Gemini 3.1 Flash Lite vs DeepSeek V4 Flash for Agent Loops
DeepSeek V4 Flash is cheaper per token, but Flash Lite's 76.5% BFCL v3 score often wins on total cost. We break down the agent-loop math and tool-call reliability.
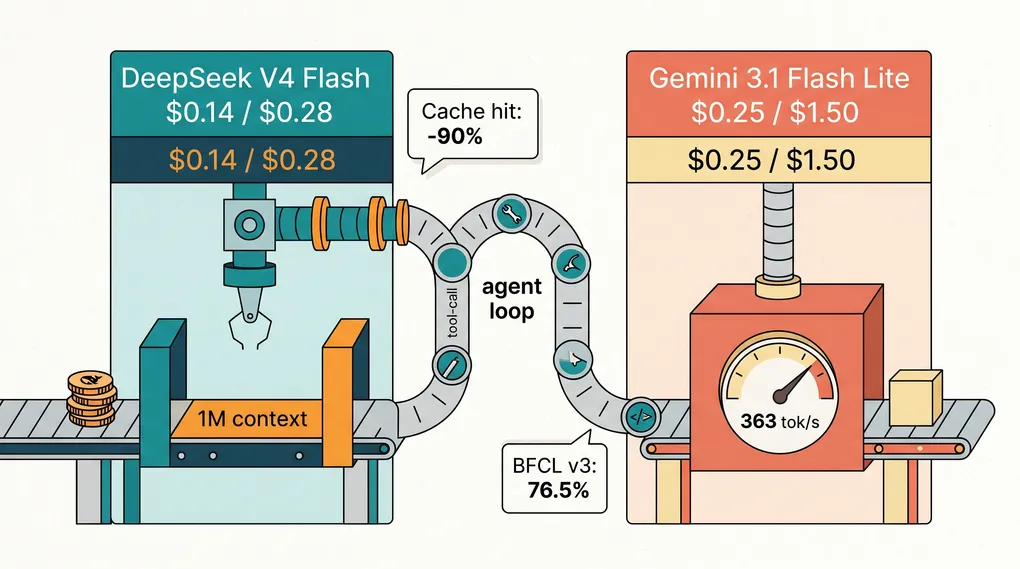
TL;DR — DeepSeek V4 Flash is the cheaper raw API; Gemini 3.1 Flash Lite is the more reliable agent. The right question isn’t “which costs less per token,” it’s “which model burns fewer total tokens to finish your loop.” On bounded loops with stable system prompts, DeepSeek wins on both axes once cache hits kick in. On longer tool-call chains and unfamiliar APIs, Flash Lite’s 76.5% BFCL v3 score and faster time-to-first-token earn back the price premium by finishing on the first try. If your agent loop costs $0.50 to run and Flash Lite needs one attempt where DeepSeek needs two, you’ve already lost the savings.
SALE — $5 free credit for new users — Run DeepSeek V4 Flash and Gemini 3.1 Flash Lite from one ofox.ai key, no SDK rewiring.
The Two Models, Without the Marketing
One thing to clear up first: “Gemini 3.1 Flash” as a standalone tier doesn’t exist in May 2026. Google ships Gemini 3.1 Flash Lite Preview and Gemini 3 Flash Preview. When people say “3.1 Flash” in benchmarks, they usually mean Flash Lite. The standard “Flash” line is still on the 3.0 release, priced at $0.50 input and $3.00 output per million tokens. For budget agent loops, Flash Lite is the relevant Google product.
| Model | Architecture | Context | Output cap | List price (in / out per M) |
|---|---|---|---|---|
| Gemini 3.1 Flash Lite Preview | Dense | 1,048,576 | 65,536 | $0.25 / $1.50 |
| DeepSeek V4 Flash | MoE (284B total, 13B active) | 1,000,000 | 384,000 | $0.14 / $0.28 |
Both models are available on ofox at list price (ofox model catalog, verified 2026-05-14). DeepSeek V4 Flash also has a generous cache-hit rebate: cached input at $0.0028 per million, a 98% discount versus cache-miss (dropped to 1/10 of the launch rate on 2026-04-26). Gemini 3.1 Flash Lite does offer text cache reads at $0.025 per million (and audio at $0.05), but at roughly 9x DeepSeek’s cached rate (Google Gemini API pricing, verified 2026-05-14).
The output cap difference is worth flagging upfront. DeepSeek V4 Flash will emit up to 384K output tokens in one turn; Flash Lite caps at 65K. For agent loops that generate long structured reports — comprehensive test plans, multi-file refactors output as a single response — DeepSeek has more headroom before it has to chunk.
What 100M Tokens Actually Costs
Let’s run the math on a realistic agent workload. Assume a coding agent that processes 70M input tokens and emits 30M output tokens per month — a typical mid-volume team running automated refactor passes, test generation, and documentation jobs.
At list price, no cache hits:
| Model | Input cost | Output cost | Monthly total |
|---|---|---|---|
| DeepSeek V4 Flash | $9.80 | $8.40 | $18.20 |
| Gemini 3.1 Flash Lite | $17.50 | $45.00 | $62.50 |
DeepSeek is 3.4x cheaper end-to-end. The output gap is where the spread opens — Flash Lite’s $1.50/M output rate is a real tax on agent loops that emit verbose tool-call rationales or long code blocks.
Now factor in cache hits. Most agent loops with a stable system prompt land in the 60-75% range — every tool result invalidates part of the context, so the 90%+ rates you see in marketing material don’t survive contact with real workloads (this is covered in detail in our V4 Pro vs Flash analysis).
At 70% cache hit, DeepSeek V4 Flash’s effective input rate drops to roughly $0.044/M and Flash Lite’s drops to roughly $0.093/M:
| Model | Effective input (70% cache) | Output | Monthly total |
|---|---|---|---|
| DeepSeek V4 Flash | $3.08 | $8.40 | $11.48 |
| Gemini 3.1 Flash Lite | $6.48 | $45.00 | $51.48 |
That’s a 4.5x gap. If your agent loop has a stable system prompt and you actually pull cache discount, DeepSeek V4 Flash is closer to free than to Flash Lite’s price band — the output multiplier is what keeps the total spread wide, since Flash Lite has no cache lever on the output side.
Where the Cheaper Model Quietly Loses
Per-token math is the first layer. The second layer is total tokens consumed — which depends on how many attempts the model needs to finish the task.
Tool-call reliability. Gemini 3.1 Flash Lite hits 76.5% on BFCL v3 (Google DeepMind model card), comfortably above the rough 70% production viability bar. DeepSeek V4 Flash scores 86.2 on MMLU Pro and 79 on SWE-bench Verified (DeepSeek V4 Flash model card) but takes a measurable hit on Terminal Bench 2.0 multi-step tool traces versus V4 Pro. The pattern across community testing converges: Flash handles 4-6 tool-call chains cleanly and starts compounding errors past 8. Flash Lite holds together longer on the same trace depth.
Time to first token. Flash Lite is the faster model in the loop. Google’s published numbers are 2.5x faster Time to First Answer Token and a 45% output speed increase versus Gemini 2.5 Flash; Artificial Analysis measures roughly 347 output tokens per second on Google’s API. DeepSeek V4 Flash doesn’t publish a comparable spec, but field reports across recent agent benchmark threads put it in the 150-200 tok/s band on standard providers. For interactive coding agents where a human is waiting on the response, the gap is felt. For batch overnight runs, it’s invisible.
Unfamiliar tool schemas. Gemini’s training on Google’s own tool-use traces gives Flash Lite an edge on unfamiliar function signatures — it tends to follow the schema correctly on the first try, even for tools it hasn’t seen in benchmarks. DeepSeek V4 Flash is excellent on standard JSON-Schema function calls but slightly worse at recovering when a tool returns a malformed response. If your agent uses a long tail of internal tools with bespoke schemas, this gap matters.
Output verbosity discipline. Flash Lite produces tighter output by default — closer to what a senior engineer would write in a code review comment. DeepSeek V4 Flash tends to add explanatory prose around code blocks, which is fine for documentation but inflates token bills on agent loops where the consumer is another LLM, not a human. You can prompt around this, but it’s friction.
The point here isn’t that one model is better. It’s that the headline price gap shrinks once you account for retry rates and token verbosity. If DeepSeek needs 1.4 attempts on average to complete a task where Flash Lite needs 1.0, the effective cost ratio collapses from 3.4x to roughly 2.4x. If it needs 2.0 attempts, the gap is essentially gone.
Decision Rules
After running both models across a few weeks of mixed agent workloads, here’s the rule we’d write down:
Pick DeepSeek V4 Flash when:
- Your loops are bounded (4-6 tool calls, fits in one or two files)
- You have a stable system prompt and can confirm 60%+ cache hit rate from your dashboard
- Output volume per task is high (long code generation, multi-file outputs, structured reports)
- Cost is the binding constraint and you can route failures elsewhere
Pick Gemini 3.1 Flash Lite when:
- Your loops chain 6-12 tool calls or involve unfamiliar tool schemas
- Interactive latency matters (developer-facing IDE agents, chat-style copilots)
- Output is short and structured (JSON responses, tool calls, terse summaries)
- You haven’t profiled cache hit rates yet and don’t want to budget on optimistic assumptions
Route both when you’re running mixed workloads. Wire a classifier in front (or use ofox’s unified endpoint to swap by model name without touching SDK code) and dispatch bounded tasks to DeepSeek, multi-step or schema-heavy tasks to Flash Lite. The routing logic is more valuable than either model choice — covered in our hybrid routing pattern guide and the broader agent model selection writeup.
What “Budget Agent Loop” Actually Means
A footnote on terminology, since “budget” gets stretched in marketing copy. There are three workload shapes that get called “budget agent loops”:
- High-frequency low-stakes — chat triage, intent classification, data extraction from semi-structured docs. Both models are massively overkill here; you might consider free-tier options before paying for either.
- Bounded coding tasks at scale — automated test generation, scaffolding, single-file refactors. DeepSeek V4 Flash wins on cost and quality is close enough that the routing question rarely comes up.
- Multi-step research or planning — read 10 docs, synthesize, output a plan. Flash Lite’s tool-call reliability earns its premium here, especially if you’re hitting unfamiliar tools.
If your “high-volume agent loop” actually means category 1 or 2, DeepSeek is the answer. If it means category 3 with longer chains, Flash Lite’s reliability quietly compounds.
How to Run Both Through One Endpoint
If you’re running on ofox, both models are exposed through the same OpenAI-compatible endpoint. Swap the model name, keep the rest of the request shape identical:
from openai import OpenAI
client = OpenAI(api_key=OFOX_KEY, base_url="https://api.ofox.ai/v1")
resp = client.chat.completions.create(
model="deepseek-v4-flash", # or "google/gemini-3.1-flash-lite-preview"
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_msg}],
tools=TOOL_SCHEMA,
)Verify the exact model IDs on the ofox catalog before deploying — preview model names can shift as Google promotes Flash Lite from preview to GA. For broader context on multi-model dispatch through a single key, see the aggregation gateway overview.
The Bottom Line
DeepSeek V4 Flash is the cheaper API on the table, and once cache hits kick in, total monthly spend stays in the 4-5x range — Flash Lite’s text cache narrows the input-side gap but the output multiplier keeps the total wide. For bounded coding agents, it’s the default choice — Flash Lite is paying for capabilities you won’t use. For multi-step tool loops, schema-heavy workflows, and any place where retry rates matter more than per-token cost, Gemini 3.1 Flash Lite’s reliability is worth the premium. The cheapest model is whichever one finishes the task the first time — and for budget agent loops, that’s a workload-specific answer, not a global one.
For pricing context on the broader DeepSeek family, see the DeepSeek API pricing breakdown. For Gemini’s higher tier, the Gemini 3.1 Pro deep dive covers the trade space against Flash Lite. The broader landscape across vendors is in the Claude vs GPT vs Gemini model comparison and the LLM API selection matrix.