Claude Opus 4.7 vs Sonnet 4.6 怎么选:新一代 Opus 上线后的升级账
Opus 4.7 把 SWE-bench 拉到 87.6%,比 Sonnet 4.6 高 8 个百分点。但价格也贵 67%。本文用真实价格、benchmark 和场景拆解,告诉你什么时候该升级、什么时候继续用 Sonnet 4.6。
Anthropic 在 2026 年 4 月 16 日发了 Opus 4.7,距离 Sonnet 4.6 上线两个月。SWE-bench Verified 从 80.8% 跳到 87.6%——单次版本号小步迭代里少见的幅度。
问题来了:原本”Sonnet 够用”的判断还成立吗?
TL;DR — Opus 4.7 比 Sonnet 4.6 贵 67%,换 SWE-bench 8 个百分点和更稳的多步骤推理。日常编程、批处理、实时应用继续用 Sonnet 4.6 性价比最高;跨文件大重构、10 步以上 Agent 链、高分辨率视觉理解这三类硬场景升级 Opus 4.7 划算。已经在用 Opus 4.6 的,直接换 4.7(同价)。
一张表先把数字摊开
| Opus 4.7 | Opus 4.6 | Sonnet 4.6 | |
|---|---|---|---|
| 输入价格 | $5 / 百万 token | $5 / 百万 token | $3 / 百万 token |
| 输出价格 | $25 / 百万 token | $25 / 百万 token | $15 / 百万 token |
| 上下文窗口 | 1M token | 1M token | 1M token |
| SWE-bench Verified | 87.6% | 80.8% | 79.6% |
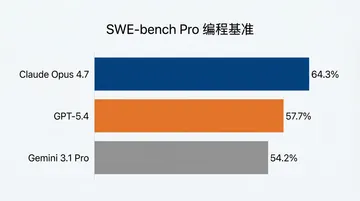
| SWE-bench Pro | 64.3% | 53.4% | — |
| GPQA Diamond | 94.2% | — | — |
| 响应速度 | 20-30 tokens/秒 | 20-30 tokens/秒 | 40-60 tokens/秒 |
| Thinking effort 档位 | low / medium / high / xhigh / max | low / medium / high / max | low / medium / high / max |
| 视觉分辨率 | 增强 | 标准 | 标准 |
| 发布时间 | 2026-04-16 | 2026-02-05 | 2026-02-17 |
价格部分有两个细节值得停一下。
第一,Opus 4.7 和 Opus 4.6 价格完全一样。Anthropic 这次升级没涨价,所以站在 Opus 4.6 用户角度,没有”要不要升”的纠结,直接换。
第二,Sonnet 4.6 的输入价格是 Opus 4.7 的 60%,输出价格也是 60%。同样的工作量切到 Opus 4.7,账单会涨大约 67%(按 1:5 的输入输出比折算)。这不是”贵一点”,是接近七成的差距,必须有等价的性能回报才值。
SWE-bench 8 个百分点意味着什么
SWE-bench Verified 是 Anthropic 跟 OpenAI 都在公开数据里用的编程能力基准,500 道经过人工筛查的真实 GitHub issue。Opus 4.7 拿 87.6%,Sonnet 4.6 拿 79.6%,相差 8 个百分点。
这个 8 个百分点不是均匀分布在所有任务上的。Anthropic 在发布博客里提到 Opus 4.7 在某些”Opus 4.6 和 Sonnet 4.6 都解不出来”的题目上突破了——也就是说,差距集中在最难的那部分题目。
落到实际开发场景,对应的差异是:
- 单文件、单功能、明确需求的题目,Sonnet 4.6 已经足够,两个模型的结果几乎没差
- 跨多个文件、需要理解模块边界、有架构权衡的题目,Opus 4.7 通过率明显更高
- 模糊需求下的”猜意图”能力,Opus 4.7 更准——你写得潦草点也能干活
简单说:Sonnet 4.6 是”你说清楚,我能干好”;Opus 4.7 是”你说一半,我能补上”。
如果你的工作流是写详细的 PRD 喂模型,差距会被你压缩;如果你习惯一句话甩需求让 AI 自己理解上下文,Opus 4.7 的 ROI 高得多。
视觉理解升级:一个容易被忽略的变化
Opus 4.7 的视觉部分提升不只是 benchmark 数字,是分辨率层面的实际能力。
Anthropic 说”can see images in greater resolution”——之前 Opus 4.6 处理高分辨率截图、UI 设计稿、密集图表的时候,会因为下采样丢失细节。Opus 4.7 保留更多原始像素,对截图分析、图表 OCR、UI 自动化测试这类任务有实际影响。
哪类场景会用到:
- 浏览器自动化的截图分析(点击位置、表单填写)
- 设计稿到代码的还原任务(Figma 截图、Photoshop 导出)
- 论文 / 财报里的密集表格 + 公式提取
- 监控仪表盘截图的异常检测
如果你的应用是纯文本对话,这个升级感受不到。如果有图像输入,建议直接测一下——Anthropic 的视觉分越来越是模型区分度的关键。
xhigh:thinking effort 的新档位
Opus 4.7 在原本的 low / medium / high / max 之间多了一档 xhigh。
四档变五档看似小动作,实际是 Anthropic 承认了一个事实:max 经常太贵太慢、high 又解不出最难的题。xhigh 卡在中间,针对”我知道这道题难,但又不想为 max 付那么多 token”的场景。
用法上没什么花活:在卡 high 又不想直接拉满 max 的题目上设 xhigh,让模型多想一会儿。如果你写 Agent,建议把 thinking effort 做成阶梯——简单步骤用 medium,遇到 “model couldn’t solve” 的回退路径升 high,再失败升 xhigh,最后才 max。每升一档延迟和 token 都涨,按需求和成本动态切换比一刀切 max 划算得多。
Sonnet 4.6 目前还是四档(low / medium / high / max),没有 xhigh 这一档。
速度差异:被低估的成本项
Sonnet 4.6 的输出速度大约是 Opus 4.7 的两倍。这件事在 benchmark 表格里不显眼,但在交互式产品里是用户体验的硬约束。
举一个具体场景:在 IDE 里让 AI 改一段 200 行代码,Opus 4.7 大概等 25 秒出完,Sonnet 4.6 大概 12 秒。这 13 秒的差,开发者每天会经历几十次,累积起来一天多等十几分钟。
对延迟敏感的产品要把速度也算进选型成本:
- 实时对话(客服、教学、陪伴)→ Sonnet 4.6
- 代码补全的内联建议 → Sonnet 4.6
- 后台批处理(夜间跑、不阻塞用户)→ Opus 4.7 性价比更好
- Agent 长任务(用户启动后去喝咖啡)→ Opus 4.7 完全不亏
一笔算清楚的账:什么时候升级 Opus 4.7
下面这张矩阵直接告诉你怎么决定。
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 日常代码补全、bug 修复 | Sonnet 4.6 | 差距小,速度差 2 倍,账单省 67% |
| 跨 10+ 文件的重构 | Opus 4.7 | 长上下文一致性,SWE-bench 8 分差距集中体现 |
| 单步骤工具调用 | Sonnet 4.6 | 推理深度足够,速度优势明显 |
| 10+ 步 Agent 工作流 | Opus 4.7 | 多步骤推理稳定性差距明显 |
| 翻译 / 摘要 / 分类 | Sonnet 4.6(或 Haiku 4.5) | 推理深度过剩,纯浪费钱 |
| 设计稿到代码 | Opus 4.7 | 视觉分辨率升级直接受益 |
| 长文档分析(<100K token) | Sonnet 4.6 | 表现相当,省钱 |
| 长文档分析(100K+ token) | Opus 4.7 | 长上下文细节召回更准 |
| 实时客服 / 对话 | Sonnet 4.6 | 用户在等,速度优先 |
| 已经在用 Opus 4.6 | Opus 4.7 | 同价,无脑升 |
一句话总结:把 Opus 4.7 当作”硬任务专用刀”,把 Sonnet 4.6 当作”日常生产力工具”。混着用,按场景路由模型——这是大多数生产环境里最经济的方案。
实战路由策略
直接在代码里做模型路由,按任务难度切模型,比单押 Opus 省一大笔账单。
一个常见的双模型路由模式:
import anthropic
client = anthropic.Anthropic(
base_url="https://api.ofox.ai/anthropic",
api_key="<YOUR_OFOX_KEY>"
)
def route_model(task_complexity: str, has_images: bool) -> str:
if has_images and task_complexity == "high":
return "claude-opus-4-7"
if task_complexity == "high":
return "claude-opus-4-7"
return "claude-sonnet-4-6"
response = client.messages.create(
model=route_model("medium", has_images=False),
max_tokens=4096,
messages=[{"role": "user", "content": "你的问题"}]
)任务复杂度的判断可以用一个小模型先打分(Haiku 4.5 或本地小模型),然后再决定走哪个 Claude。如果你想再省一点,把简单任务直接交给 Haiku 4.5——三档路由,进一步压缩成本。
关于 Prompt Caching 的提醒
无论选哪个,开 Prompt Caching 都能再砍一大笔。
OfoxAI 的 Anthropic 原生协议支持完整的 Prompt Caching。系统提示词、长上下文 RAG、固定的 few-shot 例子都可以缓存——缓存命中后的费率只有原价的 10% 左右。对长系统提示词 + 高频调用的场景,能省一半以上。
代码层面只需要在 system 字段加 cache_control,剩下交给协议:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "<你的长系统提示词,几千到几万 token>",
"cache_control": {"type": "ephemeral"}
}
],
messages=[{"role": "user", "content": "用户问题"}]
)关于具体的批量和缓存技术细节,可以参考 Claude API streaming 和批量调用 这篇里更完整的说明。
国内同时调两个模型
Anthropic 的 API 国内没有直接访问通道。通过 OfoxAI 可以同时调 Opus 4.7 和 Sonnet 4.6,模型切换只需要改 model 参数。
Base URL 两种选:
- Anthropic 原生协议:
https://api.ofox.ai/anthropic,对应 SDK 完整功能(Prompt Caching、扩展思考、视觉) - OpenAI 兼容协议:
https://api.ofox.ai/v1,迁移成本最低,把现有 OpenAI SDK 的 base_url 改一下即可
定价跟 Anthropic 官方完全一致,支持微信和支付宝充值。如果你想看完整的接入步骤,Claude API 国内付费指南 里有从注册到首次调用的全流程。
升级前的两个验证
别凭这篇文章直接做决定。在切换前花 20 分钟做这两件事:
第一,拿你过去一周用得最多的 5 个 prompt,分别让 Sonnet 4.6 和 Opus 4.7 各跑一遍,比对输出。差距小过你的容忍度,省钱继续用 Sonnet;差距足够明显才考虑升级。
第二,估算月账单。从 OfoxAI 控制台导一份过去 30 天的 token 用量,按照 67% 涨幅算下来。如果你的预算能吃下这个涨幅,再决定要不要升。
升级 Opus 4.6 到 Opus 4.7 是另一种情况——同价、性能净涨,不需要纠结,直接换。
同系列阅读
如果你还在做更细的横向决策,下面三篇能帮上忙:
- Claude Opus 4.6 vs Sonnet 4.6 怎么选:上一代选型逻辑,对照看升级账更清楚
- Claude Opus 4.7 完全指南:Opus 4.7 自身的能力、接入和价格细节
- Claude Code 国内使用 + Opus 编程体验:把 Opus 用在 Claude Code 里的实际体感
- Claude API 报错排查(429 / 401 / 529):升级模型后遇到限流和报错的排查路径