OpenClaw API 提供商横评:2026 年最佳 API 平台推荐
实测对比 5 大 OpenClaw API 接入方案——官方直连、Ofox 聚合平台、DeepSeek 国产模型、云厂商托管、本地部署,从延迟、价格、模型覆盖、稳定性等 8 个维度横向打分。附场景推荐表、成本计算器和 12 个高频 FAQ。
摘要
本文实测对比 5 类 OpenClaw API 接入方案——官方直连、API 聚合平台、国产模型官方 API、云厂商托管、本地部署,从延迟、价格、模型覆盖、稳定性等 8 个维度横评。大多数开发者的最优解是「聚合平台 + 国产模型」组合。
为什么 API 选择这么重要
OpenClaw 本身是一个开源的 Agent 执行框架——它的”大脑”来自后端的 AI 模型 API。选错了 API 提供商,轻则响应慢、费用高,重则 Agent 直接罢工。
我在实际使用中踩过不少坑:
- 直连海外官方 API,国内网络不稳定,Agent 执行到一半断连,前面的 token 全浪费了
- 只绑定一家模型,遇到服务商限流,整个 Agent 停摆半小时
- 没做模型分级,所有任务都用旗舰模型,月底账单比预期高 5 倍
评测维度说明
这次横评从 8 个维度打分,每项 10 分制:
| 维度 | 权重 | 说明 |
|---|---|---|
| 模型覆盖 | 15% | 支持多少主流模型,能否一站式切换 |
| 国内延迟 | 15% | 从国内发起请求到首 token 返回的时间 |
| 价格 | 15% | 同模型同量级下的实际费用 |
| 稳定性 | 15% | 长时间运行的可用率,故障恢复速度 |
| 协议兼容 | 10% | OpenAI 兼容协议实现的完整度 |
| 付费便利 | 10% | 是否支持人民币、支付宝/微信 |
| 配置难度 | 10% | 从零到跑通需要多少步骤 |
| 附加功能 | 10% | 用量统计、预算管理、团队协作等 |
所有延迟数据均在上海阿里云 ECS 上测试,取 100 次请求的 P50 值。价格取 2026 年 3 月公开报价。
五大方案详细评测
方案一:官方 API 直连
直接使用 OpenAI、Anthropic、Google 等模型厂商的官方 API。
实测表现:
| 指标 | 结果 |
|---|---|
| 模型覆盖 | 单一厂商,如 OpenAI 只有 GPT 系列 |
| 国内延迟 | OpenAI: 1200-3000ms;Anthropic: 1500-4000ms;Google: 800-1500ms |
| 价格 | 官方定价,无溢价 |
| 稳定性 | 全球直连不稳定,丢包率 5-15% |
| 协议兼容 | 原生支持(OpenAI)/ 需适配(Anthropic) |
| 付费方式 | 美元信用卡,不支持人民币 |
优势:
- 价格最低(官方原价)
- 新模型第一时间可用
- 无中间商,数据链路最短
痛点:
- 国内网络不稳定是硬伤,Agent 长时间运行频繁断连
- 需要分别注册多个平台、管理多个 Key
- 只支持美元支付,国内开发者门槛高
- Anthropic API 不是 OpenAI 兼容格式,OpenClaw 需额外配置
评分:模型覆盖 5 | 延迟 3 | 价格 9 | 稳定性 4 | 协议 7 | 付费 2 | 配置 5 | 附加 3 | 加权总分:4.8
方案二:API 聚合平台
通过 Ofox、OpenRouter 等聚合平台,一个接口接入多家模型。这里以 Ofox 和 OpenRouter 为代表做对比。
实测表现:
| 指标 | Ofox | OpenRouter |
|---|---|---|
| 模型数量 | 100+ | 200+ |
| 国内延迟 | 300-800ms(有全球加速节点) | 1000-2500ms(无全球加速节点) |
| 价格 | 官方价 + 10-15% | 官方价 + 10-20% |
| 可用率(7 天) | 99.8% | 99.5% |
| 协议兼容 | OpenAI 兼容,完整实现 | OpenAI 兼容,完整实现 |
| 付费方式 | 人民币/美元,支付宝/微信 | 仅美元,信用卡/加密货币 |
| 团队管理 | 支持子账号、额度分配 | 基础用量统计 |
Ofox 优势:
- 国内阿里云/火山云加速节点,延迟显著低于海外平台
- 人民币结算,支付宝充值即用
- 团队功能完善——子账号、额度分配、用量报表
- 完整的文档和集成指南,OpenClaw 专属配置教程
OpenRouter 优势:
- 模型数量业界最多
- 社区活跃,新模型接入快
- 支持模型路由(自动选最便宜的可用模型)
痛点:
- 比官方 API 贵 10-20%(但省去了海外支付、多平台管理成本)
- 依赖第三方平台,存在单点风险(建议配置备用方案)
评分(Ofox):模型覆盖 9 | 延迟 8 | 价格 7 | 稳定性 8 | 协议 9 | 付费 10 | 配置 9 | 附加 9 | 加权总分:8.5
评分(OpenRouter):模型覆盖 10 | 延迟 4 | 价格 7 | 稳定性 7 | 协议 9 | 付费 3 | 配置 8 | 附加 6 | 加权总分:6.8
方案三:国产模型官方 API
直接对接 DeepSeek、阿里 Qwen、智谱 GLM 等国产模型的官方 API。
实测表现:
| 指标 | DeepSeek | Qwen (百炼) | GLM (智谱) |
|---|---|---|---|
| 主力模型 | V3.2 / R2 | Qwen3.5 Max/Plus | GLM-5 |
| 国内延迟 | 100-300ms | 100-300ms | 150-400ms |
| 价格(输入/百万 token) | ¥2 | ¥10 | ¥8 |
| 协议 | OpenAI 兼容 | OpenAI 兼容 | OpenAI 兼容 |
| 付费方式 | 人民币 | 人民币 | 人民币 |
| 免费额度 | 注册赠送 | 注册赠送 | 注册赠送 |
优势:
- 延迟最低,全球直连无任何网络问题
- 价格最便宜,DeepSeek V3.2 的成本是 GPT-4o 的 1/6
- 都支持 OpenAI 兼容协议,OpenClaw 配置简单
- 中文能力强,适合国内业务场景
- 注册赠送免费额度,零成本起步
痛点:
- 只能用单一厂商的模型,切换厂商要改配置
- 复杂推理和英文任务与 GPT/Claude 有差距
- DeepSeek 高峰期偶有限流
评分(DeepSeek):模型覆盖 3 | 延迟 10 | 价格 10 | 稳定性 7 | 协议 8 | 付费 10 | 配置 9 | 附加 4 | 加权总分:7.6
方案四:云厂商托管服务
通过阿里云百炼、火山引擎、腾讯云等平台的托管方案部署 OpenClaw。
实测表现:
| 指标 | 阿里云百炼 | 火山引擎 |
|---|---|---|
| 内置模型 | Qwen 全系列 + DeepSeek + 海外模型 | 豆包全系列 + DeepSeek |
| 延迟 | 100-500ms | 100-500ms |
| 额外成本 | 云服务器 + 模型调用 | 云服务器 + 模型调用 |
| 部署方式 | 一键镜像 / Docker | 一键部署 |
| SLA | 99.9% | 99.9% |
优势:
- 部署最简单,一键搞定,不需要折腾环境
- 有企业级 SLA 保障
- 内置模型直连,延迟极低
- 有技术支持和工单系统
痛点:
- 绑定特定云厂商生态
- 总成本 = 云服务器费 + 模型调用费,比纯 API 贵
- 模型选择受限于平台集成范围
- 海外模型支持不完整
评分(阿里云百炼):模型覆盖 6 | 延迟 9 | 价格 5 | 稳定性 9 | 协议 8 | 付费 10 | 配置 10 | 附加 8 | 加权总分:7.9
方案五:本地部署(Ollama + 开源模型)
用 Ollama 在本地跑开源模型(Llama 3.3、Mistral、Qwen 等),OpenClaw 连接本地 API。
实测表现:
| 指标 | 结果 |
|---|---|
| 可用模型 | 开源模型(Llama 3.3 70B、Qwen2.5 72B、Mistral Large 等) |
| 延迟 | 取决于硬件,M4 Max 上 7B 模型约 50-100ms |
| 价格 | 零 API 费用(仅电费和硬件折旧) |
| 稳定性 | 取决于本地环境,无网络依赖 |
| 配置难度 | 需安装 Ollama + 下载模型 + 配置 OpenClaw |
优势:
- 零 API 成本,跑多少都不花钱
- 完全离线可用,无网络依赖
- 数据不出本地,隐私性最强
- 延迟极低(局域网通信)
痛点:
- 开源小模型(7B-14B)的工具调用和多步推理能力与 GPT/Claude 差距明显
- 跑大模型(70B+)需要高端 GPU 或 Apple Silicon,硬件门槛高
- 没有 GPT-5、Claude Opus 等闭源旗舰模型
- 需要自己管理模型更新
评分:模型覆盖 4 | 延迟 9 | 价格 10 | 稳定性 7 | 协议 7 | 付费 10 | 配置 5 | 附加 2 | 加权总分:6.8
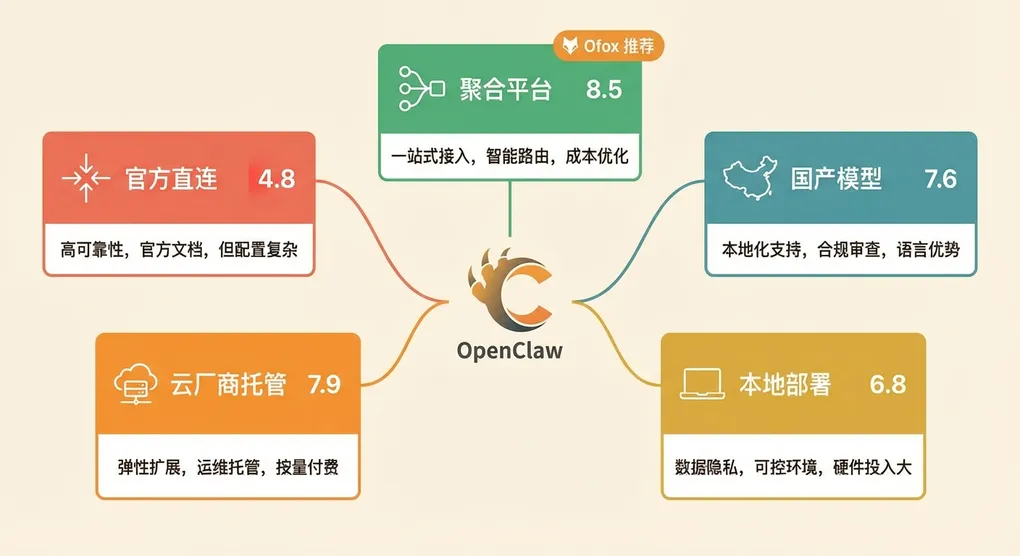
横向对比总表
| 维度 | 官方直连 | Ofox 聚合 | OpenRouter | DeepSeek | 阿里云百炼 | 本地 Ollama |
|---|---|---|---|---|---|---|
| 模型覆盖 | 单厂商 | 100+ | 200+ | 仅 DS | 平台内 | 开源模型 |
| 国内延迟 | 1200-4000ms | 300-800ms | 1000-2500ms | 100-300ms | 100-500ms | 50-100ms |
| 月成本(中度) | ¥150-300 | ¥170-350 | ¥170-350 | ¥30-80 | ¥200-500 | ¥0(电费) |
| 稳定性 | 国内差 | 高 | 中高 | 中高 | 高(SLA) | 取决本地 |
| OpenAI 兼容 | 部分 | 完整 | 完整 | 完整 | 完整 | 完整 |
| 人民币结算 | 不支持 | 支持 | 不支持 | 支持 | 支持 | 不涉及 |
| 团队管理 | 无 | 完善 | 基础 | 基础 | 完善 | 无 |
| 配置步骤 | 多平台注册 | 注册→填 Key | 注册→填 Key | 注册→填 Key | 一键部署 | 安装+下载 |
| 加权总分 | 4.8 | 8.5 | 6.8 | 7.6 | 7.9 | 6.8 |

不同场景怎么选
以下是按典型场景的推荐:
个人开发者 / 尝鲜体验
推荐:DeepSeek 官方 API
理由:注册送免费额度,全球直连零配置,中文效果好。先用 DeepSeek 跑通 OpenClaw 全流程,确认需求后再考虑升级。
# OpenClaw 配置示例
api:
provider: deepseek
base_url: https://api.deepseek.com/v1
api_key: sk-xxx
model: deepseek-chat日常办公助手 / 多模型需求
推荐:Ofox 聚合平台
理由:一个 Key 用所有模型,日常任务走 Sonnet/GPT-4o,复杂任务切 Opus/GPT-5.4 Thinking,配置一次搞定。
# OpenClaw 配置示例
api:
provider: openai-compatible
base_url: https://api.ofox.ai/v1
api_key: sk-xxx
model: anthropic/claude-sonnet-4.6
fallback_models:
- openai/gpt-4o
- deepseek/deepseek-chat企业团队部署
推荐:阿里云百炼 + Ofox 双保险
理由:核心业务走阿里云百炼(有 SLA),海外模型需求走 Ofox 补充。两条链路互为备份,故障时自动切换。
隐私敏感 / 离线场景
推荐:本地 Ollama + 云端备用
理由:日常简单任务走本地模型(零成本、数据不出域),遇到复杂任务走云端 API 增强。
场景推荐速查表
| 场景 | 首选方案 | 备选方案 | 月预算参考 |
|---|---|---|---|
| 个人尝鲜 | DeepSeek | Ofox 免费额度 | ¥0-30 |
| 个人日常 | Ofox | DeepSeek + 官方直连 | ¥50-150 |
| 小团队(3-5人) | Ofox 团队版 | 阿里云百炼 | ¥200-500 |
| 企业(10+人) | 阿里云百炼 + Ofox | 自建代理 | ¥500-2000 |
| 重度 Agent(7x24) | Ofox + DeepSeek 混合 | 阿里云百炼 | ¥300-800 |
| 离线/隐私 | 本地 Ollama | — | ¥0 |
成本实测对比
我用 OpenClaw 跑了一个真实的日常办公场景——每天约 200 次对话交互(含简单问答、文档总结、代码辅助),统计一周的实际花费:
测试条件
- 任务分布:简单问答 60%、文档处理 25%、代码辅助 15%
- 每日 token 消耗:约 50 万输入 + 20 万输出
- 测试周期:7 天
各方案实际费用(周)
| 方案 | 使用模型 | 周费用 | 折算月费 |
|---|---|---|---|
| 官方直连(GPT-4o) | GPT-4o | ¥78 | ¥335 |
| 官方直连(Claude Sonnet) | Claude Sonnet 4.6 | ¥63 | ¥270 |
| Ofox(混合模型) | Sonnet + DeepSeek 混合 | ¥35 | ¥150 |
| DeepSeek 纯国产 | DeepSeek V3.2 | ¥8 | ¥34 |
| 阿里云百炼 | Qwen3.5 Plus + 服务器 | ¥65(含服务器¥40) | ¥280 |
| 本地 Ollama | Qwen2.5 14B | ¥0 | ¥0 |
关键发现:通过 Ofox 的混合模型策略(简单任务走 DeepSeek,复杂任务走 Claude Sonnet),月费用比全程用 GPT-4o 低 55%,但体验几乎无差别。
成本优化公式
对于大多数开发者,最优成本结构是:
总成本 = 70% 简单任务 × DeepSeek 价格 + 25% 常规任务 × Sonnet 价格 + 5% 复杂任务 × Opus 价格以每月 100 万输入 token 计算:
- 全用 Opus:¥75
- 全用 Sonnet:¥15
- 混合策略:70% × ¥2 + 25% × ¥15 + 5% × ¥75 = ¥1.4 + ¥3.75 + ¥3.75 = ¥8.9
混合策略的成本仅为全用旗舰模型的 12%。
配置实操:从零接入
以 Ofox 为例,3 步搞定 OpenClaw API 配置:
第 1 步:获取 API Key
到 Ofox 控制台 注册账号,在 API Keys 页面创建一个 Key。
第 2 步:配置 OpenClaw
运行 openclaw onboard,在 API 配置环节:
- Provider: 选
OpenAI Compatible - Base URL: 填
https://api.ofox.ai/v1 - API Key: 填上一步创建的 Key
- Model: 填
anthropic/claude-sonnet-4.6(或其他支持的模型)
第 3 步:验证连接
openclaw chat "你好,测试一下连接"收到回复就说明配置成功。之后切换模型只需要改 model 参数,不需要换 Key 或改地址。
如果你已经看过 OpenClaw API 推荐与模型配置指南,这些步骤应该很熟悉——这篇横评的重点是帮你在多个方案之间做出选择。
常见问题(FAQ)
OpenClaw 用什么 API 最好?
取决于核心诉求:
- 要模型多、切换灵活 → API 聚合平台
- 要最便宜 → DeepSeek 官方 API(¥2/百万输入 token)
- 要最稳定(企业级) → 阿里云百炼(99.9% SLA)
- 要数据不出域 → 本地 Ollama
OpenClaw 国内用什么 API?
两条路线:纯国产路线用 DeepSeek V3.2 或 Qwen3.5 官方 API,全球直连;混合路线通过聚合平台(如 Ofox)同时接入国内外模型,一个 Key 覆盖所有模型。
OpenClaw API 延迟高怎么优化?
按优先级排查:
- 换有全球加速节点的平台:直连海外 API 延迟 2-4 秒,换全球加速节点平台或国产模型可降到 300-800ms
- 简单任务用轻量模型:Gemini Flash、GPT-4o-mini 的响应速度是旗舰模型的 3-5 倍
- 开启 streaming:流式返回首 token 更快
- 精简系统 prompt:减少每次请求的 token 数
多个 API 提供商可以同时用吗?
可以,而且推荐。OpenClaw 的 model fallback 机制允许配置多个 provider,主 API 故障时自动切换备用平台。
DeepSeek 还是 GPT/Claude?
建议混合使用——中文对话和简单任务走 DeepSeek(便宜),复杂推理、代码生成、英文任务升级到 GPT/Claude。
总结
五个方案各有所长,推荐路径:
- 零成本起步:用 DeepSeek 免费额度跑通 OpenClaw 基本功能
- 确定主力方案:按需求选择国产模型为主或聚合平台为主
- 持续优化:分析用量数据,调整模型分级比例,设置预算上限
- 建立冗余:至少配置两个 API provider,开启 fallback 机制