Qwen3.6 Plus vs GLM-5.1 怎么选:闭源精调旗舰 vs 开源 MoE 巨兽(2026)
Qwen3.6 Plus(1M context、$0.5/M)和 Z.AI GLM-5.1(754B MoE、MIT 开源)是 2026 春两条截然不同的国产路线。本文用 SWE-Bench、Terminal-Bench 2.0 真实跑分对比、价格账算到 token 级,给出按场景选型的明确建议。

TL;DR — Qwen3.6 Plus 是阿里走精调闭源路线的当前旗舰:1M context、$0.5/M 输入、Terminal-Bench 2.0 拿下 61.6 分压住 Claude 4.5 Opus。GLM-5.1 是 Z.AI 走全开源 MoE 路线的反击:754B 总参 40B 激活、MIT 授权、SWE-Bench Pro 58.4 分坐稳开源第一。两个模型 ofox 都上架了,OpenAI 兼容协议直接切。日常补丁选 Qwen 便宜,工程级 Agent 选 GLM 稳。
两条完全不同的路线,撞到了同一个春天
2026 年 3 月 31 日,阿里发布 Qwen3.6 Plus,定位是”production team 实际会部署的版本”——比 Flash 强,比 72B/235B 便宜。Plus 这一档历来闭源,这次也没例外,API-only。同系列开源的留给 Qwen3.6-27B 和 35B-A3B 这两个 dense / MoE 衍生版。
七天后,4 月 7 日,Z.AI(前身智谱)甩出 GLM-5.1。754B MoE、40B 激活、MIT 协议、Hugging Face 全权重下载。SWE-Bench Pro 58.4 分,全球开源第一,把 GPT-5.4(57.7)和 Claude Opus 4.6(57.3)都按了下去。
一个把旗舰锁进 API,一个把旗舰直接扔出来给你拿走。这是 2026 年 Q2 国产大模型最有意思的分歧。
上手第一印象:参数、价格、上下文
把核心规格摊开对比,差异比想象中大:
| 项目 | Qwen3.6 Plus | GLM-5.1 |
|---|---|---|
| 发布日期 | 2026-03-31 | 2026-04-07 |
| 性质 | 闭源 / API-only | 开源 / MIT |
| 架构 | 未公开(推测 dense + 长上下文优化) | 754B MoE,40B 激活 |
| Context | 1,048,576 tokens(1M) | 200,000 tokens |
| 最大输出 | 65,536 tokens | 131,072 tokens |
| 训练硬件 | 未公开(推测 NVIDIA) | 约 100,000 张华为昇腾 910B |
| 输入价格(ofox) | $0.5 / M token | $1.4 / M token |
| 输出价格(ofox) | $3 / M token | $4.4 / M token |
Qwen 这一档输入便宜约 2.8 倍、输出便宜约 1.5 倍,Context 大五倍,但输出窗口只有 GLM 一半。GLM 的输出长度是它瞄准长程 Agent 任务的关键卖点,一次性写 13 万 token 的 patch 计划不用截断。
价格差距别只看小数点,token 量大了之后会拉开数百到上千美元的月账单。下面有详细算账环节。
SWE-Bench 数字怎么读:Verified vs Pro 不是同一道题
两个模型官方放出的 SWE-Bench 不是同一个版本,直接拉数字对比会误导:
- SWE-Bench Verified(Qwen3.6 Plus 跑的):500 道人工筛选的简化版,问题描述清楚、有明确测试用例。Qwen3.6 Plus 在这套上拿了 78.8%。
- SWE-Bench Pro(GLM-5.1 跑的):2026 年新出的进阶版,加入更复杂的 monorepo 修改、跨文件改动、容易踩坑的 edge case。GLM-5.1 在这套上拿了 58.4%。
Verified 78.8% 和 Pro 58.4% 看着差 20 分,实际是两套题在测两种能力,不能简单做减法。从同行模型的交叉数据看:Claude Opus 4.6 在 Verified 上 79.4%、Pro 上 57.3%,两套题的难度差大约就是 20 分。把这个差值套回来,Qwen3.6 Plus 和 GLM-5.1 在编程能力上其实非常接近,差距小到要看具体任务类型。
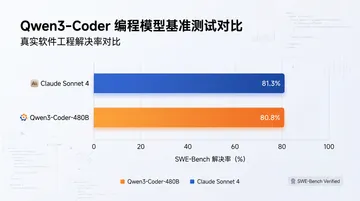
更有参考价值的是 Terminal-Bench 2.0。这个测 agentic coding,模型要自己跑 shell、读文件、装依赖、跑测试、看报错改代码,全流程闭环。Qwen3.6 Plus 拿了 61.6 分,明显领先 Claude 4.5 Opus;GLM-5.1 在这条测试上的成绩是 50 分级,落后 Qwen 大约 10 分。
结论是:Qwen3.6 Plus 在”快进快出”的 agentic coding 里更强,GLM-5.1 在”长程任务、复杂仓库”的工程修改里更稳。两个模型不是替代关系,是分工关系。
闭源 vs 开源:你拿到的不是同一个东西
API 调用层面,两个模型没差别。base_url 一换,model 字段一改,跑起来都是 OpenAI 兼容的 chat completion。但拿到的”产品”是两码事。
调 Qwen3.6 Plus,你在租一个黑盒能力:
- 能力够强,但权重看不见、模型结构没公开
- 阿里改动 API 行为(限流、加 safety filter、调价、deprecate)你只能跟着改
- 私有部署没门路(开源版的 27B / 35B-A3B 是另一回事,能力档次不同)
- 数据合规要走云服务条款
调 GLM-5.1,你拿到的是一份完整资产:
- 权重直接下 Hugging Face,本地拉一份就跑
- 想换 vLLM / SGLang / llama.cpp 推理引擎随便挑
- 想在内网部署、加自家 safety layer、Fine-tune 出垂直版本——MIT 协议不拦你
- 单卡跑不动?754B 总参确实劝退普通显卡,但服务器集群 / 云租 H100 / NVIDIA GB200 都能撑
GLM-5.1 还有个被忽略的角度:训练全程在大约 100,000 张华为昇腾 910B 上完成,用 MindSpore 框架,没用一张 NVIDIA 卡。这件事对外购 NVIDIA 受限的企业来说是真正的供应链信号:模型可以训出来,推理也能在国产硬件链路上闭环。对大部分开发者来说这不是日常关心的,但对央企 / 信创 / 涉密场景,这是一票否决项变成一票通过项的差别。
价格账:每天 100 万 token 跑 30 天,差多少钱
模型对比里光看”per million token”经常没感觉。换个真实场景算账:假设一个团队的 RAG 助手每天处理 100 万 token 输入 + 30 万 token 输出,跑满 30 天。
| 项目 | Qwen3.6 Plus | GLM-5.1 |
|---|---|---|
| 30 天总输入 | 30M token | 30M token |
| 30 天总输出 | 9M token | 9M token |
| 输入费用 | $0.5 × 30 = $15 | $1.4 × 30 = $42 |
| 输出费用 | $3 × 9 = $27 | $4.4 × 9 = $39.6 |
| 月账单 | 约 $42 | 约 $81.6 |
GLM-5.1 的账单约是 Qwen 的 1.9 倍。注意价差结构:输入差 2.8 倍、输出差 1.5 倍。RAG 这种输入大输出小的场景会把差距拉到接近 2 倍以上;Agentic Coding 这种输出占比高的场景反而会让两边账单更接近。
但反过来看,GLM-5.1 在长程 Agent 任务里成功率更高,平均一个任务的重试次数少。Qwen 单价低 ≠ 总成本低,要看任务复杂度和重跑率。下面给个粗略决策:
- 任务平均 < 5K token 输出,重跑率 < 10%:选 Qwen3.6 Plus,便宜直接收益
- 任务平均 > 30K token 输出,需要多步规划:选 GLM-5.1,单次成功率换回价差
- 需要私有部署或数据不出境:选 GLM-5.1 自托管,跟 API 价格脱钩
在 ofox 一键切换:实际代码
两个模型都在 ofox.ai 模型广场里上架了,OpenAI 兼容协议,一个 API Key 跑通。
from openai import OpenAI
client = OpenAI(
api_key="sk-ofox-xxx",
base_url="https://api.ofox.ai/v1"
)
# Qwen3.6 Plus:日常补丁、cost-sensitive 任务
resp_qwen = client.chat.completions.create(
model="bailian/qwen3.6-plus",
messages=[{"role": "user", "content": "重构这段函数,加 type hint"}],
)
# GLM-5.1:长程 Agent、复杂工程任务
resp_glm = client.chat.completions.create(
model="z-ai/glm-5.1",
messages=[{"role": "user", "content": "审计这个 repo 的安全漏洞,给修复 PR"}],
)切模型只改 model 字段,其他全不动。AB 跑同一个任务对比成本和质量,半小时就能跑出团队自己的选型证据。
需要展开 Function Call / Tool Use / Streaming 完整配置可以参考 GLM-5 API 完全教程 和 通义千问 Qwen API 接入指南,两边的 SDK 调用细节都讲到了。
怎么选:三个场景把决策摊明白
场景一:搭一个企业知识库 RAG,每天百万 token 量级
选 Qwen3.6 Plus。1M context 让长文档不用切片,输入价格 $0.5 进一步压低 token 成本。RAG 任务平均输出短(几百到几千 token),输入便宜近 3 倍的优势直接落地。
场景二:跑长程 Agent,一个任务自主跑 30 分钟以上
选 GLM-5.1。SWE-Bench Pro 58.4 是开源第一不是吹的,长程任务的稳定性、规划质量、错误恢复能力都比 Qwen3.6 Plus 更稳。13 万 token 的输出上限让 Agent 一次性写完完整方案不被截断。
场景三:需要私有化部署,数据不能离开内网
选 GLM-5.1 自托管。Qwen3.6 Plus 闭源 API-only,私有化没门路;GLM-5.1 MIT 协议,权重下载本地跑,合规问题原地解决。硬件预算够上 4×H100 或华为昇腾 910B 集群就能跑起来。
场景四:还在选型阶段,没决定下来
两个都通过 ofox 接进 staging 环境跑一周。同一批 prompt 同步打两个模型,记录 latency、quality、cost。选型证据用真实数据说话比看 benchmark 强。其他模型横评数据可以参考 2026 大模型排行榜与选型指南。
写在最后
Qwen3.6 Plus 和 GLM-5.1 不是同一道题的两个答案,是两道不同题的最优解。阿里把精力押在闭源精调上换来更便宜更长上下文,Z.AI 把全套权重直接开源换来生态主导权和供应链自主。
国产模型走到 2026 年 Q2,已经不需要”对标 GPT-4”这种叙事。SWE-Bench Pro 全球第一、Terminal-Bench 2.0 压住 Claude 4.5 Opus,这些数字摆在那里。值得讨论的是哪条路线适配哪种业务。
选型没有”哪个更强”的标准答案。把场景说清楚,数字摆出来,跑两天 staging,决策自己就出来了。