Claude Opus 4.7 正式发布:编程提升 13%,ofox.ai 第一时间上线支持
Anthropic 于 2026 年 4 月 16 日发布 Claude Opus 4.7,SWE-bench Pro 64.3%、CursorBench 70%、视觉分辨率提升 3 倍。ofox.ai 同步上线,国内开发者可直接通过 OpenAI 兼容接口调用,无需翻墙。

Anthropic 昨天(4 月 16 日)发布了 Claude Opus 4.7,这是目前 GA(正式可用)版本中能力最强的 Opus 模型。ofox.ai 同步上线,国内开发者现在可以直接调用。
核心数据
这次升级的数字比较实在:
| 指标 | Opus 4.6 | Opus 4.7 | 变化 |
|---|---|---|---|
| CursorBench | 58% | 70% | +12 pts |
| SWE-bench Pro | 53.4% | 64.3% | +10.9 pts |
| 生产任务解决量(Rakuten) | 基准 | 3x | 3 倍 |
| 视觉分辨率 | ~1.2 MP | 3.75 MP | 3x+ |
| XBOW 视觉精度 | 54.5% | 98.5% | 大幅提升 |
| BigLaw Bench(Harvey) | — | 90.9% | — |
| 定价(输入/输出) | $5/$25 | $5/$25 | 不变 |
同样的价格,编程能力跳了一个档次。
基准测试全景
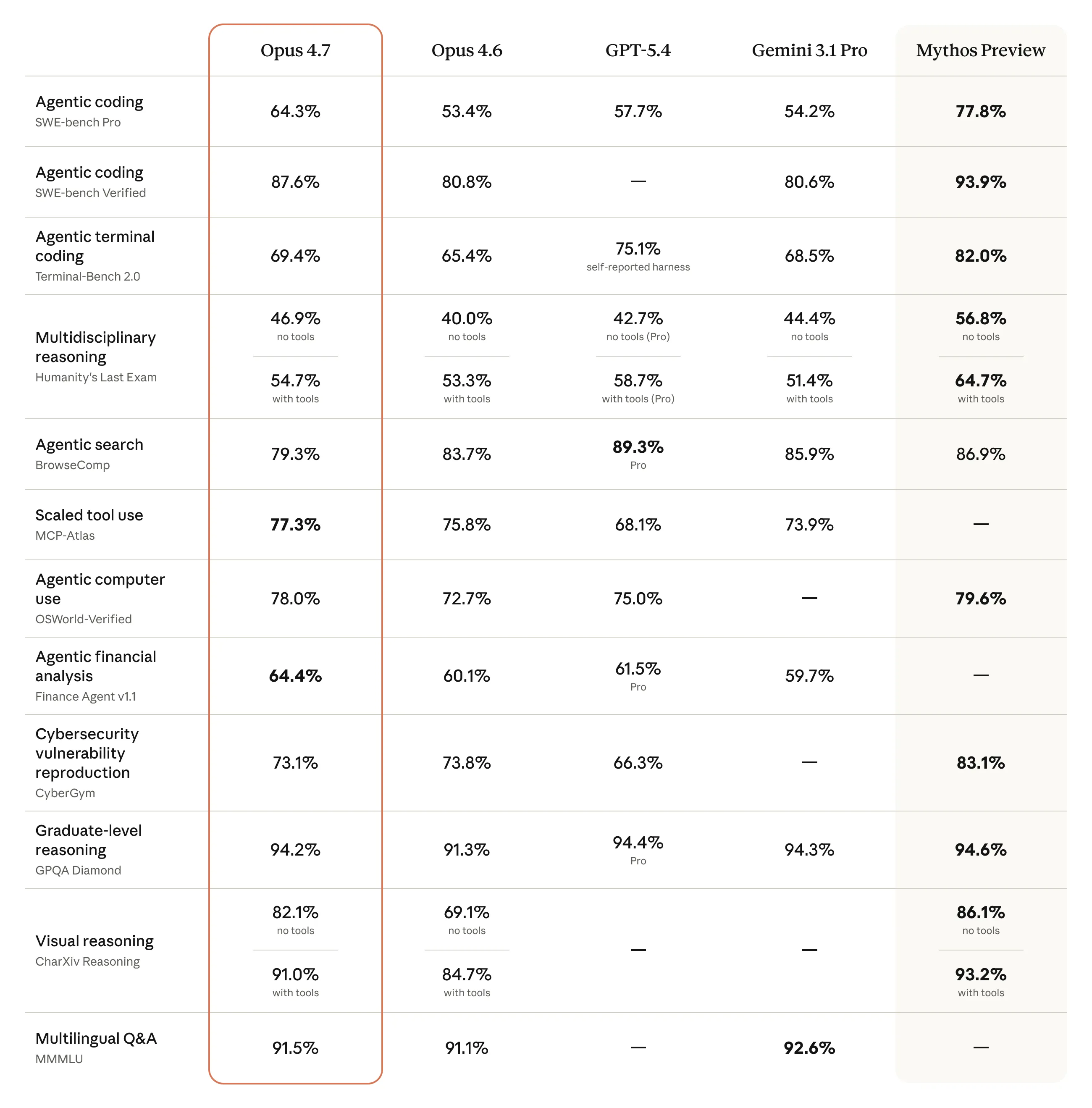
Anthropic 发布了跨多个维度的对比数据,涵盖 Office Tasks、Vision、Document Reasoning、Long-Context Reasoning、Biology、Long-Term Coherence 和 Coding 七个类别,与 Opus 4.6、Sonnet 4.6、GPT-5.4、Gemini 3.1 Pro 全面对比。
编程能力:真实提升
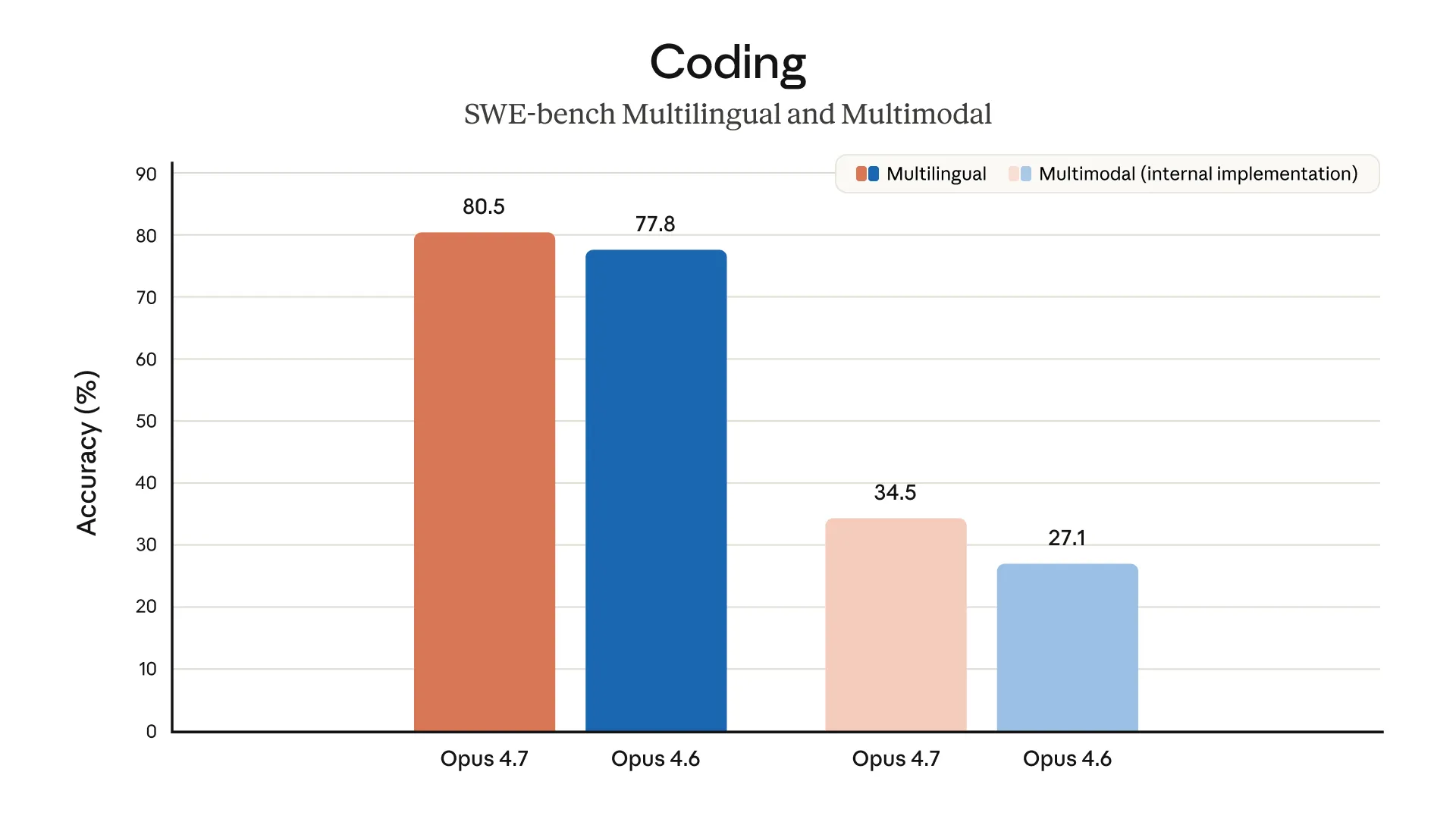
SWE-bench Pro 64.3% 是目前 GA 模型里最高的,超过 GPT-5.4(57.7%)和 Gemini 3.1 Pro(54.2%)。
来自一线用户的反馈更直接:
- Cursor:CursorBench 70% vs Opus 4.6 的 58%
- Rakuten:生产任务解决量是 4.6 的 3 倍
- Vercel:一次性编程任务更正确、更完整
- Warp:通过了之前 Claude 模型失败的 Terminal Bench 任务
- CodeRabbit:复杂 PR 中难以发现的 bug 召回率提升超 10%
- Cognition:自主从零构建了完整的 Rust 文字转语音引擎
Notion 的数据尤其值得关注:同等质量下,Opus 4.7 比 4.6 少用 14% 的 token,工具调用错误减少三分之一。
视觉能力:3 倍分辨率
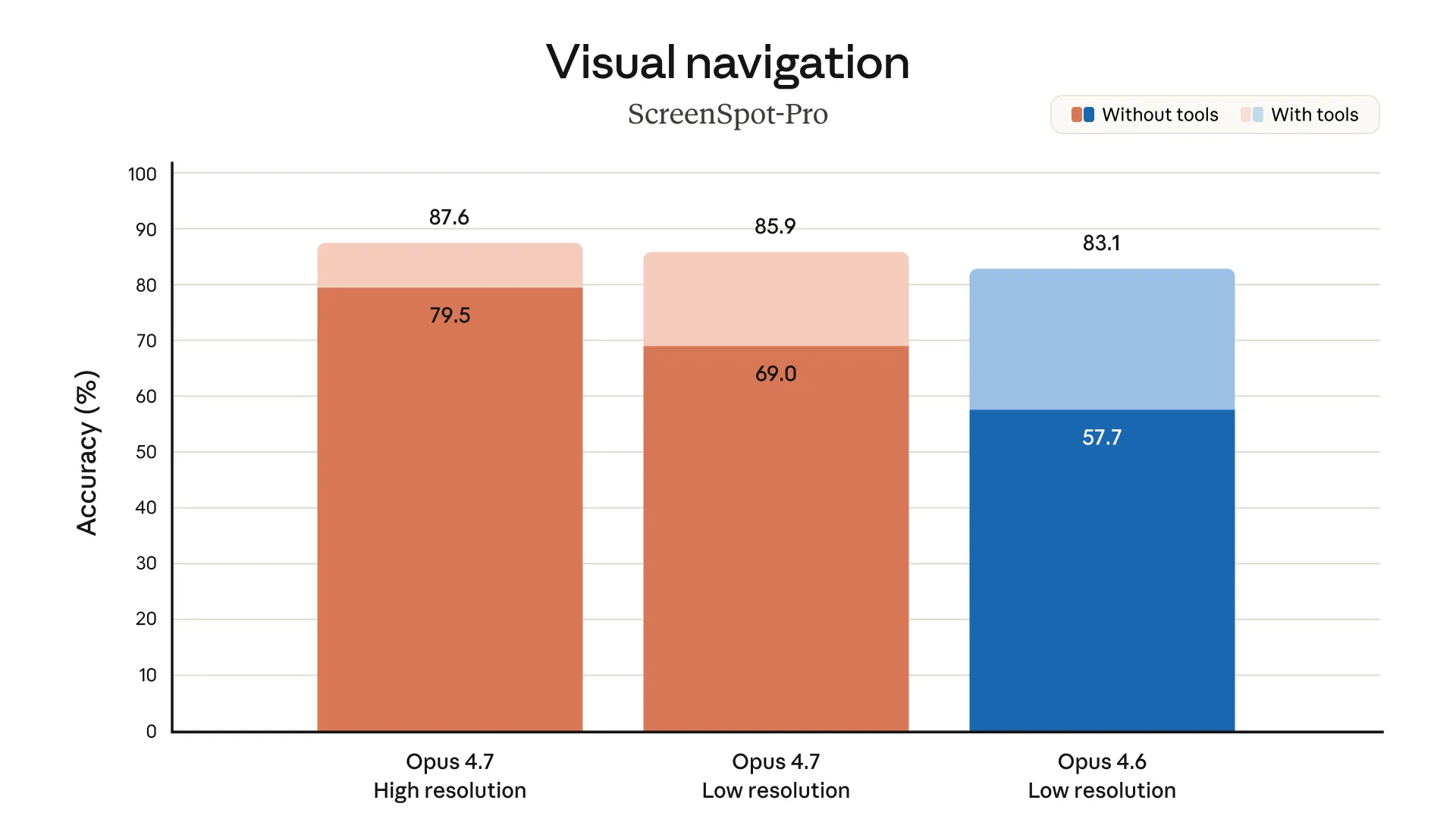
支持最长边 2576 像素(约 3.75 MP),是之前 Claude 模型的 3 倍以上。化学结构式、技术图纸、密集截图这类之前容易出错的内容,现在处理精度大幅提升。
XBOW 视觉精度基准从 54.5% 跳到 98.5%——这个差距不是小幅优化,是质变。Solve Intelligence 在生命科学专利工作流中测试,多模态理解有”重大改善”。
效率提升:更少 token,更好结果
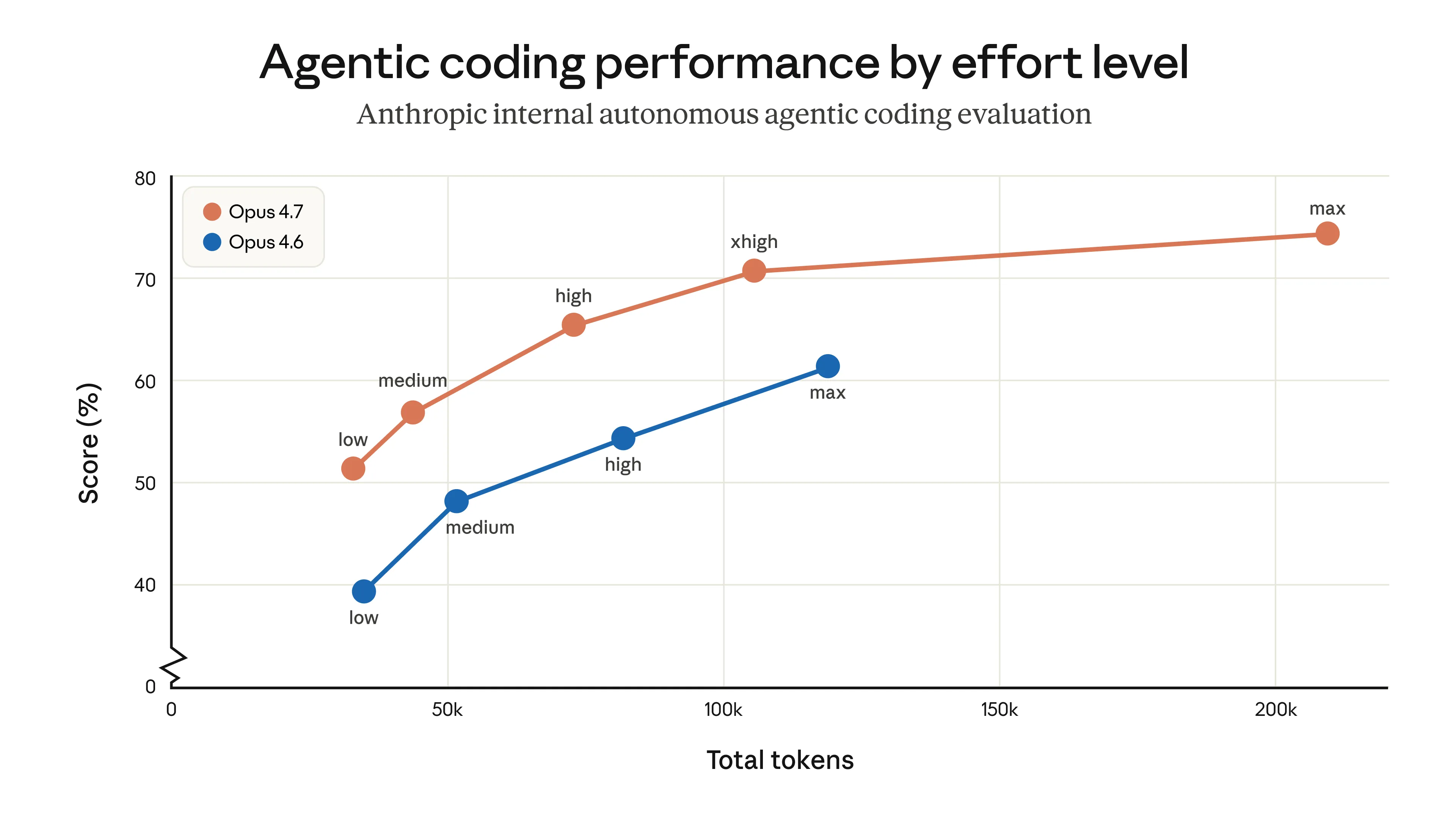
这张图展示了不同推理档位下 token 消耗与任务得分的关系。关键结论:Opus 4.7 在相同 token 预算下得分更高,或者用更少 token 达到同等效果。
Hex 的测试结论是:低档位的 Opus 4.7 大约等于中档位的 Opus 4.6。这意味着你可以降低推理强度、节省成本,同时保持原来的输出质量。
新功能
xhigh 推理档位:在 high 和 max 之间新增一档,推理深度和延迟的控制更精细。
Task Budgets(公测):长任务的 token 预算控制,适合多步骤 Agent 场景,避免成本失控。
Claude Code /ultrareview:新增代码审查命令,专门标记 bug 和设计问题。Pro/Max 用户每月 3 次免费。
Auto Mode 扩展:Max 用户现在也可以使用自动模式,让模型自主决策长任务的执行方式。
指令遵循的变化
Anthropic 特别提到这次指令遵循有”实质性提升”——模型会更字面地执行指令,而不是自行解读。这对有复杂 system prompt 的生产应用来说是好事,但也意味着如果你的 prompt 之前写得比较模糊,可能需要重新调整。
Ramp 的反馈印证了这一点:在 Agent 团队工作流中,角色保真度、指令遵循和协调能力都有提升。
迁移注意事项
Opus 4.7 用了新的 tokenizer,同样的输入内容会映射到更多 token(大约 1.0–1.35 倍)。定价没变,但实际 token 消耗会略有增加,尤其是推理密集的任务。迁移前建议先跑一下成本测算。
在 ofox.ai 上调用
ofox.ai 已同步上线 claude-opus-4-7,模型 ID 和 Anthropic 官方一致,国内节点直连,无需额外网络配置。
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="YOUR_OFOX_API_KEY",
)
message = client.messages.create(
model="anthropic/claude-opus-4.7",
max_tokens=1024,
messages=[
{"role": "user", "content": "帮我审查这段代码"}
],
)
print(message.content[0].text)也支持 OpenAI SDK(OpenAI 兼容协议):
from openai import OpenAI
client = OpenAI(
base_url="https://api.ofox.ai/v1",
api_key="YOUR_OFOX_API_KEY",
)
response = client.chat.completions.create(
model="anthropic/claude-opus-4.7",
messages=[{"role": "user", "content": "帮我审查这段代码"}],
)
print(response.choices[0].message.content)如果你在用 Claude Code,切换模型只需要在 ccswitch 里增加一条配置,把 model 改成 anthropic/claude-opus-4.7,其他不用动。
值不值得升级
如果你现在在用 Opus 4.6 做编程任务,答案是值得。价格一样,编程能力有实质提升,视觉任务改善明显,而且 token 效率更高意味着实际成本可能反而更低。
如果你在用 Sonnet 4.6 做日常任务,不需要特意升级——Sonnet 的性价比依然更高,Opus 适合复杂任务。
模型 ID:anthropic/claude-opus-4.7,接入地址:https://api.ofox.ai/anthropic(Anthropic 协议)或 https://api.ofox.ai/v1(OpenAI 兼容协议),注册获取 API Key。
关于 Opus 4.7 的功能细节、xhigh 模式用法和完整接入示例,参见 Claude Opus 4.7 完全指南。


