Gemini 3.5 Flash 国内接入指南(2026):Agent 评测反超 Pro,改两行代码即可调用
Google I/O 2026 发布 Gemini 3.5 Flash,Terminal-Bench 76.2%、MCP Atlas 83.6%,agent 与 coding 全面超越 3.1 Pro,速度快 4 倍。ofox.ai 已上架 google/gemini-3.5-flash,description: .5/$9 每百万 token,本文提供完整接入方案与代码示例。
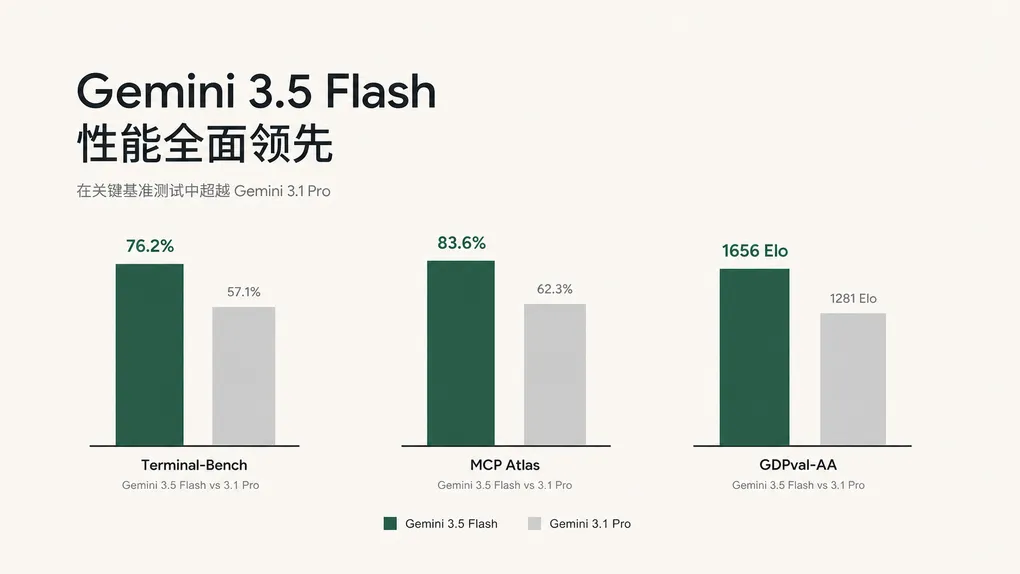
TL;DR — Google 在 2026-05-19 的 I/O 大会发布 Gemini 3.5 Flash,定位”frontier intelligence + action”。Terminal-Bench 2.1 76.2%、MCP Atlas 83.6%、GDPval-AA 1656 Elo,agent 和 coding 三项评测全面超过自家 3.1 Pro,输出速度快 4 倍。ofox.ai 已上架 google/gemini-3.5-flash,$1.5/$9 每百万 token,国内开发者改两行代码即可调用,本文给出完整方案。
为什么 Flash 突然反超 Pro
3.5 Pro 没来,Flash 先到了。这不是常规节奏。
Google I/O 2026 把 3.5 Pro 往后延期,先把 Flash 推出来。原因是这一代 Flash 在 agent 和 coding 路线上换了套训练配方,更偏工具调用、长链推理、终端环境交互,而不是纯对话生成。结果就是 Flash 跑出来的分数在 agent 类评测上压过了上一代 Pro:
- Terminal-Bench 2.1:76.2%,测的是模型在真实 shell 环境里完成多步任务的能力(找文件、改配置、跑命令、debug)
- MCP Atlas:83.6%,衡量 MCP 工具调用的可靠性,跨工具组合不出错的比例
- GDPval-AA:1656 Elo,模拟真实经济价值任务(写文档、做分析、整理数据),按 Elo 评分
- CharXiv Reasoning:84.2%,多模态图表理解和推理
这套数据对你意味着什么:如果你正在搭 AI Agent、做 Coding 助手、想跑自动化工作流又不想被 Opus 价格劝退,3.5 Flash 是当前 Google 系里性价比最高的选择,不用等 3.5 Pro。
价格与定位:为什么这次”Flash”反而值
| 模型 | 模型 ID | 输入价格 | 输出价格 | 输出速度 | 定位 |
|---|---|---|---|---|---|
| Gemini 3.5 Flash | google/gemini-3.5-flash | $1.5/M | $9/M | 4× | Agent、Coding、工具调用 |
| Gemini 3.1 Pro | google/gemini-3.1-pro-preview | $2/M | $12/M | 基准 | 复杂推理、长文档、ARC-AGI |
| Gemini 3.1 Flash-Lite | google/gemini-3.1-flash-lite-preview | $0.25/M | $1.5/M | 极快 | 高频分类、摘要 |
| Claude Opus 4.7 | anthropic/claude-opus-4-7 | $15/M | $75/M | 慢 | 顶级 coding、复杂任务 |
3.5 Flash 在价格上比 3.1 Pro 便宜 25%,但在 agent/coding 评测上反超。这种”Flash 反超 Pro”的现象上一次在 GPT 系里出现过类似情况(GPT-5.4 mini 在部分场景压过 GPT-4.1),都是因为新一代 base model 的训练目标变了。
老规矩,需要 ARC-AGI 级别抽象推理或对 128k 范围的长文档检索精度有要求,继续用 Gemini 3.1 Pro(两者上下文都是 1M,但 Pro 的 MRCR v2 检索分更高);纯靠 SWE-bench 排名挑编程模型,去看 Claude Opus 4.7 完全指南 和 2026 大模型排行榜。
国内接入:直连不通,ofox 中转 5 分钟搞定
Google AI Studio 和 Gemini API 国内都不通。三种官方入口(Google Antigravity、AI Studio、Android Studio)都需要科学上网,企业项目走这条路是坑。
ofox.ai 已经上架 google/gemini-3.5-flash,走 OpenAI 兼容协议,国内直连,延迟 300-500ms。流程:
- 注册 ofox.ai
- 充值(支持支付宝、微信、卡)
- 创建 API Key,复制
sk-开头那串 - 把
base_url改成https://api.ofox.ai/v1 model字段填google/gemini-3.5-flash
代码层面只动两行。
实战代码:3 分钟跑通
Python(OpenAI SDK)
from openai import OpenAI
client = OpenAI(
base_url="https://api.ofox.ai/v1",
api_key="sk-你的ofox密钥"
)
response = client.chat.completions.create(
model="google/gemini-3.5-flash",
messages=[
{"role": "system", "content": "你是一个擅长 shell 操作的 AI agent。"},
{"role": "user", "content": "在 Linux 下找出 /var/log 里最近 24 小时被修改的文件,给我命令。"}
],
temperature=0.3
)
print(response.choices[0].message.content)TypeScript / Node.js
import OpenAI from 'openai'
const client = new OpenAI({
baseURL: 'https://api.ofox.ai/v1',
apiKey: process.env.OFOX_API_KEY!
})
const response = await client.chat.completions.create({
model: 'google/gemini-3.5-flash',
messages: [
{ role: 'user', content: '解释 OAuth2 的 PKCE 流程,越短越好。' }
]
})
console.log(response.choices[0].message.content)cURL
curl https://api.ofox.ai/v1/chat/completions \
-H "Authorization: Bearer $OFOX_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemini-3.5-flash",
"messages": [{"role": "user", "content": "你好"}]
}'跑通后再考虑 streaming、tools、function calling。
Streaming:流式输出加速首字响应
3.5 Flash 输出 token 速度是上一代主流前沿模型的 4 倍,配合 streaming 用户体验提升明显。
stream = client.chat.completions.create(
model="google/gemini-3.5-flash",
messages=[{"role": "user", "content": "用 200 字介绍量子纠缠。"}],
stream=True
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="", flush=True)实测首字响应 200-400ms,全文 600 字大约 2 秒输出完。聊天产品、代码补全、长文本生成都用这套。
Agent 场景:function calling + 工具调用
3.5 Flash 的 MCP Atlas 跑到 83.6%,意味着多工具组合调用的可靠性显著提升。下面是一个让模型调用本地查询工具的最小例子:
tools = [{
"type": "function",
"function": {
"name": "search_database",
"description": "在订单数据库里按用户 ID 查订单",
"parameters": {
"type": "object",
"properties": {
"user_id": {"type": "string", "description": "用户 ID"},
"limit": {"type": "integer", "default": 10}
},
"required": ["user_id"]
}
}
}]
response = client.chat.completions.create(
model="google/gemini-3.5-flash",
messages=[{"role": "user", "content": "查一下用户 u_8821 最近的订单。"}],
tools=tools
)
tool_call = response.choices[0].message.tool_calls[0]
print(tool_call.function.name, tool_call.function.arguments)
# search_database {"user_id": "u_8821", "limit": 10}模型识别意图、提取参数、生成结构化 tool_call。后续把执行结果(role: “tool”)塞回 messages,模型再生成自然语言回复,标准 ReAct 循环。
常见报错与排查
401 Unauthorized——API Key 错了,检查是不是把 ofox key 当成 Google key 用,或者 base_url 没改。
404 model_not_found——model 字段写错了。Gemini 3.5 Flash 的正确 ID 是 google/gemini-3.5-flash,注意是减号不是点号(旧版本有 google/gemini-3.1-pro-preview 这种带 preview 后缀的,3.5 Flash 已经 GA 不需要)。
429 rate_limit_exceeded——并发或 RPM 超了。ofox 默认账号有限额,可以联系扩容。代码层面加指数退避:
import time
from openai import RateLimitError
for attempt in range(5):
try:
response = client.chat.completions.create(...)
break
except RateLimitError:
time.sleep(2 ** attempt)context_length_exceeded——3.5 Flash 上下文窗口同样是 1M token(输出上限 64K),超出就报这个错。但要注意 3.5 Flash 在长文档检索的精度上略逊于 3.1 Pro(MRCR v2 128k:77.3% vs 84.9%),对召回精度敏感的长文档解析建议用 3.1 Pro。
更多模型相关报错对照表,看 Claude/OpenAI/Gemini/DeepSeek 模型特定报错排查手册。
什么时候选 3.5 Flash?什么时候不选?
选 3.5 Flash 的场景:
- AI Agent 工作流,频繁调用工具(MCP Atlas 83.6%)
- Coding 助手、代码补全、终端任务自动化(Terminal-Bench 76.2%)
- 实时聊天、需要快速首字响应(输出 4× 加速)
- 高吞吐场景,预算敏感($1.5/$9 比 Claude Opus 4.7 便宜 10 倍)
不选 3.5 Flash 的场景:
- 复杂数学推导、ARC-AGI 类抽象推理(3.1 Pro 77.1% vs 3.5 Flash 72.1%)→ 用 3.1 Pro
- 长文档高精度检索(MRCR v2 128k:3.1 Pro 84.9% vs 3.5 Flash 77.3%)→ 用 3.1 Pro
- 极端编程任务(SWE-bench 顶级排名)→ 用 Claude Opus 4.7
- 极致低成本、轻量分类摘要 → 用 Gemini 3.1 Flash-Lite($0.25/$1.5)
模型矩阵这件事永远不要”一个模型走天下”。在 2026 大模型排行榜与选型指南 里我们写过更系统的选型方法论。
写在最后
以前 Flash 是 Pro 的降配版,这次反过来了。3.5 Flash 在 agent 和 coding 上压过 3.1 Pro,价格还便宜 25%。Google 显然是想用”先发 Flash”抢 agent 时代的开发者注意力,3.5 Pro 留到下次再讲。
对国内开发者来说门槛已经被聚合平台抹平。把 base_url 改成 https://api.ofox.ai/v1,model 填 google/gemini-3.5-flash,剩下的 OpenAI SDK 代码一行不用动。
剩下的就是动手跑一遍。
参考数据来源:
- Google DeepMind: Gemini 3.5 Flash Model Card
- Google Blog: Gemini 3.5: frontier intelligence with action
- ofox.ai 模型广场: https://ofox.ai/zh/models