Best AI Models in 2026: Complete Guide
Comprehensive ranking of the best AI models in 2026 — Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, DeepSeek V3.2, and more. Real benchmarks, pricing, and when to use each model.

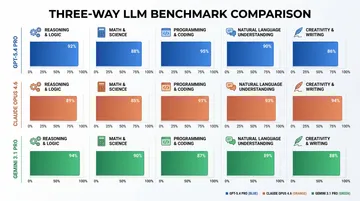
There is no single “best” AI model in 2026. Claude Opus 4.6 dominates coding benchmarks at 75.6% on SWE-Bench, GPT-5.4 leads in conversational tasks, Gemini 3.1 Pro excels at reasoning, and DeepSeek V3.2 offers the best price-performance ratio. The right model depends on your specific use case, budget, and latency requirements.
This guide ranks the top AI models across multiple dimensions — coding, reasoning, writing, cost-efficiency — using real benchmarks from MMLU, HumanEval, and SWE-Bench. All models listed are accessible via ofox.ai with a single API key.
Overall Rankings: Top 5 AI Models (May 2026)
Based on aggregate performance across coding, reasoning, writing, and real-world usage:
- Claude Opus 4.6 — Best for coding, technical writing, and complex reasoning
- GPT-5.4 — Best for conversational AI, creative writing, and general-purpose tasks
- Gemini 3.1 Pro — Best for multimodal tasks, long-context reasoning, and research
- DeepSeek V3.2 — Best price-performance ratio, strong coding capabilities
- Grok 4.20 — Best for real-time information and X/Twitter integration
Source: Best AI Models in 2026 Ranked, Top 5 LLMs for March 2026
Best AI Model by Use Case
Best for Coding
Winner: Claude Opus 4.6
- SWE-Bench Score: 75.6% (highest among all models)
- HumanEval: 94.2%
- Why it wins: Superior code generation, debugging, and refactoring capabilities. Handles complex multi-file changes better than competitors.
- Pricing via ofox: $5.00 / $25.00 per million tokens (input/output)
Runner-up: DeepSeek V3.2 — 92.8% HumanEval, significantly cheaper at $0.27 / $1.10 per million tokens (cache-miss pricing; cache-hit at $0.07).
Source: Best AI Model for Coding, Claude Opus 4.7 vs GPT-5.5 Benchmark
Best for Reasoning
Winner: Gemini 3.1 Pro
- GPQA Diamond: 94.3%
- MMLU-Pro: 88.3%
- Why it wins: Excels at multi-step reasoning, scientific problem-solving, and long-context analysis (1M token context window).
- Pricing via ofox: $2.00 / $12.00 per million tokens
Source: GPQA Benchmarks Explained, Gemini 3.1 Pro Model Card
Best for Writing & Content
Winner: GPT-5.4
- Why it wins: Most natural conversational tone, best at creative writing, marketing copy, and human-like responses.
- Pricing via ofox: $2.50 / $15.00 per million tokens
Runner-up: Claude Opus 4.6 — Better for technical documentation and structured content.
Best Price-Performance
Winner: DeepSeek V3.2
- Cost: $0.27 / $1.10 per million tokens (cache-miss pricing; cache-hit at $0.07) — 10x cheaper than Claude Opus
- Performance: 92.8% HumanEval, 85.2% MMLU
- Why it wins: Near-flagship performance at a fraction of the cost. Ideal for high-volume production workloads.
Source: Top 5 LLMs for March 2026
Best for Multimodal Tasks
Winner: Gemini 3.1 Pro
- Capabilities: Native image, video, and audio understanding
- Context: 1M tokens (can process entire codebases or long videos)
- Why it wins: Best-in-class vision capabilities, handles complex multimodal reasoning.
Detailed Model Comparison
Claude Opus 4.6 (Anthropic)
Strengths:
- Coding: 75.6% SWE-Bench (industry-leading)
- Technical writing and documentation
- Complex reasoning and analysis
- 1M context window
Weaknesses:
- Higher cost than alternatives
- Slower response time than GPT-5.4
Best for: Software development, technical documentation, code review, complex problem-solving
Access via ofox: anthropic/claude-opus-4.6
GPT-5.4 (OpenAI)
Strengths:
- Most natural conversational AI
- Creative writing and content generation
- Broad general knowledge
- Fast response times
Weaknesses:
- Not the strongest at pure coding tasks
- More expensive than DeepSeek/Qwen alternatives
Best for: Chatbots, content creation, customer support, general-purpose AI applications
Access via ofox: openai/gpt-5.4
Gemini 3.1 Pro (Google)
Strengths:
- 1M token context window
- Best multimodal capabilities
- Strong reasoning (94.3% GPQA)
- Competitive pricing
Weaknesses:
- Slightly behind Claude in pure coding tasks
- Less natural conversational tone than GPT-5.4
Best for: Research, long-document analysis, multimodal applications, scientific computing
Access via ofox: gemini/gemini-3.1-pro-preview
DeepSeek V3.2 (DeepSeek)
Strengths:
- Exceptional price-performance ratio
- Strong coding capabilities (92.8% HumanEval)
- Open-source model with commercial license
- Low latency
Weaknesses:
- Slightly behind flagship models in complex reasoning
- Less polished conversational abilities
Best for: Cost-sensitive production workloads, high-volume API calls, coding assistants
Access via ofox: deepseek/deepseek-chat (uses V3.2 backend)
Grok 4.20 (xAI)
Strengths:
- Real-time information access via X/Twitter
- Competitive pricing ($2.00 / $6.00 per million tokens)
- 2M context window
- Strong general capabilities
Weaknesses:
- Newer model with less production track record
- Not specialized for any particular domain
Best for: Applications requiring real-time information, social media integration, general-purpose tasks
Access via ofox: xai/grok-4.20
Source: xAI Grok API Pricing
Benchmark Comparison Table
| Model | MMLU | HumanEval | SWE-Bench | GPQA | Context | Price (Input/Output per 1M tokens) |
|---|---|---|---|---|---|---|
| Claude Opus 4.6 | 86.8% | 94.2% | 75.6% | 87.2% | 1M | $5.00 / $25.00 |
| GPT-5.4 | 88.7% | 92.0% | 68.3% | 85.5% | 1M | $2.50 / $15.00 |
| Gemini 3.1 Pro | 88.3% | 88.5% | 71.2% | 94.3% | 1M | $2.00 / $12.00 |
| DeepSeek V3.2 | 85.2% | 92.8% | 69.1% | 82.0% | 128K | $0.27 / $1.10 |
| Grok 4.20 | 84.5% | 89.0% | 65.0% | 83.0% | 2M | $2.00 / $6.00 |
Sources: AI Model Benchmarks 2026, Top AI Models March 2026, Claude Opus 4.6 Official, GPT-5.4 Official, Gemini 3.1 Pro Official
How to Choose the Right Model
Decision Framework
- Budget-constrained? → DeepSeek V3.2 or Qwen3-Max
- Need best coding performance? → Claude Opus 4.6
- Building a chatbot? → GPT-5.4
- Processing long documents? → Claude Opus 4.6 or Gemini 3.1 Pro (both 1M context)
- Need multimodal capabilities? → Gemini 3.1 Pro
- High-volume production? → DeepSeek V3.2 (best price-performance)
Cost Optimization Tips
- Use smaller models for simple tasks: Claude Sonnet 4.6 or GPT-5.4 Mini cost 5-10x less than flagship models
- Batch processing: Many providers offer 50% discounts for batch API calls
- Prompt caching: Reduce costs by 90% for repeated context (supported by Claude and Gemini)
- Model routing: Use cheaper models for initial filtering, flagship models for complex tasks
Source: Best AI Model Per Task
Access All Models via ofox.ai
Instead of managing multiple API keys and billing accounts across OpenAI, Anthropic, Google, and others, ofox.ai provides unified access to 100+ AI models through a single API key.
Why Use ofox?
- Single integration: OpenAI-compatible API works with all models
- Transparent pricing: Standard provider pricing with no markup
- No vendor lock-in: Switch models without code changes
- 99.9% SLA: Enterprise-grade reliability
- Global acceleration: Low-latency access worldwide
Quick Start
from openai import OpenAI
client = OpenAI(
base_url="https://api.ofox.ai/v1",
api_key="YOUR_OFOX_API_KEY"
)
# Use Claude Opus 4.6
response = client.chat.completions.create(
model="anthropic/claude-opus-4.6",
messages=[{"role": "user", "content": "Explain quantum computing"}]
)
# Switch to GPT-5.4 by changing one line
response = client.chat.completions.create(
model="openai/gpt-5.4",
messages=[{"role": "user", "content": "Explain quantum computing"}]
)Get started at ofox.ai — free tier includes access to all models.
Emerging Models to Watch
Chinese AI Models Gaining Ground
- Kimi K2: 200K context, strong Chinese language support
- Qwen3-Max: Alibaba’s flagship, competitive with GPT-5.4
- GLM-5: Zhipu AI’s latest, strong reasoning capabilities
These models offer competitive performance at lower costs, especially for Chinese language tasks.
Open-Source Alternatives
- Llama 4 Maverick: Meta’s latest, strong coding capabilities
- Mistral Large 3: European alternative with strong multilingual support
Source: Best AI Models April 2026
Frequently Asked Questions
Which AI model is the most accurate?
It depends on the task. Gemini 3.1 Pro scores highest on reasoning benchmarks (94.3% GPQA), Claude Opus 4.6 leads in coding (75.6% SWE-Bench), and GPT-5.4 excels at conversational tasks. There is no single “most accurate” model across all domains.
What is the cheapest AI model?
DeepSeek V3.2 offers the best price-performance ratio at $0.27 / $1.10 per million tokens, delivering near-flagship performance at 10x lower cost than Claude Opus 4.6.
Can I use multiple AI models in one application?
Yes. Using an API gateway like ofox.ai, you can route different tasks to different models — use Claude for coding, GPT-5.4 for chat, and DeepSeek for high-volume tasks — all with a single API integration.
Are open-source models as good as proprietary ones?
For many tasks, yes. DeepSeek V3.2 and Llama 4 match or exceed GPT-4-level performance on coding and reasoning benchmarks. However, flagship models like Claude Opus 4.6 and GPT-5.4 still lead on the most complex tasks.
How often do AI model rankings change?
Every 1-2 months. Major providers release new models frequently. In late April 2026, Claude Opus 4.7 (April 16), GPT-5.5 (April 23), and DeepSeek V4 (April 24) all launched within an 8-day span. Subscribe to model provider blogs or use an API gateway that automatically adds new models.
Conclusion
The best AI model in 2026 is the one that fits your specific use case and budget. Claude Opus 4.6 dominates coding, GPT-5.4 leads conversational AI, Gemini 3.1 Pro excels at reasoning and multimodal tasks, and DeepSeek V3.2 offers unbeatable price-performance. Rather than committing to a single provider, use an API gateway like ofox.ai to access all models through one integration — giving you the flexibility to choose the right tool for each task.
Start experimenting with all models at ofox.ai — free tier includes access to Claude, GPT, Gemini, DeepSeek, and 100+ other models.