Claude Sonnet 4.6 还是 Opus 4.7:跨代选型,国内开发者怎么花钱最划算
Sonnet 4.6 是当前最新的 Sonnet(2026 年 2 月),Opus 4.7 是当前最新的 Opus(4 月)。两代旗舰怎么选?本文给出价格、性能、视觉、速度的实测对照,以及不同任务场景下的具体建议。

TL;DR — 80% 的日常编程任务用 Sonnet 4.6 就够,账单打六折、速度快一倍。Opus 4.7 真正划算的场景是涉及视觉(截图、UI、图表)、需要 xhigh 档位的多文件重构、或者单次输出超过 64K token 的长生成。涉及图像识别的工作流,Opus 4.7 的分辨率优势会拉开很大差距。
2026 年 2 月 17 日 Sonnet 4.6 上线,4 月 16 日 Opus 4.7 跟进。两个都是各自系列里的最新版。Anthropic 把 Opus 和 Sonnet 当两条独立线推进,版本号不共用,目前没有也大概率不会有 Sonnet 4.7。下一代是 Sonnet 4.8,按惯例 5 月底之前会出。
跨代选型这个问题最近被问了几次,写一篇放这里。
一张表说清楚差距
| Sonnet 4.6 | Opus 4.7 | |
|---|---|---|
| 发布时间 | 2026-02-17 | 2026-04-16 |
| 输入价格 | $3 / 1M token | $5 / 1M token |
| 输出价格 | $15 / 1M token | $25 / 1M token |
| 上下文窗口 | 1M token | 1M token |
| 单次最大输出 | 64K token | 128K token |
| 响应速度 | 40-60 tokens/秒 | 20-30 tokens/秒 |
| SWE-bench Verified | 79.2% | 87.6% |
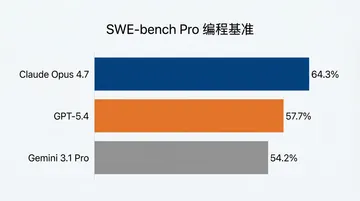
| SWE-bench Pro | ~58% | 64.3% |
| 视觉分辨率 | 1.15 MP(1568px 长边) | 3.75 MP(2576px 长边) |
| XBOW 视觉敏锐度 | ~54.5% | 98.5% |
| Effort 档位 | low / medium / high / max | low / medium / high / xhigh / max |
| Function Calling | ✅ | ✅ |
几个数字先看一眼。
价格差 40%。每输出一百万 token 多花 $10,看起来不多,跑量大的工作流一个月能差出好几百美金。
SWE-bench Verified 差 8 个点。这个差距在跑代码任务时是有体感的,比同代 Opus 4.6 vs Sonnet 4.6 那 1.2 个点的差距明显大一档。
XBOW 视觉敏锐度基准上 Sonnet 4.6 是约 54.5%,Opus 4.7 跳到 98.5%。这不是渐进改善,是质变。涉及截图、图表、UI 的工作流,Sonnet 4.6 经常”看到没看清”,Opus 4.7 基本能看清。
编程任务:还是 Sonnet 4.6 性价比赢
跨代之后 Opus 4.7 在编程上的优势确实变大了,但 80% 的开发场景里,Sonnet 4.6 仍然是更聪明的选择。
日常补全、调 bug、小范围重构这类任务,两个模型的输出基本看不出差距。Sonnet 偶尔在变量命名或注释风格上不如 Opus 讲究,但属于”专门挑刺才能发现”的级别。
差距拉开主要是在这几种情况:
跨文件大规模重构,比如把一个 monolith 拆成微服务,涉及 20+ 个文件联动修改的时候。Opus 4.7 对全局上下文的把控比 Sonnet 4.6 稳一档,开 xhigh 档位之后尤其明显。Sonnet 在这种任务里偶尔会”忘”前面定义的某个 interface,Opus 不太会。
架构级设计也是。让模型从零设计一个分布式系统的技术方案,Opus 4.7 考虑的边界条件更全面。Sonnet 有时候会漏掉一些 edge case,多半发生在长链推理的中间步骤。
超长代码库理解是第三种情况。上下文超过 100K token 时,Opus 4.7 对细节的记忆和引用准确度明显更高。Sonnet 在这个量级偶尔会”丢”东西,不是每次都丢,但频率够让你注意到。
补全代码、写业务逻辑、做代码审查,直接选 Sonnet 4.6。一天调几十次 API,速度快一倍这件事在体感上比任何基准分数都重要。
关于这两个模型在 OpenClaw 类编程工具里的具体配置和搭配玩法,可以参考《Claude Code 国内使用 + Opus 4.6 编程体验》。
视觉任务:Opus 4.7 直接断层领先
这是跨代后 Opus 4.7 拉开 Sonnet 4.6 最多的维度。
Sonnet 4.6 的视觉分辨率是 1.15 MP(长边 1568px),XBOW 视觉敏锐度约 54.5%。Opus 4.7 是 3.75 MP(长边 2576px),XBOW 跳到 98.5%。三倍多分辨率,准确率几乎翻倍。
具体到任务上。
截图识别和 UI 自动化(computer use)类的工作,Sonnet 4.6 经常出现”我看到这个按钮了,但点不准”的情况,Opus 4.7 基本解决了这个问题。如果 Agent 流程需要操作浏览器或桌面 UI,这个差距直接决定任务成功率。
图表和数据可视化理解上,给模型一张包含 5 条曲线的折线图、让它提取每条曲线的关键数据点,Sonnet 4.6 会漏数据或者把相邻曲线搞混,Opus 4.7 几乎不出这种错。
手写文档和表格 OCR 也是 Opus 4.7 更稳。模糊扫描件、手写表格这类边角案例,Sonnet 4.6 在小字部分经常猜错,Opus 4.7 的识别完整度高一截。
任何涉及”看图办事”的生产场景,直接选 Opus 4.7。这一档差距不是省那 40% 成本能弥补的。
xhigh 思考档位:Opus 4.7 独有
Anthropic 的 effort 参数完整档位是 low / medium / high / xhigh / max。xhigh 是 Opus 4.7 这一代新加的,位于 high 和 max 之间——比 high 消耗更多 token 做内部推理,但比 max 更克制。Anthropic 官方推荐把 xhigh 作为 Opus 4.7 跑编程和 Agent 任务的起点档位。
适合 xhigh 的场景大致是:多文件代码重构、需要模型在 10+ 个文件之间保持上下文一致的时候;长链逻辑推理,超过 5 步连续思考才能得出结论的问题;高精度视觉分析,比如要从一张复杂截图里提取多个细节。
max 档两个模型都有(Sonnet 4.6 和 Opus 4.7 都支持),但 Anthropic 明确说”max 在多数工作负载上只比 xhigh / high 多挤出几个百分点的质量,成本却会显著上升,保留给真正的前沿难题”。日常任务别开 max,关键任务才值得。
Sonnet 4.6 不支持 xhigh,可用的最高档是 max。大多数任务上 high / medium 够用,但碰到 Opus 4.7 推荐用 xhigh 的硬骨头任务时,Sonnet 4.6 即便开到 max 也顶不上 Opus 4.7 的 xhigh。
价格和速度:算一笔实际账
假设你每天用量 100K 输入 + 50K 输出(中等强度开发辅助),一个月 22 个工作日:
- Sonnet 4.6:(0.1 × $3 + 0.05 × $15) × 22 = $23.1/月
- Opus 4.7:(0.1 × $5 + 0.05 × $25) × 22 = $38.5/月
一个月差 $15,一年差 $180。5 人小团队就是 $900/年。
但 Opus 4.7 还有个不太显眼的成本细节:换了新 tokenizer,同样的输入会产生 1.0-1.35 倍的 token 数。代码密集型任务影响明显,纯文本影响较小。所以实际账单可能比上面算的还高 10-20%(如果你的工作以代码为主)。
速度上 Sonnet 4.6 大约是 Opus 4.7 的两倍,40-60 tokens/秒对 20-30 tokens/秒。生成一段 500 token 的代码,Sonnet 大约 8-12 秒,Opus 大约 15-25 秒。一天调几十次,累积差距很可观。
实战里更常见的玩法是混搭。日常补全和小修改用 Sonnet 4.6,碰到复杂重构或视觉任务再切 Opus 4.7。OpenClaw 类工具里可以配多个模型按 task 类型路由,关于这个搭配,《Claude Opus 4.6 vs Sonnet 4.6 怎么选》里讲的混合策略对 4.7 同样适用。
Prompt Caching:两个模型都吃这碗饭
Anthropic 的 Prompt Caching 对 Sonnet 4.6 和 Opus 4.7 都有效。开启后重复的系统提示词部分只收原价的 10%(Sonnet 是 $0.30/M token,Opus 是 $0.50/M token)。
工作流里有固定的长 system prompt 或 few-shot 示例时,开缓存能让账单再降一截。两个模型的缓存策略和开关方式都一样,具体配置参考 Anthropic Prompt Caching 文档。
跑 Agent 工作流的时候,缓存命中率往往比模型档次的选择更影响最终账单。
不同场景的具体选择
不想看分析的,直接看这部分。
日常编程辅助(补全、调试、代码审查、写业务逻辑)选 Sonnet 4.6。性能差距日常感受不到,速度快一倍,账单打六折。
大规模重构和架构设计这种硬骨头任务选 Opus 4.7,配 xhigh 档位。20+ 文件联动、长链推理的中间步骤稳定性差距明显。
视觉相关任务——截图识别、UI 自动化、图表理解、computer use——直接选 Opus 4.7。XBOW 视觉敏锐度从 54.5% 到 98.5% 的差距,价格上省下的钱弥补不了。
长文档分析看长度。10 万 token 以内 Sonnet 4.6 够用,超过 10 万切 Opus 4.7。
单次需要输出 65K 以上 token 时只能选 Opus 4.7,因为 Sonnet 4.6 的单次输出硬上限是 64K。
Agent 工作流推荐混搭。Planner / Reasoner 用 Opus 4.7 保证多步推理稳,Executor / Tool Caller 用 Sonnet 4.6 把速度和成本压下来。如果有视觉步骤,那一步固定用 Opus 4.7。
对 token 成本极度敏感的高频调用场景,Sonnet 4.6 加 Prompt Caching 是基本盘。极端情况下还可以下沉到 Haiku 4.5($1/$5),但能力档差会比较明显,需要先用真实任务测一下能不能扛。
国内怎么调
两个模型都通过 OfoxAI 直接调用。完整模型名:
- Sonnet 4.6:
anthropic/claude-sonnet-4.6 - Opus 4.7:
anthropic/claude-opus-4.7
Base URL 二选一:
- OpenAI 兼容:
https://api.ofox.ai/v1 - Anthropic 原生:
https://api.ofox.ai/anthropic
OpenAI 兼容协议下用 OpenAI SDK 直接换 base_url 和 API Key 就能切:
from openai import OpenAI
client = OpenAI(
base_url="https://api.ofox.ai/v1",
api_key="<your-ofox-api-key>",
)
resp = client.chat.completions.create(
model="anthropic/claude-sonnet-4.6",
messages=[{"role": "user", "content": "解释一下 prompt caching 的原理"}],
)需要原生 Anthropic 协议(用 anthropic SDK 或者要传 cache_control 这类 Anthropic 特有字段)的话,把 base_url 改成 https://api.ofox.ai/anthropic,SDK 用 Anthropic 官方的就行,API Key 换成 ofox 的。
充值支持微信和支付宝,不用海外信用卡。常见报错(429 限流、401 鉴权、529 容量超限等)的排查方式,可以参考《Claude API 报错汇总》和《模型特定报错排查手册》。
一句话总结
没有视觉需求、不做大规模重构,Sonnet 4.6 就是当前的最优解。涉及图像识别、有 xhigh 档位需求、或者单次输出超 64K 的时候再上 Opus 4.7。大型 Agent 工作流最划算的玩法还是混搭路由。
Sonnet 4.8 大概率会在 5 月底前发布。按 Anthropic 的节奏,下次值得重新评估选型大约就在那个时候。
数据来源:
- Introducing Claude Sonnet 4.6(Anthropic 官方)
- Introducing Claude Opus 4.7(Anthropic 官方)
- Anthropic Models Overview
- OfoxAI 模型列表