Best LLMs for Text Extraction & Summarization (2026)
No single LLM wins in 2026. Gemini 2.5 Flash-Lite leads short docs; DeepSeek V4 Flash matches frontier at 1/30th the cost. Pick by doc length, structure, and budget.
TL;DR: No single LLM wins text extraction and summarization in 2026. Gemini 2.5 Flash-Lite has the lowest hallucination rate (3.3%) on Vectara’s short-document summarization benchmark, but loses on 100K+ token documents where Gemini 3.1 Pro and GPT-5.5 dominate. For structured extraction at scale, DeepSeek V4 Flash matches the frontier at one-thirtieth the cost. Pick by document length, structure, and budget — not by leaderboard ranking.
The “best” summarization model in 2026 is whichever one your eval harness picks last Tuesday on documents that look like yours. Frontier models are fungible at this layer; the differences between them are smaller than the differences between two prompts for the same model.
Why summarization benchmarks split into three different winners
Summarization looks like one task. Benchmark results say it’s three.
The first job is short-document faithfulness: take a 500-word news article, summarize it in two sentences, don’t make anything up. The current winner is Google’s Gemini 2.5 Flash-Lite at a 3.3% hallucination rate on Vectara’s HHEM-2.3 leaderboard, narrowly edging GPT-5.4 Nano (3.1% on the easier dataset, but 3.3%+ on the harder one). (Vectara Hallucination Leaderboard)
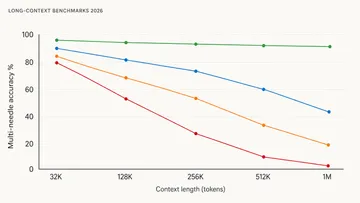
The second job is long-document comprehension: feed in a 200-page contract, ask “what’s the indemnification cap and where is it qualified?” Here, Gemini 3.1 Pro and GPT-5.5 are the only frontier models that don’t degrade past 100K tokens on the HELMET benchmark, with Gemini 3.1 Pro’s 1M context window holding accuracy through positions a Claude Sonnet would silently fail at. (HELMET on HuggingFace)
The third job is structured extraction: pull every dollar amount, every person name, every date from 50K invoices into clean JSON. Hallucination matters less because the schema constrains output. Throughput and per-token cost dominate. DeepSeek V4 Flash and GPT-5.4 Nano win this category on cost-quality, often 30x cheaper than Opus-class models with single-digit accuracy gaps.
A model that wins one of these three can lose the other two. The leaderboard you read on Twitter probably measures only one.
The four benchmarks worth knowing in 2026
1. Vectara HHEM-2.3 (short-document faithfulness)
The Vectara Hallucination Leaderboard (last updated May 11, 2026) is the de facto standard for “does the summary stay faithful to the source.” It uses HHEM-2.3, a commercial evaluator, to score whether each sentence in a model’s summary is supported by the source document. The original benchmark uses 1,006 short documents; a newer, harder benchmark released in 2026 spans 7,700 articles across law, medicine, finance, education, and technology.
Top 10 on the original dataset (May 2026):
| Rank | Model | Hallucination Rate | Answer Rate |
|---|---|---|---|
| 1 | Ant Group finix_s1_32b | 1.8% | 99.5% |
| 2 | OpenAI gpt-5.4-nano-2026-03-17 | 3.1% | 100.0% |
| 3 | Google gemini-2.5-flash-lite | 3.3% | 99.5% |
| 4 | Microsoft Phi-4 | 3.7% | 80.7% |
| 5 | Meta Llama-3.3-70B-Instruct-Turbo | 4.1% | 99.5% |
| 6 | Google gemma-3-12b-it | 4.4% | 97.4% |
| 7 | Mistral mistral-large-2411 | 4.5% | 99.9% |
| 8 | Qwen qwen3-8b | 4.8% | 99.9% |
| 9 | Amazon nova-pro-v1 | 5.1% | 99.3% |
| 10 | DeepSeek V3.2-Exp | 5.3% | 96.6% |
Notice what’s missing from the top 10: every frontier reasoning model. Claude Opus historically sits around 10% on this benchmark. GPT-5.5 with thinking mode enabled scores in the 8-12% range on the harder dataset. More reasoning means more inference means more hallucination — for short-summary faithfulness, smaller and dumber is often better.
The lesson: if you’re summarizing news, legal abstracts, or anything where “made up a fact” is a fireable offense, route to a small, well-aligned model — not your flagship.
2. HELMET (long-context downstream tasks)
HELMET (“How to Evaluate Long-context Models Effectively and Thoroughly”) was Princeton’s 2024 reaction to the fact that needle-in-a-haystack benchmarks were too easy and didn’t reflect real summarization or extraction workloads. It tests 7 categories at controllable lengths up to 128K tokens, including summarization, retrieval-augmented generation, citation extraction, and in-context learning. (HELMET on GitHub)
The 2026 finding: only Gemini 3.1 Pro, GPT-5.5, and Claude Opus 4.7 maintain quality past 64K tokens on summarization-style tasks. Everything else — including smaller variants of those same families — degrades noticeably past 32K. If your documents are routinely above 100 pages, this narrows your options dramatically.
3. RULER / ONERULER (retrieval and extraction at length)
RULER tests how well a model can find and reason about specific facts buried in long context. ONERULER extends it to 26 languages. (RULER paper)
These benchmarks matter for extraction tasks: “find the indemnity clause in this 800-page contract” is structurally a RULER task with one needle. “Pull every CVE referenced in these 200 security advisories” is a multi-needle RULER variant. Frontier models with 1M context windows (Gemini 3.1 Pro, GPT-5.5) pass these benchmarks at lengths where 128K-context Claude variants start missing.
4. LongBench Pro (realistic bilingual long-context)
LongBench Pro is human-verified, includes Chinese and English documents, and avoids the “synthetic needle” pattern that lets models cheat with attention tricks. It’s the closest thing to a real enterprise summarization benchmark, and unsurprisingly the leaders are the same three: Gemini 3.1 Pro, GPT-5.5, Claude Opus 4.7. Their orderings depend heavily on document genre (legal vs. scientific vs. narrative). (LongBench Pro paper)
Picking a model by job (the only chart that matters)
| Your Job | Top Pick (Quality) | Top Pick (Cost-Quality) | What to Avoid |
|---|---|---|---|
| Short article → 2-sentence summary | Gemini 2.5 Flash-Lite | Phi-4, Llama 3.3 70B | Opus-class reasoning models |
| Long contract → executive summary | Gemini 3.1 Pro | GPT-5.5 (cheaper than Opus 4.7) | Anything ≤128K context |
| 800-page doc → find specific clause | Gemini 3.1 Pro (1M ctx) | GPT-5.5 | Claude Sonnet 4.6 past 100K |
| Invoice → JSON extraction (high volume) | GPT-5.4 Mini | DeepSeek V4 Flash | Flagships (3-30x waste) |
| Multilingual abstract (legal, medical) | Claude Opus 4.7 | Qwen3-Plus | Models without tested target language |
| Compliance-grade financial summary | Opus 4.7 + Flash-Lite checker | Sonnet 4.6 + Flash-Lite checker | Single-model pipelines |
The pattern is consistent: flagship reasoning models lose to smaller models on faithfulness-critical short tasks, and win on long-context, multilingual, or nuanced summaries. Cost ratios are typically 10-30x between the budget pick and the quality pick — large enough that running a two-stage pipeline (cheap model summarizes, expensive model checks) often beats single-model approaches on both quality and cost.
The pricing reality check
For a 2K-token document summarized into 200 tokens (a normal news-article job), per-document cost in May 2026:
| Model | Input $/MTok | Output $/MTok | Cost per 1K docs |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | $0.10 | $0.40 | ≈$0.28 |
| DeepSeek V4 Flash | $0.14 | $0.28 | ≈$0.34 |
| GPT-5.4 Mini | $0.25 | $2.00 | ≈$0.90 |
| GPT-5.5 | $5.00 | $30.00 | ≈$16.00 |
| Claude Opus 4.7 | $5.00 | $25.00 | ≈$15.00 |
At a million documents per month, that’s the difference between $280 and $16,000 — same job, same general accuracy band on short-summary work. The price of “flagship by default” is real.
If you’re running these workloads through multiple providers, the operational pain compounds: separate keys, separate billing, separate retry logic. A single OpenAI-compatible gateway — see why an LLM API gateway matters — turns the model choice into a parameter swap rather than a deploy. ofox.ai routes all the models in the table above through one endpoint with aggregated access, so you can A/B Gemini Flash-Lite against Claude Opus on production traffic without re-architecting.
How to evaluate on your own corpus (the 30-minute version)
Public benchmarks lie when applied to your data. A 30-minute custom eval beats every leaderboard:
# 1. Sample 50 documents from your real corpus (not your test set)
# 2. For each candidate model, run the same summarization prompt
# 3. Score with HHEM-2.3 (open-source, runs locally) for hallucination
# 4. Score with ROUGE-L or BERTScore for coverage
# 5. Have one human reviewer rate readability on 30 outputsThe four signals you actually care about: factual accuracy (did it make anything up?), coverage (did it skip important content?), cost (per-document at your volume), and latency (p95 to first token if user-facing). Anything else is noise.
For extraction specifically, the right eval is schema-level: parse the output, compute F1 per field against ground truth. If you can’t parse it, that’s an “extraction failure” — count it against the model, not your downstream pipeline.
What about reasoning-heavy summarization?
If your “summarization” job actually requires reasoning — synthesizing across 10 sources, resolving contradictions, judging which claim is more credible — none of the faithfulness benchmarks above apply. You want a reasoning-tier model, and the cost ratios flip: spending $15 instead of $0.30 on a critical research summary is trivially worth it.
The wrong move is using a reasoning model when the job is just “compress this article to 200 words faithfully.” That’s where Vectara’s leaderboard humbles flagships.
The bigger picture: routing beats picking
A team running serious summarization volume in 2026 doesn’t pick one model. They route:
- Default route: Gemini 3.1 Flash-Lite or DeepSeek V4 Flash for high-volume short summaries
- Long-document route: Gemini 3.1 Pro for anything past 32K tokens
- Compliance route: Two-stage with a flagship model summarizing and a Flash-Lite checking faithfulness
- Multilingual route: Claude Opus 4.7 or Qwen3-Plus depending on language
- Reasoning-required route: GPT-5.5 or Claude Opus 4.7 with thinking enabled
This is the same pattern that emerged in coding workflows — see the hybrid routing pattern — and for the same reason: model families have specialized faster than any single model can keep up.
For broader model-by-task picking beyond summarization, the LLM API Selection Decision Matrix covers the cross-vendor view. The 2026 LLM Leaderboard ranks models on coding and reasoning axes that complement the summarization picture here. And for the head-to-head between the three flagships referenced throughout this article, see Claude 4 vs GPT-5 vs Gemini 3.
The biggest win in summarization workloads isn’t picking the right flagship — it’s noticing that 80% of your traffic doesn’t need one. Route the easy work to a $0.30/1K-docs model and reserve the $15/1K spend for the cases that actually earn it.
Sources
- Vectara Hallucination Leaderboard (HHEM-2.3, May 2026)
- Vectara: Next Generation Hallucination Leaderboard
- HELMET: Holistically Evaluating Long-context Language Models
- RULER: What’s the Real Context Size of Your Long-Context Language Models?
- LongBench Pro paper
- Introducing Claude Opus 4.7 — Anthropic
- Introducing GPT-5.5 — OpenAI
- Gemini 3.1 Pro Model Card — Google DeepMind
- DeepSeek V4 Pro vs Flash benchmarks