仍然是更好的选择。
高并发、对延迟敏感的短对话——留在 5.4。GPT-5.4 短期不会下线,单次调用便宜一半。
幻觉零容忍的场景(事实问答、引用生成、合规)——先在自己数据集上跑回归。86% 的 AA-Omniscience 幻觉率不是可以忽略的信号。


