GPT-Image-2 发布:Arena 榜碾压第二名 242 分,中文文字和 100 物体场景真的离谱 | ofox 已接入
OpenAI 在 2026 年 4 月 21 日发布 GPT-Image-2,Arena 文字生图榜 1512 分,领先第二名 Nano Banana 2 整整 242 分,是这个榜单有史以来最大的差距。本文带你看 gpt-image-2 到底离谱在哪里,以及如何通过 ofox 直接调用。

TL;DR — OpenAI 昨天(4 月 21 日)发布 GPT-Image-2。Arena 榜单 1512 分,领先第二名整整 242 分,这个榜单有史以来最大差距。支持多语言文字(中日韩都能清晰渲染)、单图稳定装下 100 个物体、编辑不走脸。ofox 已经第一时间接入,模型 ID openai/gpt-image-2,现有 Key 直接能用。
为什么这次发布值得单独写一篇
2026 年前四个月,文本生图一直是 Google 的 Nano Banana 和 OpenAI 的 GPT-Image 在榜首互换位置,分差都在几十分以内,其他模型集体卡在 1200 分以下。这种僵局昨天被打破了。

Arena Trends 2026 年 1–4 月数据。GPT-Image-2 1512 分,是这个榜单历史上第一次有模型把第二名甩开超过 100 分。来源:@arena on X
不只是文字生图第一,而是横扫了 Image Arena 所有类别的第一名。昨天还在贴身肉搏的模型,今天已经不在一个段位。
具体离谱在哪里
OpenAI 发布页基本就是个图片画廊,文字很少,让作品自己说话。看完官方示例和过去 24 小时社区的实测,四个能力能解释这个 242 分的差距。
1. 精度和控制真的上来了

最核心的变化。以前要两三轮才能对齐的提示,现在第一次就能命中。最明显的两个场景:排版里文字的精确位置,以及”加这个、其他不要动”的编辑 —— 上一代 GPT-Image-1 经常会把周围的构图也一起改掉。
人脸保持(face preservation)是同一件事的另一面。换衣服、换背景、换姿势,人脸不会被改成另一个人。这个问题以前让肖像类的生产流程基本走不通,现在可以认真用了。
2. 文字能读了 —— 不管什么语言

文字渲染一直是图像模型最明显的短板。GPT-Image-2 不只把英文做对了,中日韩阿拉伯文、以及多种文字混排都能渲染成真正可读的内容。不是”看起来像文字”,是真的能读。
下面这张是 Michael Anti(@mranti)用 GPT-Image-2 生成的 —— 提示词只有一句:“Elon Musk 的中文微信朋友圈”。
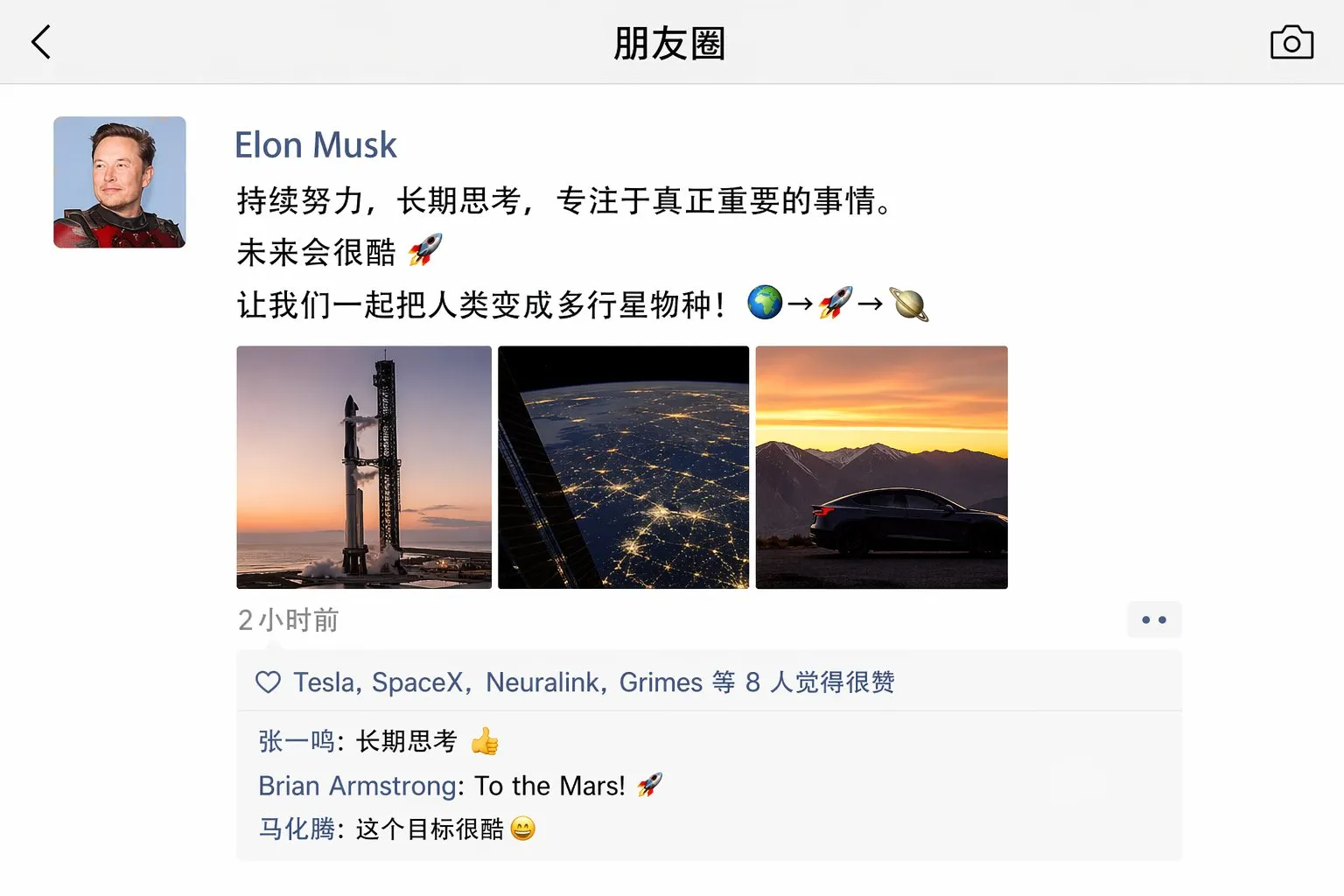
来源:@mranti on X
中文微信界面该有的元素 —— 朋友圈卡片、时间戳、头像、评论区、点赞 —— 全都有,并且中文文字是真的中文,不是乱码也不是像中文的符号。这个能力放在三个月前是做不到的。

日文漫画页同理,对白气泡里是真的日文句子,不是贴上去的。对想用 AI 做多语言海报、漫画、界面 mockup 的人来说,这条线终于走通了。
3. 单图 100 个物体,还附送清单
这个是 stress test。有人让 GPT-Image-2 生成一张”包含 100 个元素的场景”,不仅真的画了 100 个不同的物体,还在同一张图里把这 100 个物体的名字全部列了出来。

来源:@Tz_2022 on X 引用 @umesh_ai。“不仅创建了 100 个物体的场景,还把它们全部列在了图片内。”
做过商品目录图、场景图、或者任何需要”准确出现 N 个指定物体”需求的人都知道这事有多难。上一代模型要么漏物体、要么重复、要么幻觉出无关的东西。GPT-Image-2 100 个全装下,还能保证视觉上彼此区分,连名字清单都同时画进同一帧。
4. 细节密度:macOS 桌面测试
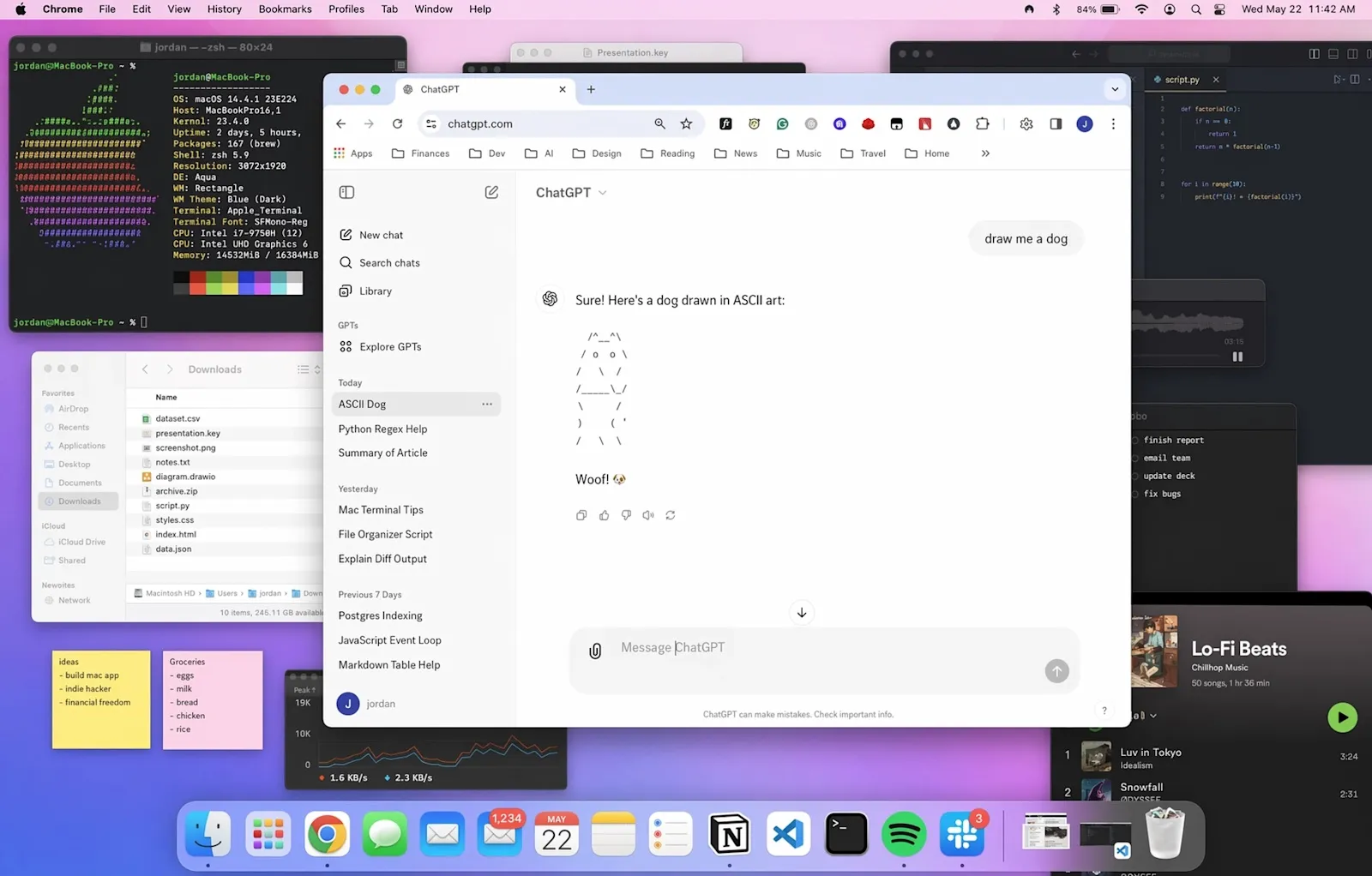
另一种密度 —— 这张 macOS 桌面有十几个打开的窗口,每个窗口里都有像模像样的 UI 内容:文件列表、代码编辑器、音乐播放器、居中的 ChatGPT 里在生成 ASCII 艺术。以前这种图得靠 PS 合成,没有哪个模型能一次性撑住这个信息量。
通过 ofox 调用
ofox 第一时间接入了 GPT-Image-2。你如果已经是 ofox 用户,改一个模型字符串就能用。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_OFOX_API_KEY",
base_url="https://api.ofox.ai/v1"
)
response = client.images.generate(
model="openai/gpt-image-2",
prompt="Bauhaus 风格的杂志封面,粗体红黑排版,大字'GPT IMAGE 2'",
size="1024x1024"
)
print(response.data[0].url)保持人脸的编辑:
response = client.images.edit(
model="openai/gpt-image-2",
image=open("portrait.png", "rb"),
prompt="把外套换成海军蓝,其他包括人脸全部保持不变",
input_fidelity="high"
)cURL 版本:
curl https://api.ofox.ai/v1/images/generations \
-H "Authorization: Bearer $OFOX_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-image-2",
"prompt": "一张包含 100 个不同物体的场景,每个物体清晰可见,图内附带这 100 个物体的完整文字清单",
"size": "1536x1024"
}'没有 ofox Key?去 ofox.ai 注册 —— 一个 Key 覆盖 GPT-Image-2、Claude、GPT-5.4、Gemini 3.1、Kimi K2.6 等全部主流模型。支付宝/微信都能付。
价格
| 项目 | 价格 |
|---|---|
| 输入文字 | $5 / M tokens |
| 输出文字 | $30 / M tokens |
| 输入图像 | $8 / M tokens |
| 输出图像 | $30 / M tokens |
| 提示缓存读取 | $1.25 / M tokens |
| 图像缓存 | $2 / M tokens |
按量计费,无月费。完整价格和支持的尺寸见 GPT-Image-2 模型页。
什么时候该用、什么时候不该用
适合用 GPT-Image-2 的场景:
- 图里要有清晰可读的文字(海报、信息图、漫画、UI mockup、包装设计)
- 场景里要稳定容纳很多不同元素
- 在已有图片上编辑、不能让人脸或构图漂移
- 多语言排版,尤其是中日韩或多文字混排
其他模型可能更合适:
- 大批量、低复杂度生成,追求最低单张成本 —— 看看 ofox 模型目录 里的 Nano Banana 或 Doubao Seedream
- 延迟比质量更重要 —— 小模型更快
- 你的 pipeline 已经绑死在某个模型的风格指纹上
三步接入
- 去 ofox.ai 注册或登录
- 在控制台拿到 API Key
- 任何 OpenAI 兼容 SDK,base URL 指向
https://api.ofox.ai/v1,模型 ID 填openai/gpt-image-2
就这样。已经在用 GPT-Image-1 的同学,改一个模型字符串就能切过来。


