OpenClaw 国内加速指南:延迟优化 + 国产模型推荐(2026)
一句话总结:换个接入方式,体验天差地别
OpenClaw 在国内火得一塌糊涂——GitHub 25 万 Star,微信群、飞书群到处都是人在部署。但我收到最多的反馈不是”怎么装”,而是”怎么这么慢”。
问题基本都出在同一个地方:直连海外 API,请求绕了大半个地球再回来。加上模型选得不对,一个简单的任务等十几秒才出第一个字,体验直接崩了。
这篇文章讲两件事:怎么把延迟降下来,以及国产模型里哪些真的能打。不是理论分析,是我们自己跑了一圈之后的实测数据。
为什么 OpenClaw 在国内会卡
延迟有两层:
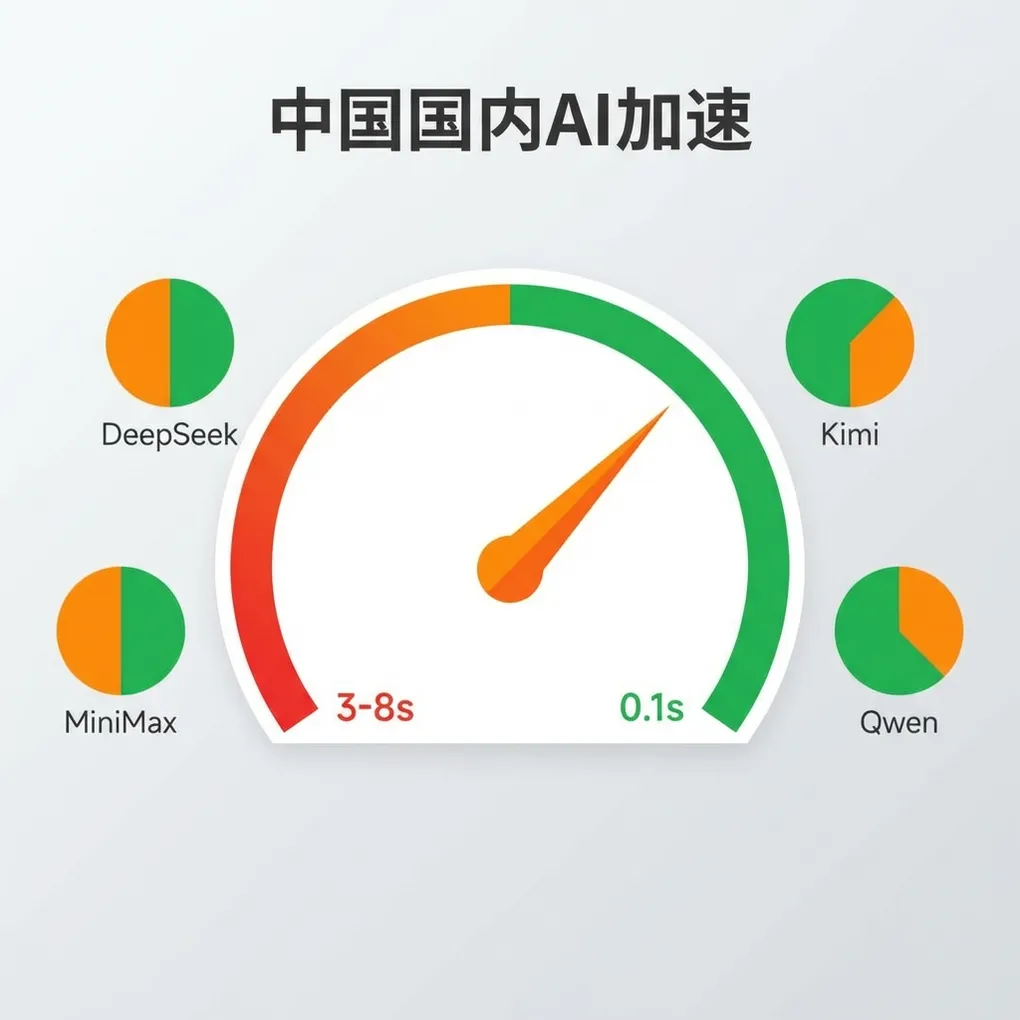
第一层是网络。 你的请求从国内出发,到达 OpenAI/Anthropic 的美西服务器,再把结果传回来。光物理距离就够喝一壶了,再加上国际出口带宽的波动,白天高峰期首 token 延迟 3-5 秒是常态,晚上能到 8 秒以上。
第二层是模型推理。 旗舰模型(Opus 4.6、GPT-5.4)本身推理就慢。你在网络延迟的基础上再叠一层模型延迟,最终体验就是”发了消息以为卡死了”。
两层都要解决,只解决一层效果有限。
5 种加速方案实测对比
我们测了市面上主流的几种方案,统一用 OpenClaw 执行同一个任务(让 Agent 写一个 Python 脚本),记录首 token 延迟和整体完成时间。
| 方案 | 首 token 延迟 | 稳定性 | 月成本 | 适合谁 |
|---|---|---|---|---|
| 直连官方 API | 3-8s | 差,高峰丢包 | 官方价 | 有稳定梯子的个人 |
| Cloudflare Worker 中转 | 1.5-3s | 中等 | ~$5/月 | 爱折腾的开发者 |
| 自建香港服务器代理 | 0.8-1.5s | 好 | ¥50-100/月 | 小团队 |
| API 聚合平台(如 Ofox) | 0.3-0.8s | 好 | 按量付费 | 大多数人 |
| 国产模型直连 | 0.1-0.3s | 很好 | 按量付费 | 追求极致速度 |
直连是最差的方案,高峰期完全不可用。CF Worker 中转聊胜于无,Cloudflare 亚洲节点质量参差不齐,有时候比直连还慢。自建代理效果可以,但你得自己运维,服务器挂了 Agent 就停摆。聚合平台走港线加速对大多数人来说最实际,不用运维,延迟也够低。国产模型直连当然最快,只是不是所有任务都合适。
我个人的方案是:通过 Ofox 接入,日常任务用国产模型(直连速度快),偶尔需要旗舰模型时通过 Ofox 的港线加速调用 Claude 或 GPT。一个 API Key 全搞定,不用来回切。
如果你还没配置过 OpenClaw 的 API 接入,先看这篇:《OpenClaw 国内使用完全攻略》。
国产模型在 OpenClaw 上的实测表现
光说”国产模型便宜”没用,关键是放到 OpenClaw 的实际任务里能不能打。我们测了 6 款国产模型,跑了三类任务:代码生成、中文内容写作、工具调用(function calling)。
测试结果
| 模型 | 代码生成 | 中文写作 | 工具调用 | 首 token | 价格(输入/输出) |
|---|---|---|---|---|---|
| DeepSeek V3.2 | ★★★★ | ★★★★★ | ★★★★ | 0.15s | 极低 |
| MiniMax M2.7 | ★★★★ | ★★★★ | ★★★★★ | 0.12s | $0.0003/$0.0012 |
| Kimi K2 | ★★★★ | ★★★★ | ★★★★★ | 0.2s | 中等 |
| Qwen3.6 Plus | ★★★☆ | ★★★★ | ★★★★ | 0.18s | $0.0005/$0.003 |
| GLM-5V Turbo | ★★★☆ | ★★★★ | ★★★☆ | 0.25s | $0.0012/$0.004 |
| 豆包 Pro | ★★★ | ★★★★ | ★★★ | 0.2s | 低 |
逐一点评
DeepSeek V3.2 — 中文场景的性价比之王
V3.2 是 DeepSeek 最新的通用模型,中文理解能力在国产里数一数二。写博客、做翻译、处理中文文档这些任务,效果比 GPT-5.4 还好一点(没错,中文任务上国产模型确实有优势)。代码生成也不拉胯,常规的 Python/JS 脚本写得像模像样。
缺点是遇到特别复杂的多步推理时,准确率会下降。如果你的 OpenClaw Agent 要处理复杂的工作流编排,建议关键步骤还是切旗舰模型。
MiniMax M2.7 — 速度怪物
M2.7 是这次测试里响应最快的,200K 上下文窗口在国产模型里算大的,SWE-bench 跑分也不错。特别适合那种需要 Agent 快速迭代、频繁调用的场景——比如让 OpenClaw 连续执行十几个小任务,M2.7 的速度优势会非常明显。
价格是真的便宜。输入 $0.0003/M tokens,输出 $0.0012/M tokens,大概是 Claude Sonnet 的十分之一。
想了解 MiniMax 系列模型的详细对比,看这里:《MiniMax M2.5 API 接入教程》。
Kimi K2 — Agent 工具调用最强
月之暗面专门为 Agent 场景优化过 K2,工具调用的准确率和格式规范度在国产模型里最高。如果你的 OpenClaw 配了很多自定义工具(MCP server、外部 API 等),K2 是最稳的选择。
256K 上下文也是亮点,处理长文档不用担心截断。
Kimi 系列的详细接入方法:《Kimi K2.5 API 接入教程》。
Qwen3.6 Plus — 阿里的新旗舰
刚上线不久,支持图片和视频理解,多模态能力在国产里排前列。如果你需要 OpenClaw 处理图片相关的任务(比如分析截图、识别文档),Qwen3.6 是个不错的选择。
纯文本任务的话,跟 DeepSeek V3.2 差不多,没有特别突出的优势。
GLM-5V Turbo — 多模态老将
智谱的 GLM-5 系列参数量大(744B),多模态能力扎实。但在 OpenClaw 的实际使用中,它的工具调用格式偶尔会出问题——大概 5% 的概率返回格式不符合预期,导致 Agent 需要重试。这在连续执行任务时会影响效率。
如果智谱后续修复这个问题,GLM-5 会是很有竞争力的选项。
豆包 Pro — 够用但不出彩
字节的豆包 Pro 胜在便宜和稳定,但各项能力都比较中规中矩。适合预算特别紧、对输出质量要求不高的场景。
我的推荐方案:混合配置
| 任务类型 | 推荐模型 | 理由 |
|---|---|---|
| 日常对话和简单任务 | MiniMax M2.7 | 速度快、便宜 |
| 中文内容生成 | DeepSeek V3.2 | 中文理解最好 |
| 工具调用和 Agent 编排 | Kimi K2 | function calling 最准 |
| 复杂推理和代码 | Claude Opus 4.6(通过 Ofox 加速) | 旗舰能力无可替代 |
| 图片理解 | Qwen3.6 Plus | 多模态最强 |
在 OpenClaw 里切模型很简单,运行时用 /model 命令就能动态切换。如果你通过 Ofox 接入,所有这些模型——国产的、海外的——都在同一个 API Key 下,改个模型名就行,不用改 base_url。
模型具体怎么配?看这篇:《OpenClaw 模型配置完全教程》。
配置示例:通过 Ofox 接入国产模型
在 OpenClaw 的配置文件(openclaw.json 或 .env)里:
OPENAI_API_KEY=sk-你的ofox密钥
OPENAI_BASE_URL=https://api.ofox.ai/v1然后在模型配置里指定国产模型:
{
"model": "deepseek/deepseek-v3.2",
"fallback": "minimax/minimax-m2.7"
}这样主模型用 DeepSeek,如果 DeepSeek 临时不可用,自动切到 MiniMax 兜底。一行配置搞定,不用自己写 fallback 逻辑。
Ofox 支持支付宝和微信支付,新用户有免费额度可以先试试效果。具体的注册和密钥获取流程这里不重复了,之前写过:《OpenClaw API 推荐与模型配置指南》。
几个容易忽略的加速细节
OpenClaw 默认就是 streaming 模式,但要确认你的 API 提供商也支持——有些小平台的 streaming 实现有 bug,反而更慢。Streaming 不减少总耗时,但首 token 到得快,体感完全不一样。
另一个容易忽略的点是 max_tokens。工具调用只需要返回一段 JSON,根本用不到 4096 token 的默认上限。设成 512 或 1024,模型少生成一些垃圾 token,速度立刻提上去。
如果你的 Agent 有比较长的固定 system prompt,选支持 prompt caching 的模型(Claude 系列、DeepSeek 都支持)。缓存命中后重复的 prompt 不需要重新处理,首 token 延迟能再降 30-50%。这个优化在高频调用场景下效果很明显。
更多模型选择和费用优化的内容,看这篇:《OpenClaw 模型推荐 2026:排行榜 + 场景选型》。
最后
一年前大家还觉得”正经事还是得用 Claude 或 GPT”,现在越来越多人发现不是这么回事了。DeepSeek 写中文比 GPT 好,MiniMax 跑小任务比 Sonnet 快十倍还便宜十倍,Kimi 的工具调用比谁都规矩。再加上国内直连零延迟的网络优势,很多场景下国产模型不是”凑合用的替代品”,是更好的选择。
别死守一个模型就对了。
想看 API 接入方案的完整对比,参考:《OpenClaw API 提供商对比》。