Claude Opus 4.6 vs Sonnet 4.6 怎么选:定价、性能、场景全拆解
Claude Opus 4.6 和 Sonnet 4.6 到底该用哪个?本文从定价、编程能力、推理深度、响应速度、上下文窗口五个维度做实际对比,给出不同场景下的选型建议,帮你在性能和成本之间找到最优解。

Claude Opus 4.6 和 Sonnet 4.6 都是 2026 年 2 月发布的,间隔只有 12 天。一个贵,一个快,选哪个?
这个问题我被问了不下二十次。答案不复杂,但得看你具体干什么。
先看数字:一张表说清楚
| Opus 4.6 | Sonnet 4.6 | Haiku 4.5 | |
|---|---|---|---|
| 输入价格 | $5 / 百万 token | $3 / 百万 token | $1 / 百万 token |
| 输出价格 | $25 / 百万 token | $15 / 百万 token | $5 / 百万 token |
| 上下文窗口 | 1M token | 1M token | 200K token |
| 最大输出 | 128K token | 64K token | 64K token |
| 响应速度 | 20-30 tokens/秒 | 40-60 tokens/秒 | 80+ tokens/秒 |
| SWE-bench | 80.8% | 79.6% | — |
| 视觉理解 | ✅ | ✅ | ✅ |
| Function Calling | ✅ | ✅ | ✅ |
| 扩展思考 | ✅ | ✅ | ✅ |
几个数字先看一眼:
Sonnet 的输入价格是 Opus 的 60%,输出价格也是 60%。同样的任务,换 Sonnet 跑,账单直接打六折。
SWE-bench Verified(业界最常用的编程能力基准测试)上,两者差距只有 1.2 个百分点。这个差距在日常使用中基本感知不到。
速度差异倒是很明显——Sonnet 的吞吐量大约是 Opus 的两倍。写代码等响应的时候,这个差距体感很强。
编程能力:Sonnet 真的够用吗
这是被问得最多的问题,直接说结论:对 80% 以上的开发场景,Sonnet 4.6 完全够用。
我自己的体感是这样的——日常写业务逻辑、调 bug、做代码审查,两个模型的输出质量几乎分不出来。Sonnet 偶尔会在变量命名上不如 Opus 讲究,但这种差异属于”挑刺才能发现”的级别。
Opus 真正拉开差距的场景是:
- 跨文件的大规模重构。比如你要把一个 monolith 拆成微服务,涉及 20+ 个文件的联动修改,Opus 对全局上下文的把控明显更稳。
- 复杂的架构设计。让模型从零设计一个分布式系统的技术方案,Opus 考虑的边界条件更全面,Sonnet 有时候会漏掉一些 edge case。
还有一个不太常见但差距很大的场景:超长代码库的理解。当上下文超过 100K token,Opus 对细节的记忆和引用准确度明显更高,Sonnet 在这个量级偶尔会”丢”东西。
如果你主要用 Claude 做日常编程辅助——补全、解释、小范围修改——Sonnet 4.6 是更聪明的选择。省下来的钱可以多调几次。
推理深度:Opus 的护城河
编程能力差距不大,但推理能力的差距是实打实的。
第三方评测机构 Artificial Analysis 的 Intelligence Index 用来衡量模型的综合推理能力,Opus 4.6 大约在 53 分,Sonnet 4.6 在 51 分。两分的差距听起来不多,但在实际任务中的表现差异比数字暗示的要大。
Opus 在以下推理任务上优势明显:
多步骤逻辑链是最典型的。需要模型连续推理 5 步以上才能得出结论的问题,Opus 的准确率显著高于 Sonnet。比如分析一段复杂的业务流程,找出其中的逻辑漏洞,Opus 更不容易在中间步骤”走偏”。
长文档分析也是。给模型一份 50 页的技术文档,让它提取关键信息并做交叉验证,Opus 的信息提取完整度和引用准确度都更好。Sonnet 在处理长文档时偶尔会”遗忘”前面的内容——不是每次都这样,但频率够你注意到。
还有一个比较微妙的差异:当你的 prompt 写得不够精确时,Opus 更擅长”猜”你的真实意图。Sonnet 则更倾向于字面理解,有时候需要你把需求说得更明确。这个差异在日常使用中不太起眼,但如果你经常写比较随意的 prompt,会慢慢感受到。
不过话说回来,如果你的任务不涉及这种深度推理——比如翻译、摘要、格式转换——两个模型的表现基本一样,没必要为 Opus 多花钱。
速度和成本:Sonnet 的杀手锏
Sonnet 4.6 的响应速度大约是 Opus 的两倍。不是跑分数据,是实际使用中能感受到的差异。
用 Opus 生成一段 500 token 的代码,大概等 15-25 秒。换 Sonnet,8-12 秒。一天调几十次 API 的话,这个时间差累积起来很可观。
成本方面算一笔账。
假设你每天的用量是 100K 输入 token + 50K 输出 token(中等强度的开发辅助用量),一个月 22 个工作日:
- 用 Opus 4.6:(0.1 × $5 + 0.05 × $25) × 22 = $38.5/月
- 用 Sonnet 4.6:(0.1 × $3 + 0.05 × $15) × 22 = $23.1/月
一个月省 $15,一年省 $180。团队 5 个人就是 $900/年,不是小数目。
而且 Anthropic 的 Prompt Caching 对 Sonnet 同样有效。开启缓存后,重复的系统提示词部分只收 $0.30/百万 token(原价的十分之一),实际账单还能再降不少。
不同场景怎么选
不想看分析的,直接看这部分。
日常编程辅助——写代码、调 bug、代码审查——选 Sonnet 4.6。性能差距可以忽略,速度快一倍,成本低 40%。没什么好纠结的。
大规模代码重构或架构设计,选 Opus 4.6。这种任务需要模型对全局上下文有更强的把控力,Opus 的优势在这里才真正体现出来。
长文档分析看文档长度。10 万 token 以内用 Sonnet 就行,超过 10 万建议切 Opus,长上下文的信息保持能力差距比较明显。
AI Agent 工作流看步骤复杂度。简单的 3-5 步工具调用,Sonnet 完全胜任。10 步以上的复杂 Agent 链路,Opus 在保持一致性方面更可靠——步骤越多,这个差距越大。
批量处理(翻译、摘要、分类)直接选 Sonnet 4.6,甚至可以考虑 Haiku 4.5。这类任务对推理深度要求不高,用最便宜的模型就够了。
一个容易忽略的点:最大输出长度
Opus 4.6 的单次最大输出是 128K token,Sonnet 4.6 是 64K token。
大多数时候这个差异无所谓——日常对话和编程辅助,单次输出很少超过 4K token。但如果你的场景需要模型一次性生成很长的内容(比如完整的技术文档、长篇分析报告),128K 和 64K 的差距就很关键了。
另外,Opus 4.6 和 Sonnet 4.6 官方均已支持 1M 上下文窗口(已 GA),通过 OfoxAI 接入同样支持完整的 1M 上下文。对于需要处理大量上下文的场景,这是一个实际的优势。
国内开发者怎么接入
Claude 的 API 在国内没有直接的访问通道,需要通过 API 网关来调用。这里以 OfoxAI 为例说一下配置方式。
OfoxAI 支持 Anthropic 原生协议,Base URL 是 https://api.ofox.ai/anthropic,也支持 OpenAI 兼容协议(https://api.ofox.ai/v1)。如果你用的是 Claude 的官方 SDK,建议走 Anthropic 原生协议,功能支持更完整,Prompt Caching 也是原生的。
定价和 Anthropic 官方一致,支持微信和支付宝充值,不需要海外信用卡。具体的接入步骤可以参考《Claude API 国内怎么用》这篇教程,里面有详细的配置说明。
如果你还在纠结付费方式,《Claude API 付费指南》里整理了所有支付渠道的对比。
混合使用:最聪明的策略
不一定要二选一。
很多团队的做法是:日常开发用 Sonnet 4.6 当默认模型,遇到复杂任务再手动切换到 Opus 4.6。这样既不牺牲日常效率,又能在关键时刻用上最强的模型。
如果你用 Claude Code 做编程,它本身就支持在 Opus 和 Sonnet 之间切换。简单的补全和解释用 Sonnet,遇到需要深度思考的架构问题再切 Opus,这是目前性价比最高的用法。
对于 API 调用场景,可以在代码里做一个简单的路由逻辑:根据输入长度或任务类型自动选择模型。输入超过 50K token 或者任务标记为”复杂推理”的走 Opus,其余走 Sonnet。这种策略在不影响质量的前提下,通常能把总成本降低 30-50%。
想了解更多模型选型思路,可以看看《2026 大模型排行榜与选型指南》,里面不只是 Claude,还覆盖了 GPT-5.4、Gemini 3.1 Pro、DeepSeek V4 等主流模型的横向对比。
总结
Sonnet 4.6 是大多数人的正确选择。编程能力和 Opus 几乎持平,速度快一倍,价格便宜 40%。
Opus 4.6 适合对推理深度有硬需求的场景:超长上下文、复杂 Agent 工作流、大规模代码重构。如果你的任务经常涉及这些,多花的钱是值得的。
两个都用才是聪明人的做法——Sonnet 打底,Opus 兜底。
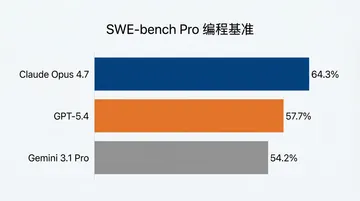
2026 年 4 月 Opus 4.7 已发布,编程能力比 Opus 4.6 又上了一档。本篇的选型逻辑仍然适用(贵 67%、速度慢一倍这两条是 Opus 系列的固定特征),但要换成最新一代算账,看《Claude Opus 4.7 vs Sonnet 4.6 怎么选》。
还在用 Sonnet 4.5、纠结要不要升 4.6?看《Claude Sonnet 4.5 vs 4.6 怎么选:升级值不值》,里面有迁移代价和实测数据。