DeepSeek V4: 1.6T MoE, 1M Context, Apache 2.0, Cheaper Than GPT-5.5
DeepSeek V4 lands same day as GPT-5.5: 1.6T-param Pro, 284B Flash, 1M context, open Apache 2.0 weights, and API pricing that undercuts GPT-5.5, Opus 4.7, and Kimi K2.6.
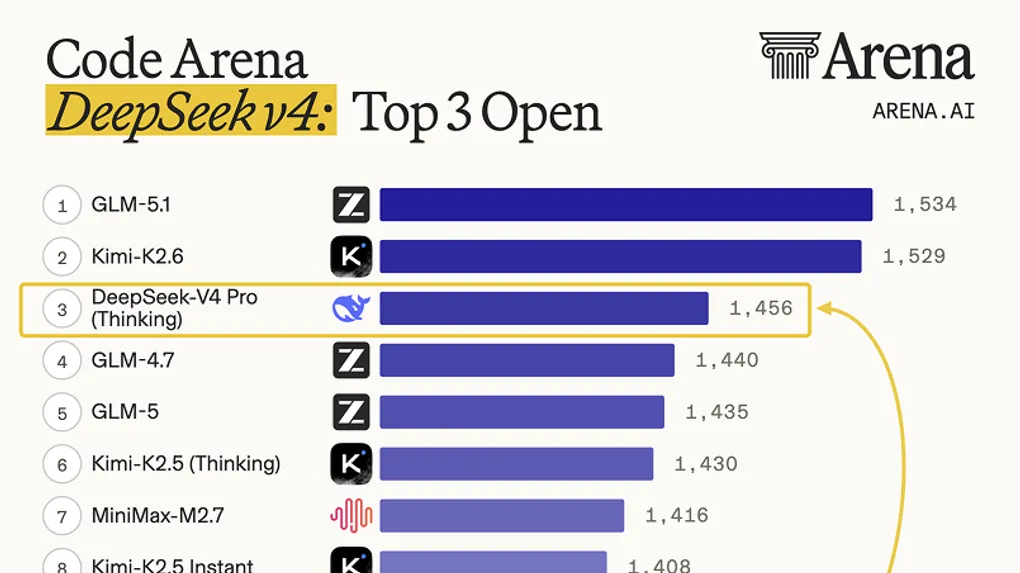
TL;DR — DeepSeek picked the same day as OpenAI’s GPT-5.5 to ship V4 preview. 1.6T-parameter Pro, 284B Flash, 1M context on both, Apache 2.0 weights on Hugging Face, and API pricing of $1.74 / $3.48 per million tokens for Pro — less than Opus 4.7, less than GPT-5.5, less than Kimi K2.6. ofox will support it at first opportunity.
SALE — $5 free credit for new users — Track DeepSeek V4 availability and pricing on ofox.ai with one OpenAI-compatible key.
What DeepSeek shipped
From the official announcement on April 24 2026:
- Two variants:
deepseek-v4-pro(1.6T total parameters, 49B activated) anddeepseek-v4-flash(284B total, 13B activated). Both are MoE. - 1M-token context on both, max output 384K.
- Dual modes: Thinking / Non-Thinking, with three effort levels (
high,max, plus non-think). See thinking mode docs. - Open source, Apache 2.0 — weights on Hugging Face.
- API live today. Same
base_url, change model ID. Both OpenAI ChatCompletions and Anthropic protocols supported. - Deprecation:
deepseek-chatanddeepseek-reasonerretire July 24 2026. They currently route todeepseek-v4-flash.
The timing is not accidental. OpenAI shipped GPT-5.5 the same day. DeepSeek needed a launch window where “open-source 1M-context MoE at a fraction of the cost” would not be buried under a closed-source price hike. Ship on the same day and you split the news cycle.
Architecture — the part that actually matters
V4 introduces a hybrid attention mechanism: Compressed Sparse Attention (CSA) + Heavily Compressed Attention (HCA). Combined with Manifold-Constrained Hyper-Connections (mHC) for residual signal propagation and the Muon optimizer for training stability, the net effect at 1M context is:
- 27% of V3.2’s single-token inference FLOPs
- 10% of V3.2’s KV cache
That is the headline efficiency story. Long-context inference was the main cost barrier for open models serving 1M windows; V4 cuts it by an order of magnitude on KV cache. The model was pre-trained on 32T+ tokens using FP4 + FP8 mixed precision — MoE experts at FP4, most other parameters at FP8.
The Flash variant is not a trimmed Pro — it is a separately trained MoE at 284B / 13B activated. Flash-Max (max thinking effort) approaches Pro-level reasoning on most benchmarks with a much lower serving cost.
The Arena Code numbers
Arena AI’s live code leaderboard put V4-Pro Thinking straight at #3 among open models, ahead of the rest of DeepSeek’s prior releases by a large margin:
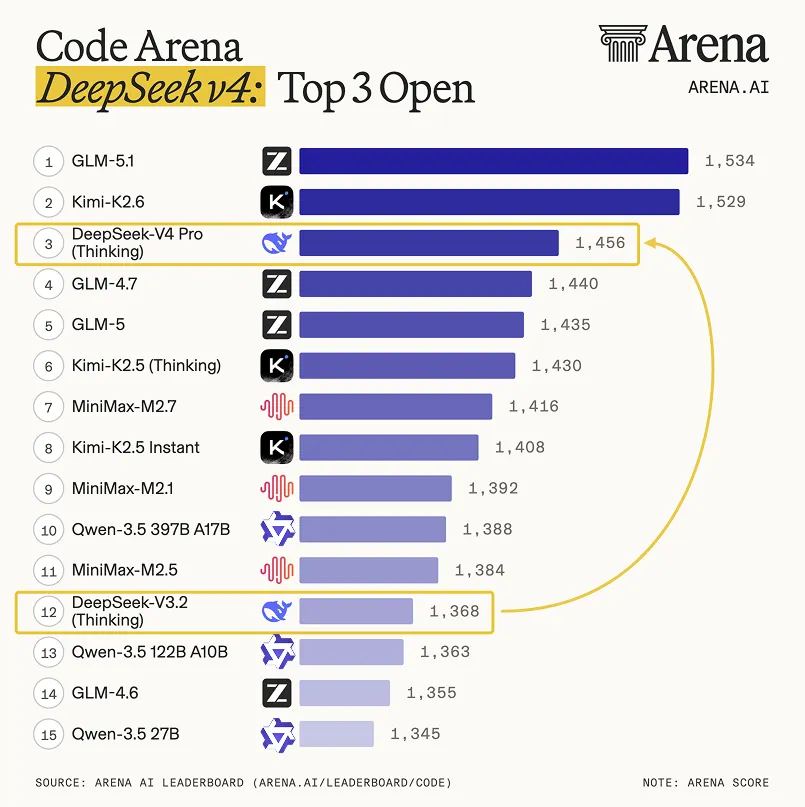
Source: Arena AI Code Leaderboard, April 24 2026
| Rank | Model | Elo |
|---|---|---|
| 1 | GLM-5.1 | 1,534 |
| 2 | Kimi-K2.6 | 1,529 |
| 3 | DeepSeek-V4 Pro (Thinking) | 1,456 |
| 4 | GLM-4.7 | 1,440 |
| 12 | DeepSeek-V3.2 (Thinking) | 1,368 |
The V3.2 → V4-Pro jump is 88 Elo — roughly the same delta between #3 and #13 on the current board. It is a genuine generational step, not a refresh.
Full benchmark grid — vs K2.6, GLM-5.1, Opus 4.6, GPT-5.4, Gemini 3.1 Pro
DeepSeek published the complete head-to-head against the top open and closed models:
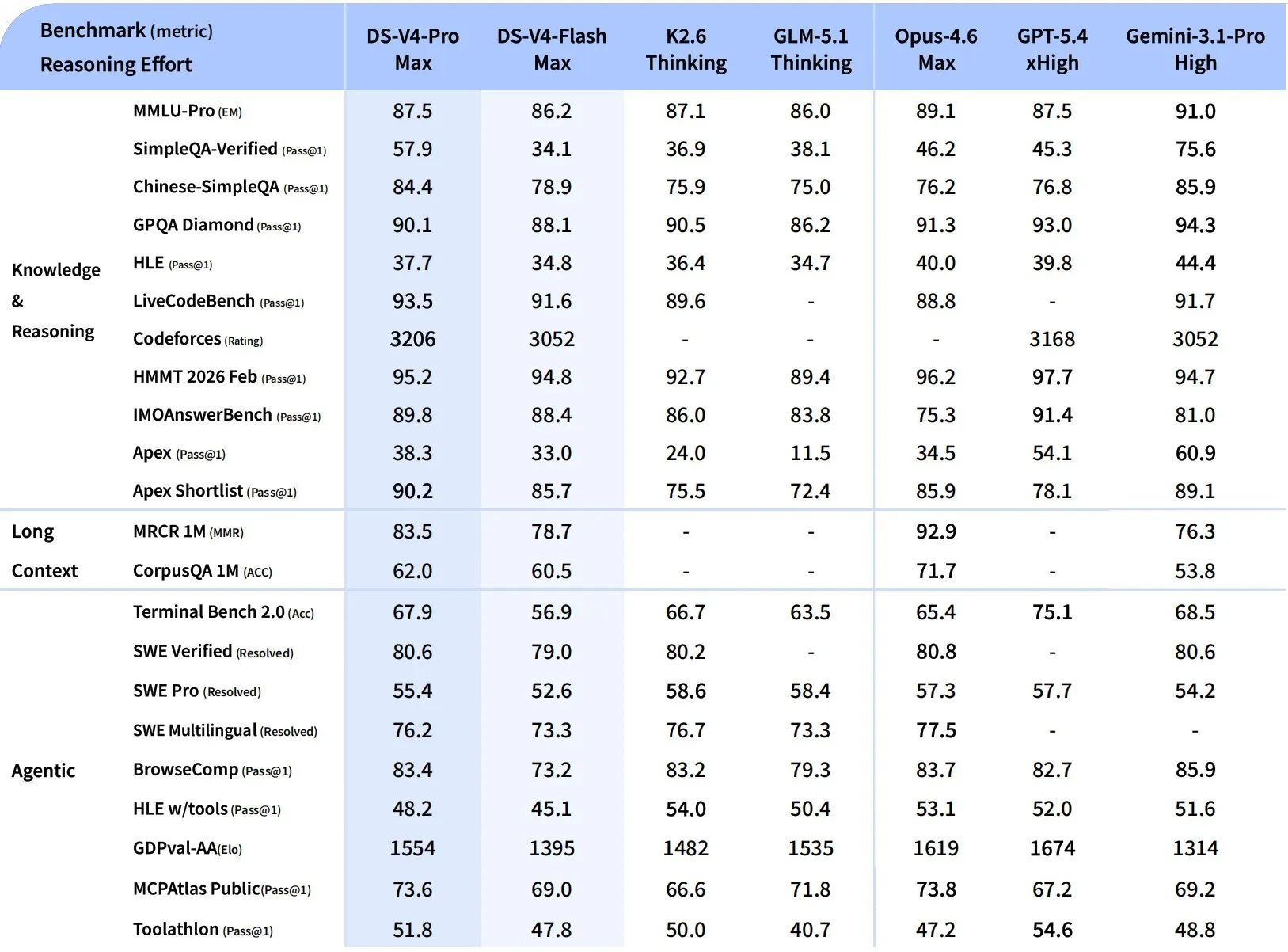
Source: DeepSeek V4 technical report, April 24 2026
The honest reading, benchmark by benchmark:
Where V4-Pro wins outright:
| Benchmark | V4-Pro Max | K2.6 Thinking | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Chinese-SimpleQA | 84.4 | 75.9 | 76.2 | 76.8 | 85.9 |
| LiveCodeBench | 93.5 | 89.6 | 88.8 | — | 91.7 |
| Codeforces (rating) | 3206 | — | — | 3168 | 3052 |
| HMMT 2026 Feb | 95.2 | 92.7 | 96.2 | 97.7 | 94.7 |
| IMOAnswerBench | 89.8 | 86.0 | 75.3 | 91.4 | 81.0 |
| MCPAtlas Public | 73.6 | 66.6 | 73.8 | 67.2 | 69.2 |
Codeforces 3206 is the line that matters. That is better than GPT-5.4 (xHigh) at 3168 — competitive-programming territory where closed frontier models have historically held the lead.
Where V4-Pro loses to K2.6:
| Benchmark | V4-Pro | K2.6 Thinking |
|---|---|---|
| SWE Pro (resolved) | 55.4 | 58.6 |
| SWE Multilingual | 76.2 | 76.7 |
| HLE w/tools | 48.2 | 54.0 |
| GPQA Diamond | 90.1 | 90.5 |
SWE-Bench Pro is the benchmark that matters most for “fix a real GitHub issue.” K2.6’s 58.6 vs V4-Pro’s 55.4 is a 3-point gap — small, but consistent with the Arena Code leaderboard where K2.6 sits 73 Elo ahead.
Where V4-Pro trails the closed frontier:
- MRCR 1M (long-context retrieval): 83.5 vs Opus 4.6’s 92.9. Opus is still the long-context leader.
- CorpusQA 1M: 62.0 vs Opus 71.7. Same story.
- GDPval-AA (Elo): 1554 vs GPT-5.4’s 1674 and Opus 4.6’s 1619. Knowledge-work economic value still favors the closed models.
- HLE (no tools): 37.7 vs Gemini 3.1 Pro’s 44.4.
Flash-Max holds up:
V4-Flash-Max hits 86.2 on MMLU-Pro (Pro at 87.5), 91.6 on LiveCodeBench (Pro at 93.5), and 52.6 on SWE-Pro (Pro at 55.4). For most tasks the quality gap between Flash and Pro is narrow — and Flash is dramatically cheaper.
Pricing — where V4 really changes the calculus
From the DeepSeek pricing docs:
| Model | Input (miss) | Input (hit) | Output |
|---|---|---|---|
deepseek-v4-flash | $0.14 / M | $0.028 / M | $0.28 / M |
deepseek-v4-pro | $1.74 / M | $0.145 / M | $3.48 / M |
Compare to the frontier:
| Model | Input | Output |
|---|---|---|
| DeepSeek V4-Pro | $1.74 | $3.48 |
| Kimi K2.6 (non-think) | $1.40 | $5.60 |
| GPT-5.5 | $5.00 | $30.00 |
| Claude Opus 4.7 | $15.00 | $75.00 |
V4-Pro output is $3.48 vs GPT-5.5’s $30. That is 8.6× cheaper. Against Opus 4.7 it is 21× cheaper. Flash at $0.28 output is essentially free.
This is the single biggest story of the release. You can now run a 1M-context, Codeforces-3200-tier reasoning model in production for the same budget that used to cover a mid-tier chat endpoint.
Community takes
First-day reactions from the open-source and research community:
- “Apache 2.0 matters.” V3 was MIT; V4 moves to Apache 2.0, giving enterprises clearer patent protection. For commercial deployments this is the material change.
- “Chinese SimpleQA is a wake-up call.” 84.4 on Chinese-SimpleQA beats every closed model except Gemini 3.1 Pro. For Chinese-first products this is the first open-weight option that is genuinely at parity with the best.
- “SWE-Pro is closer than the Arena board suggests.” K2.6 leads by 3 points on SWE-Pro, but V4-Pro leads on LiveCodeBench and Codeforces. Short-form code generation vs long-horizon codebase resolution — they are different skills, and the picks split cleanly.
- “The 1M context is real, but not Opus-level.” MRCR and CorpusQA show Opus 4.6 still holds the long-context crown. V4’s win is efficiency (10% KV cache), not absolute retrieval quality.
Access via ofox (coming soon)
ofox serves deepseek/deepseek-v3.2 today. V4-Pro and V4-Flash are being added at first opportunity — expect them on the model list shortly.
For now, if you want V4 immediately, you can hit DeepSeek’s own API directly:
from openai import OpenAI
client = OpenAI(
api_key="your-deepseek-key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "Port this Rust service to Go, preserving concurrency semantics"}],
extra_body={"thinking": {"type": "enabled"}}
)
print(response.choices[0].message.content)Once ofox rolls V4 into the aggregator, the switch is one line — same ofox key, same https://api.ofox.ai/v1 base URL, just deepseek/deepseek-v4-pro or deepseek/deepseek-v4-flash. Sign up at ofox.ai and one key will cover V4 the moment it lands alongside GPT-5.5, Claude, Gemini, Kimi K2.6, and the rest.
Should you switch?
Switch to V4-Pro if you are running Kimi K2.6 for Chinese-heavy workloads, competitive-programming-style code generation, or Codeforces-grade reasoning. The Chinese SimpleQA and Codeforces numbers are the reason.
Switch to V4-Flash if you are running anything in the $1-2 per million output token range. Flash-Max’s reasoning is within 1-3 points of Pro on most knowledge benchmarks, and 12× cheaper than V4-Pro on output.
Stay on K2.6 if your workload is SWE-Bench-style codebase resolution, agent tool calls under high concurrency, or anything where the Arena Code delta (K2.6 +73 Elo) maps to your task.
Stay on closed frontier (GPT-5.5 / Opus 4.7) if your tasks are long-context retrieval over millions of tokens (Opus MRCR still wins), GDPval-grade knowledge work (GPT-5.4 still wins), or agentic terminal workflows (GPT-5.5 Terminal-Bench 82.7% is in its own tier).


