
Slack 里的 Claude Tag(2026):4 步配置、ambient 模式、8 月 3 日截止
Claude Tag 是 Slack 里跑 Opus 4.8 的共享 @Claude 队友。4 步上手、ambient 模式、管理员权限,以及 2026-08-03 从 Claude in Slack 迁移的截止时间。

在本地跑 GLM 5.2(2026):2-bit 塞进 256GB Mac,或一台 4090 主机
本地跑 GLM 5.2(753B):2-bit 量化能塞进 256GB Mac Studio,4-bit 要 512GB,速度 ~3-9 tok/s。附 llama.cpp、LM Studio 和 4090 主机的 GGUF 量化档选型。
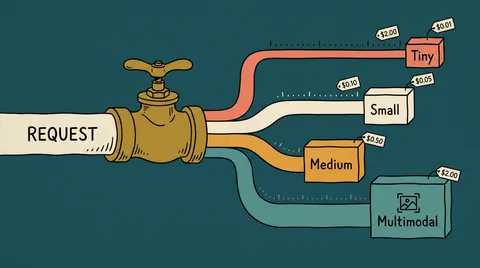
一个 API 路由 GLM-5.2、DeepSeek V4、MiniMax M3 和 Kimi K2.6(2026)
一把 ofox key 路由 4 个模型:blended 单价从 $0.19/M(V4 Flash)到 $2.40/M(GLM-5.2),差 12.86x。1M context、V4 cache 免费。一张每天 1000 任务的表把 $4,205/月 砍到 $1,453(-65.5%)。含 Python + Node。

GLM-5.2 vs GPT-5.5 成本实算:每天 1 万/10 万/100 万次请求的账单差距(2026)
GLM-5.2($1.4/$4.4 每 M)对比 GPT-5.5($5/$30):blended 单价 $2.40 vs $13.33,差 5.56x。算清每天 1 万/10 万/100 万次请求的账单、50% cache 的影响,两个模型在 ofox 上换一个字符串就能 A/B。
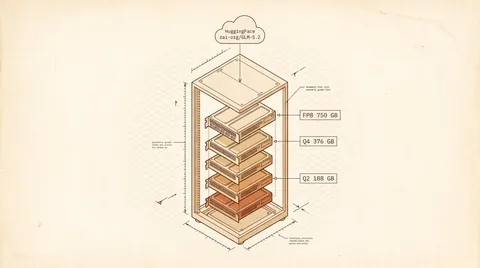
2026 自托管 GLM 5.2 实战:硬件选型、vLLM 部署与成本对照
在 8x H200 上跑 GLM 5.2 FP8、4x H100 跑 Q4 GGUF、Mac Studio 跑 2-bit。753B MIT 权重,1M 上下文,硬件账、云 GPU 时租、Z.ai 月付 $30 三方对照,附 4 个 day-one 推理引擎。

Codex 周限额一天清零:5 种应对方案与按量计费 API 配置(2026)
Codex 周限额一天从 96% 掉到 0%(2026 年 5 月 17 日事件)?5 种解法:储蓄式重置(6 月 12 日上线)、邀请返利、API 直连、预付封顶、降配。一行 wire_api='responses' 搞定。

Codex 周限额耗尽怎么办:7 种修复方案、限额机制和替代 API(2026)
$20 Plus 或 $100 Pro 的 Codex 周限额被打空?本文给出 7 种解法:6 月 11 日上线的免费重置、/status 诊断、单次会话 $0.40-$2.40 的按量 API 路径,以及比 OpenAI 直连便宜 15% 的 ofox 选项。

ofox 上配置 DeepSeek V3.2 提示词缓存:10 分钟接入,账单直降 80%(2026)
DeepSeek V3.2 缓存读 $0.06/M、未命中 $0.29/M(便宜 4.8 倍),输出 $0.43/M,128K 上下文。在 ofox 上 10 分钟完成接入,靠稳定前缀让团队账单立省 80%。

GLM 5.2 接入教程(2026 最新):API 配置、定价与免费开源权重
GLM 5.2 接入教程:Z.ai API 配置步骤、$10–$80/月定价、6 个常见报错的解决办法,外加 MIT 免费开源权重和 ofox 上现成可用的替代方案,一步步照做即可上手。
企业大模型API接入,4大误区与避坑指南(大厂内部最佳实践)
一家企业的线上服务在 93 分钟里悄悄发出 276 次失败请求,全程没人察觉。模型每月被新版本刷新,但企业 AI 项目挂掉的原因从来不是模型——是账单失控、调用挂掉、合规审不过、客户追责答不上。无论是 5 人小队还是百人工程团队,这 4 个痛点和 6 步落地清单都是同一套底座。

MiniMax M3 对比 Claude Opus 4.8:SWE-Bench 差 10 分但便宜 10 倍,怎么选(2026)
MiniMax M3 在 SWE-Bench Pro 拿到 59%,Claude Opus 4.8 拿到 69.2%。M3 输入 $0.6/M、输出 $2.4/M;Opus 输入 $5/M、输出 $25/M。两边都是 1M 上下文。常规重构按每美元算 M3 赢,硬核多文件 diff 按每次任务算 Opus 赢。本文给你 30 秒决策表 + 一行代码切换方案。