Claude Opus 4.8: Benchmarks, Fast Mode & Key Changes
Claude Opus 4.8 launches May 28, 2026 at 4.7 pricing: 1890 Elo on GDPval-AA, 69.2% SWE-bench Pro, 35% fewer tokens, and new Fast Mode explained.

TL;DR — Anthropic shipped Claude Opus 4.8 on May 28, 2026, at the same $5/$25 price as 4.7. It tops Artificial Analysis’s GDPval-AA real-work leaderboard at 1890 Elo (+121 over GPT-5.5, +137 over 4.7), hits 69.2% on SWE-bench Pro, and does it using ~35% fewer output tokens than 4.7 — so it’s better and cheaper to run. New this release: a Fast Mode (2.5x output speed), mid-conversation system messages, and dynamic workflows in Claude Code. Anthropic also calls it their most honest model yet.
What Anthropic Shipped
Claude Opus 4.8 landed on May 28, 2026, about five weeks after GPT-5.5 (released April 23) reset the top of the leaderboards. The model ID is claude-opus-4-8, it carries the full 1M-token context window by default on the Claude API (200K on Microsoft Foundry), 128K max output tokens, and — importantly for budget planning — the same list price as Opus 4.7: $5 per million input, $25 per million output.
The headline isn’t a price cut or a context bump. It’s that Opus 4.8 is the first model to clearly separate itself from the GPT-5.5 generation on real-world agentic work, while spending fewer tokens to do it.
The GDPval-AA Result
The most interesting number isn’t from Anthropic — it’s from Artificial Analysis, an independent benchmarking group. Their GDPval-AA leaderboard scores models on real economic work tasks (44 occupations across 9 industries from OpenAI’s GDPval dataset), giving each model shell access and web browsing inside an agentic loop via their open-source Stirrup harness, then deriving Elo ratings from blind pairwise comparisons.
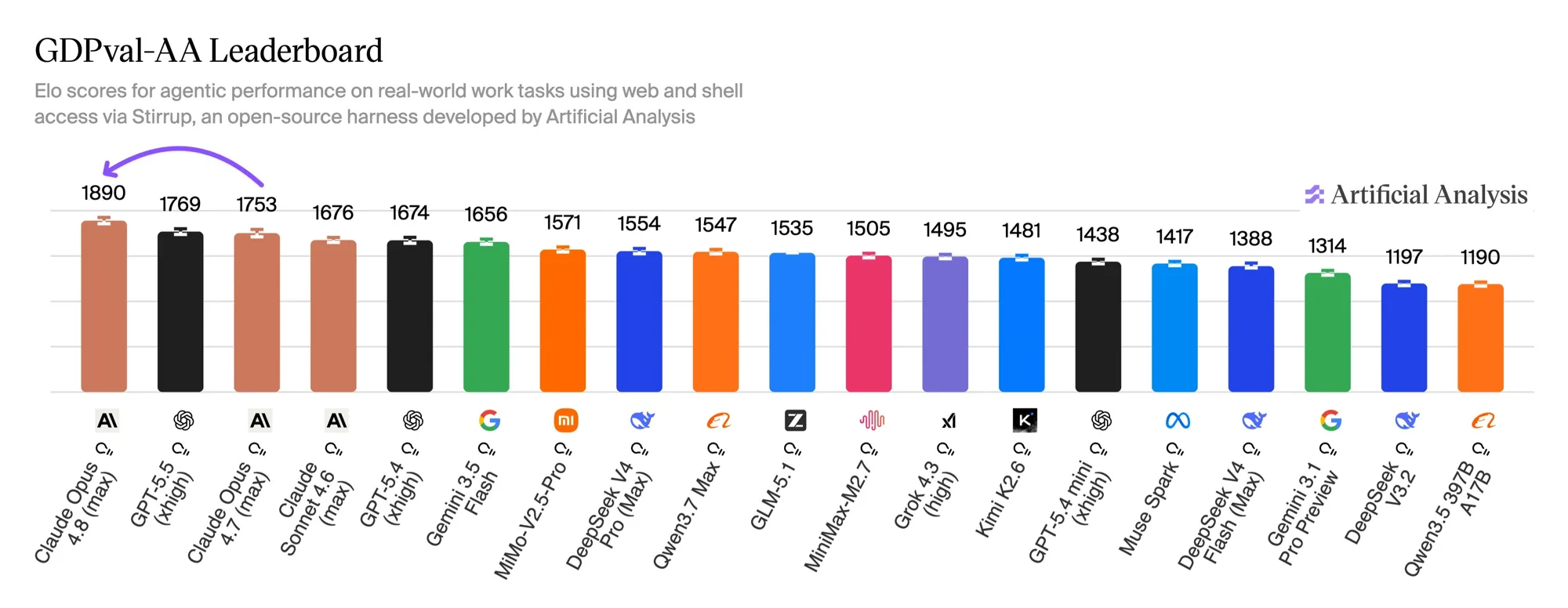
Opus 4.8 (max effort) debuts at 1890 Elo, pulling 121 points clear of GPT-5.5 in second place and +137 over its own predecessor. That margin translates to roughly a 67% implied win rate in head-to-head matchups against GPT-5.5 at its xhigh setting. Three of the top four slots are Claude models.
What makes the result more credible than a raw benchmark percentage: Artificial Analysis notes Opus 4.8 reached this score using 15% fewer turns and 35% fewer output tokens per task than Opus 4.7. The trade-off is that it still takes about 30% more turns than GPT-5.5 to finish the same task — Opus reasons more before acting. For agentic pipelines where output tokens dominate the bill, fewer tokens at a higher win rate is the combination that actually moves your monthly invoice.
Benchmarks vs. the Field
Anthropic’s own numbers line up with the independent result on coding and computer-use, with one exception worth calling out.
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| OSWorld-Verified (computer use) | 83.4% | 82.8% | 78.7% | 76.2% |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| Humanity’s Last Exam (with tools) | 57.9% | — | — | — |
| Finance Agent v2 | 53.9% | — | — | — |
| GDPval-AA (Elo) | 1890 | 1753 | 1769 | — |
SWE-bench Pro uses real open-source repositories, not synthetic tasks, and 69.2% is a 5-point lead over Opus 4.7, the previous class leader. OSWorld-Verified — driving an actual desktop — is where Opus has quietly led for a while.
The exception worth flagging: GPT-5.5 still wins Terminal-Bench 2.1 (78.2% vs 74.6%). If your workload is heavy on raw terminal command sequences, that’s a real data point, not a rounding error. For most agentic coding — multi-file refactors, long autonomous runs, codebase-wide tasks — Opus 4.8 is now the strongest option available.
What’s New Under the Hood
Beyond the scores, four API-level changes matter for anyone building on Opus 4.8.
Fast Mode. A research preview that serves the same Opus 4.8 model at up to 2.5x higher output tokens per second, at premium pricing. Set speed: "fast" in the API or use /fast in Claude Code. This is the part people get wrong: Fast Mode is not a smaller, cheaper model — it’s the full Opus 4.8 running faster, for when latency matters more than per-token cost.
Mid-conversation system messages. You can now insert role: "system" messages after a user turn in the messages array. In a long agentic loop, that lets you append updated instructions without restating the entire system prompt — which preserves prompt-cache hits on earlier turns and cuts input cost. Combined with the lowered 1,024-token cache minimum (down from 4.7), short system prompts that couldn’t be cached before now can.
Adaptive thinking, effort default high. Like 4.7, Opus 4.8 does not accept extended thinking budgets — thinking: {"type": "enabled", "budget_tokens": N} returns a 400. Use thinking: {"type": "adaptive"} and the effort parameter instead. With adaptive thinking on, the model decides per-turn whether it needs to reason, so it wastes fewer thinking tokens on simple lookups. The effort default is now high on every surface, including Claude Code.
from openai import OpenAI
client = OpenAI(base_url="https://api.ofox.ai/v1", api_key="your-ofox-key")
response = client.chat.completions.create(
model="anthropic/claude-opus-4.8",
messages=[{"role": "user", "content": "Refactor this module..."}],
)Better tool triggering and compaction. Anthropic’s listed improvement areas are long-horizon agentic coding (fewer compactions, better recovery after them), reasoning-effort calibration, and tool triggering — specifically, fewer cases of the model skipping a tool call the task required, which was a complaint some users had on 4.7.
Prompting Opus 4.8: What Actually Changed
Anthropic’s prompting guide flags a handful of 4.8-specific behaviors that will bite if you migrate prompts unchanged. Four are worth knowing before you ship.
Effort is now the main dial — and it matters more than on any prior Opus. Start at xhigh for coding and agentic use cases, and keep a minimum of high for anything intelligence-sensitive. max can deliver gains but is prone to overthinking with diminishing returns. The flip side: 4.8 respects low and medium strictly — it scopes work to exactly what you asked, which is great for latency but risks under-thinking on moderately complex tasks. If reasoning looks shallow, raise effort instead of prompting around it. And at high/xhigh, set a large output budget (start at 64K tokens) so the model has room to think and act.
It follows instructions literally. Opus 4.8 won’t silently generalize an instruction from one item to another, and won’t infer requests you didn’t make. That’s a win for structured extraction and pipelines — but if you want something applied broadly, say so explicitly: “Apply this formatting to every section, not just the first.”
It favors reasoning over tool calls. By default 4.8 leans toward thinking rather than calling tools, which is usually better — but if your agent isn’t searching or reading files enough, raising effort to high/xhigh produces substantially more tool use. You can also just tell it when and why to use a given tool.
The code-review recall trap. This one surprises teams. Opus 4.8 is genuinely better at finding bugs (higher precision and recall in Anthropic’s evals), but if your review harness says “only report high-severity issues” or “be conservative,” 4.8 follows that more faithfully than older models — it finds the bugs, then drops the ones below your stated bar. The result looks like lower recall even though bug-finding improved. The fix is to split finding from filtering:
Report every issue you find, including low-severity or uncertain ones.
Do not filter for importance at this stage — a separate step will rank them.
For each finding, include a confidence level and estimated severity.The “Most Honest” Claim
Anthropic is positioning Opus 4.8 as its most honest model to date — fewer confident fabrications, less sycophancy, and clearer refusals. On that last point, the stop_details object on refusal responses (present since 4.7) is now publicly documented, so your application can tell why a request was declined and route the user accordingly instead of treating every refusal the same. For agents running unattended, a model that fabricates less and signals its own uncertainty more clearly is a practical reliability gain, not just a safety talking point.
Launched Alongside: Dynamic Workflows in Claude Code
Opus 4.8 shipped the same day as dynamic workflows, a research preview that lets Claude orchestrate tens to hundreds of parallel subagents in a single session. Claude writes its own orchestration script, fans the work out, verifies results before delivering — including agents whose job is to refute the findings of others — and resumes interrupted jobs where they left off instead of restarting.
The flagship demo: Jarred Sumner used dynamic workflows to port Bun from Zig to Rust — roughly 750,000 lines of code, with a 99.8% test-suite pass rate, in 11 days. The intended use cases are codebase-wide bug hunts, security audits, and large migrations spanning thousands of files.
Two caveats keep this honest. First, it’s plan-gated: dynamic workflows run on Claude Code Max, Team, and Enterprise plans (Enterprise needs admin enablement), not on the raw API. Second, Anthropic explicitly warns that token consumption is substantially higher than a normal session — they recommend starting with scoped tasks. It’s a genuinely new capability for the hardest jobs, not a default-on convenience.
How to Access Opus 4.8 via ofox.ai
The model ID is anthropic/claude-opus-4.8. Through ofox.ai it’s on the same OpenAI-compatible endpoint as every other model — no separate Anthropic account, no separate billing.
For adaptive thinking and effort control, use the Anthropic-native protocol:
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="your-ofox-key",
)
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=4096,
thinking={"type": "adaptive"},
messages=[{"role": "user", "content": "Audit this service for race conditions..."}],
)Going through an aggregator also makes the migration question easier to answer empirically: you can run the same prompts through Opus 4.8, 4.7, and GPT-5.5 on one key and one endpoint, and compare quality and token counts on your workload before committing.
Verdict
Opus 4.8 is the rare upgrade with no asterisk on price: same $5/$25, higher scores across coding and computer-use, top of the independent real-work leaderboard, and fewer output tokens per task. The honest caveats are narrow — GPT-5.5 still wins raw terminal benchmarks, dynamic workflows are plan-gated and token-hungry, and effort now defaults to high so check your latency budget.
For new projects, start on 4.8. For production on 4.7, this is the cleanest migration Anthropic has shipped in a while — the same price and fewer tokens mean the math usually works in your favor. Test a representative sample, watch your tool-calling prompts, and switch.
Related: Claude Opus 4.7 API Review — the predecessor and its tokenizer surprise. GPT-5.5 vs Claude Opus vs Gemini 3.1 — full flagship comparison. Best AI Model for Coding 2026 — where Opus 4.8 fits the coding landscape. Best AI Model for Agents 2026 — picking models for long autonomous runs.


