Text Embedding Models Compared: OpenAI vs Gemini via One API (2026)
Compare text-embedding-3-small, text-embedding-3-large, and Gemini Embedding 2 Preview on price, accuracy, and use case. All three accessible via ofox with one API key.
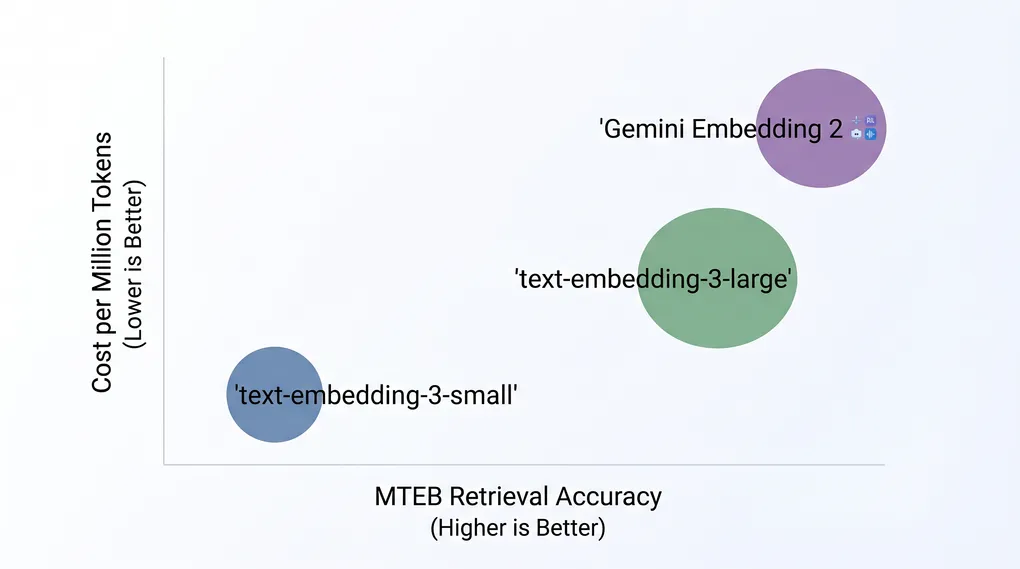
TL;DR text-embedding-3-small ($0.02/M tokens) is the right default for most projects — it’s 6.5x cheaper than text-embedding-3-large with only a modest accuracy trade-off. Upgrade to text-embedding-3-large when retrieval quality is critical. Choose Gemini Embedding 2 Preview ($0.20/M tokens) only if you need multimodal embeddings (text + images + audio in one vector space). All three are accessible via ofox at https://api.ofox.ai/v1 with a single API key.
The most common mistake developers make with embeddings is defaulting to the largest model — text-embedding-3-small handles 90% of use cases at a fraction of the cost.
Why Your Embedding Model Choice Matters
Embeddings are the foundation of semantic search, RAG pipelines, recommendation systems, and clustering. Unlike LLM calls where you can swap models mid-project, switching embedding models requires re-indexing your entire vector database — a painful migration at scale.
Three dimensions matter when picking a model:
- Accuracy: MTEB benchmark scores predict real-world retrieval quality across retrieval, classification, and clustering tasks
- Cost: At 100M tokens/month, the difference between $0.02 and $0.20 per million is $2/month vs $20/month
- Modality: Text-only vs multimodal (text + images + audio in a shared vector space)
The Three Models on ofox
ofox currently offers three embedding models, all accessible via the same OpenAI-compatible endpoint:
| Model | API ID | Price (text) | Dimensions | Context | MTEB Retrieval |
|---|---|---|---|---|---|
| text-embedding-3-small | text-embedding-3-small | $0.02/M | 1536 | 8,191 tok | Good |
| text-embedding-3-large | text-embedding-3-large | $0.13/M | 3072 | 8,191 tok | 64.6 |
| Gemini Embedding 2 Preview | google/gemini-embedding-2-preview | $0.20/M | 3072 | 8K tok | 68.16 |
Gemini Embedding 2 also supports image, audio, and video inputs — the only model here that handles non-text content. Per-modality pricing for non-text inputs is not listed on the standard pricing page; verify current rates on the Vertex AI pricing page before budgeting multimodal workloads.
When Each Model Wins
text-embedding-3-small — The Practical Default
At $0.02 per million tokens, text-embedding-3-small is the cheapest option on ofox. It produces 1536-dimensional vectors and handles standard English retrieval tasks well enough for most production workloads.
Use it for:
- RAG pipelines where cost matters more than marginal accuracy gains
- High-volume applications (millions of embeddings per day)
- Prototyping and development before you’ve benchmarked your actual data
Skip it when:
- You’re building a production search system where retrieval quality directly affects user experience
- Your documents are highly technical or domain-specific (legal, medical, code) — the larger model’s richer representations help here
text-embedding-3-large — The Quality Benchmark
text-embedding-3-large scores 64.6 on MTEB retrieval benchmarks, near the top of the leaderboard for text-only models. Its 3072-dimensional vectors capture more nuanced semantic relationships.
One underused feature: the dimensions parameter lets you reduce output size without retraining. Request 256, 1024, or 3072 dimensions depending on your storage constraints. Going from 3072 to 1024 dimensions costs about 1-2% accuracy while cutting vector storage by 66% — a worthwhile trade-off at scale.
Use it for:
- Production search where retrieval quality is a core product metric
- Legal, medical, or technical document retrieval
- Multilingual applications (better cross-lingual transfer than the small model)
Gemini Embedding 2 Preview — The Multimodal Option
Gemini Embedding 2 is Google’s first natively multimodal embedding model. It maps text, images, audio, and video into a single shared vector space — meaning a text query can retrieve relevant images, and vice versa, without separate pipelines or cross-modal translation layers.
It scores 68.16 on MTEB, outperforming text-embedding-3-large (64.6) by roughly 3.5 points on text retrieval while adding multimodal capability. That combination is hard to beat if your application touches more than one content type.
Use it for:
- Applications that need to search across content types (e.g., “find product images matching this description”)
- Document understanding pipelines that mix text and images (PDFs, presentations, slides)
- When you want the highest text retrieval accuracy currently available on ofox
Skip it when:
- You only need text embeddings — the $0.20/M price is 10x text-embedding-3-small for similar text-only performance
- You need stable production APIs (it’s still in Preview and subject to change)
Getting Started: One API Key, Three Models
All three models use the same OpenAI-compatible endpoint. Switch models by changing one string:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_OFOX_KEY",
base_url="https://api.ofox.ai/v1"
)
response = client.embeddings.create(
model="text-embedding-3-small", # swap to "text-embedding-3-large" or "google/gemini-embedding-2-preview"
input="How do I configure rate limiting in nginx?"
)
embedding = response.data[0].embedding
print(f"Dimensions: {len(embedding)}") # 1536 for small, 3072 for large/geminiFor text-embedding-3-large with reduced dimensions:
response = client.embeddings.create(
model="text-embedding-3-large",
input="Your text here",
dimensions=1024 # reduce from 3072 to save storage
)For Gemini Embedding 2 with image input, use the Gemini protocol endpoint — the OpenAI-compatible endpoint handles text inputs only.
Cost at Scale
| Monthly volume | text-embedding-3-small | text-embedding-3-large | Gemini Embedding 2 |
|---|---|---|---|
| 10M tokens | $0.20 | $1.30 | $2.00 |
| 100M tokens | $2.00 | $13.00 | $20.00 |
| 1B tokens | $20.00 | $130.00 | $200.00 |
For most teams, the $0.02/M price of text-embedding-3-small makes the cost question irrelevant — you’d need to embed billions of tokens before it becomes a meaningful line item. The real decision is accuracy vs cost, not absolute cost.
If you’re optimizing costs across your entire AI stack, the how to reduce AI API costs guide covers batching strategies and caching patterns that apply to embedding calls too.
The Decision Framework
- Building a prototype or cost-sensitive app? → text-embedding-3-small
- Production search where quality matters? → text-embedding-3-large
- Need to search across text + images + audio? → Gemini Embedding 2 Preview
- Not sure? → Start with text-embedding-3-small, benchmark against your actual data, upgrade if retrieval quality is insufficient
For a deeper dive into building complete RAG pipelines with these models — chunking strategies, vector databases, hybrid search, and reranking — see the Embedding APIs for RAG guide.
All three models are available via ofox’s unified API gateway — one key, one endpoint, no separate accounts for OpenAI and Google.
The real advantage of a unified API gateway isn’t just convenience — it’s being able to A/B test embedding models against your actual retrieval data without managing multiple API keys and billing accounts.