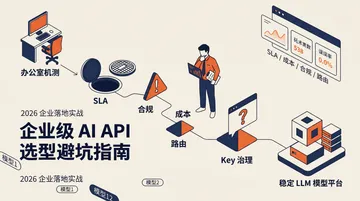
企业大模型API接入,4大误区与避坑指南(大厂内部最佳实践)
一家企业的线上服务在 93 分钟里悄悄发出 276 次失败请求,全程没人察觉。模型每月被新版本刷新,但企业 AI 项目挂掉的原因从来不是模型——是账单失控、调用挂掉、合规审不过、客户追责答不上。无论是 5 人小队还是百人工程团队,这 4 个痛点和 6 步落地清单都是同一套底座。
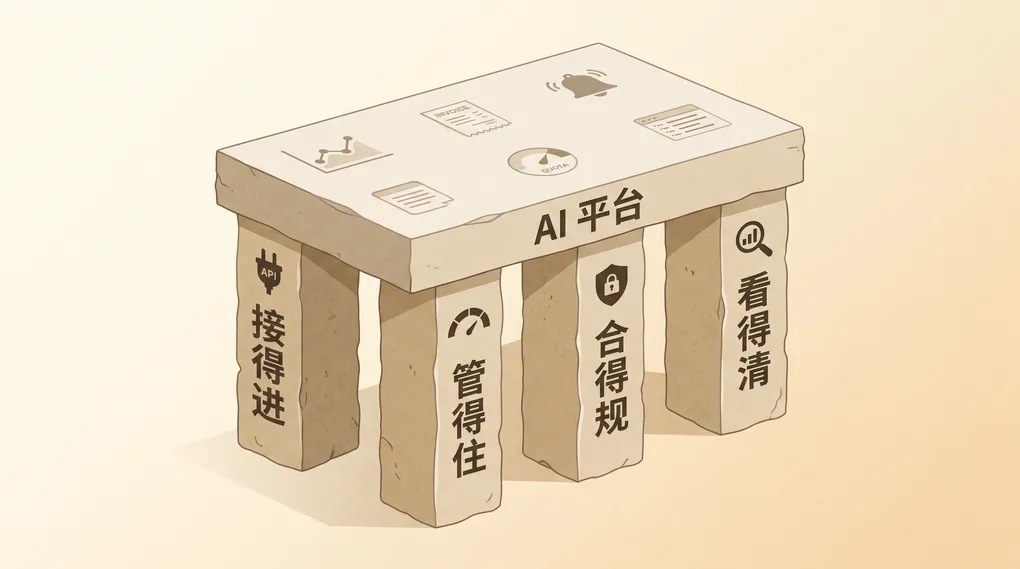
一家企业用户的线上服务,在 93 分钟里发出了 276 次失败请求。开发同学把 max_tokens 写成了 30000,超过模型上限,每次都被拒、立刻重试,循环了一个半小时。全程没有一个人知道。
这次的运气在:参数错误是 HTTP 400,请求在推理前就被拒,主流厂商不计费,账单是零。运气不好的版本下一节就讲——同样的死循环写法换成”每次都成功返回”,48 小时就能烧到 $260K。没人在看才是事故本体,账单只是事后才有的回执。
这不是个例。它几乎是每家把大模型接进生产的企业,头半年都会以不同形式撞上的坑。可能是参数写错、可能是 Key 被盗、可能是某个 agent 凌晨四点开始死循环,但症状都一样:没人在看,烧满才被发现。
模型谁强谁弱是动态的——这个月 Opus 4.8 领先编码,下个月 MiniMax M3 用 1/10 价格追平;上半年 GPT-5.4 拿编码冠军,下半年 Claude Fable 5 在评测里反超。这种排名每隔几个月就会翻一次。但企业要的从来不是某个模型,是稳定底座——接得进、管得住、合得规、看得清。
底座搭好了,换模型才只是改一个参数的事。底座没搭好,开头那 93 分钟 276 次的事故会用各种姿势复发。
一张表看完:4 个痛点 × 真实代价 × 对应解法
| 痛点 | 真实代价 | 对应底座能力 | 一句话 |
|---|---|---|---|
| 接入碎、成本藏在账单外 | 工程师耗在接入、财务对 4 张账单 | 接得进 统一接入 | 接 4 家变配 1 把 Key |
| 调用裸奔、参数写错或循环失控 | 93 分钟 276 次、循环跑完才被人发现 | 管得住 成本管控 | 异常熔断在网关层,不是事后复盘 |
| 数据留存不明、采购要自带 Key | 卡在法务/采购,上不了线 | 合得规 安全合规 | 数据留存策略写进合同 + 企业版可谈私有部署 |
| 出问题答不出原因 | 信任流失、只能人工 grep | 看得清 可观测与路由 | 每条请求说得清、算得明 |
下面四节分别拆。每节先讲企业的真实状态和代价,再讲落地姿态。
痛点一:接 AI 真正费时间的不是写代码,是注册、对账、维护 4 套配置
一个正经 AI 产品今天很难只用一家模型:代码用 Claude、对话用 GPT、多模态上 Gemini、批处理想试开源模型。于是要:
- 注册 3 到 4 个平台、每个过企业实名
- 分别充值、分别对账、分别开票(财务每月对 4 张账单)
- 对接 4 套不一样的鉴权、错误码、限流规则
团队内部更碎。Claude Code、Codex、Cursor 每个工具单独配 base_url 和 Key,新人配环境配半天,换个模型翻三个配置文件。
这部分成本不出现在账单上,但实实在在拖慢交付。工程师的时间耗在”接入”而不是业务上。这个坑跨规模都踩:8 人初创团队为了维护”哪个工程师用哪把 Key 走哪个供应商”的表格每周耗掉半天;50+ 工程师的研发部门则要再叠一层多团队配额分摊,权限/审计/对账每月吃掉一个全职 SRE。规模越大,问题不是消失,而是换成更贵的形式复发。
解法:一把 Key 通管多家模型,财务只对一张账单
聚合层做三件事就够:
- 协议层兼容。ofox 这类聚合平台同时兼容 OpenAI、Anthropic 原生、Gemini 三种协议(Anthropic 协议、OpenAI 协议、Gemini 协议),换模型不改一行代码。
- 一把 Key 挂多家。一个账号、一份账单、一张发票,财务不再对四家。
- 桌面端一键绑定。Claude Code、Codex、Cursor 这些工具的 Key 配置统一走 cc-switch 等桌面切换器(cc-switch 完整教程),切模型不再碰配置文件。
直击文案:把”接 4 家模型”变成”配 1 把 Key”。工程师不用再为接入折腾,回去写业务。
具体到 ofox:当前模型广场覆盖近 100 个上游模型,Anthropic、OpenAI、Google、DeepSeek、Qwen、Kimi、MiniMax、智谱 GLM 等主流家族都有,一份 Key 通管。从 5 人小队的个人 Key、到 50+ 工程团队按子账号拆配额、再到上百人组织按部门/项目分账,同一套接入逻辑跑得通——规模上去了不用换底座,只是把 Key 治理拉一档。
痛点二:一行写错的参数,能在没人看的几小时里悄悄烧光一个月预算
大多数企业的 AI 调用是”裸奔”的:
- 没有额度墙
- 没有熔断
- 没有告警
往上没额度上限。一个写错的循环、一次忘关的压测、一把被盗的 Key,几小时能烧掉一个月预算。往下没异常感知。等你发现,要么是账单,要么是客户投诉。
开头那个 93 分钟 276 次的事故,本质就是裸奔——没人拦,循环一个半小时才被人工翻日志发现。这次因为参数错误(HTTP 400)请求在推理前就被拒,账单是零;但同样的死循环写法换成”每次都成功返回”,账单就不是零,而是直接顶到上限:开发把 for i in range(3000): client.chat.completions.create(...) 误提交到生产配置,每次请求成功,单价 $0.03,3000 次 = $90,看着不大,但如果 cron 每分钟跑一次,48 小时累计就是 $260K。
解法:每把 Key 设硬性额度墙 + 异常检测 + 费用排序
成本控制的事不能靠”事后看账单”。日报粒度的对账面对 AI 调用是失效的——AWS EC2 飞一晚上明早能看到,AI API 是毫秒级 token 结算,等账单同步到 BI 系统已经是第二天。所以必须前置到网关层做三件事:
- 多级额度。团队、每个成员、每一把 Key 都能单设日额、月额、总额和每分钟请求上限,超了直接拦,不是扣完才说。具体怎么拆账、怎么发虚拟 Key,参考企业 AI API 成本治理实战。
- 异常检测。对”参数写错狂刷”这类模式做检测(同一 Key 短时间内大量同型号错误、token 量陡增、错误率超阈值),自动冻结 Key 并通知本人。这块多数平台还不开箱,但 LiteLLM、Portkey 都有 hook 可以接,自己写 50 行也能做。
- 成本可见。哪个团队、哪把 Key、哪个模型在烧钱,按用量和费用排序一眼看到。ofox 控制台支持按 Key、模型、用户维度筛选用量、费用和请求数;按 Key 维度的统计是开箱的。
直击文案:同样的事故,在做了网关层的环境里不是 93 分钟后被人发现,而是第几次就被自动掐断。
完整的 8 个降本杠杆(缓存、模型分层、流式批处理、智能路由等等)可以参考降低 AI API 成本指南和多模型路由成本优化。
痛点三:法务和采购的两个问题答不上,AI 项目就上不了线
企业级和个人级最大的分水岭,往往不是性能,是这两个问题答不答得上:
- “我们调 AI 的对话内容,存在哪?谁能看到?”
- “采购要求必须用公司和 OpenAI 签的企业合同 Key,你们支持吗?”
很多中转或聚合服务默认记录请求和响应正文用于”优化服务”。过法务评审时这是红线,不会让过。
这两点不解决,AI 项目很可能在法务和采购那一关就过不去,技术做得再好也上不了线。我见过一个金融团队,工程侧 POC 已经跑了三周,结果法务一句”日志里到底存不存对话内容”打回了,又花了两个月谈替代方案。
解法:数据留存、自带 Key、部署形态三件事都写进合同
这一节的”卖点”侧不能瞎承诺,因为不同平台口径差异极大,且必须以最终签的服务条款为准。但企业采购方该问的三件事是固定的:
- 数据留存策略。请求和响应正文是否记录、保留几天、能否申请关闭、是否可以单独签 ZDR(Zero Data Retention)附约。这要白纸黑字。
- BYOK(Bring Your Own Key)。能否接入企业自己的 OpenAI、Anthropic、Google 企业 Key,合同、发票、合规口径全归企业自己,平台只做路由和审计。多数聚合平台在 Enterprise 套餐里能谈。
- 部署形态。SaaS、私有云、混合云、纯自托管,每一档的可用性和价格曲线都不一样。监管严的行业(金融、医疗、政务)通常要求私有或混合云,标准 SaaS 套餐不够用。
ofox 公开承诺 99.99% Uptime,按月消费阶梯(Bronze → Platinum)提供 3-7% 返点和分级技术支持,高额档位用户可获 dedicated technical contact 与优先工单。SSO/SAML、私有或混合云部署、BYOK 和 ZDR 这类合规细节,公开页没有标准条款,不是开箱 self-serve 功能,能不能落到合同里需要走销售渠道单独确认。
直击文案:法务问”数据存哪”,你能把条款拿出来对;采购问”能用我们自己的合同 Key 吗”,你能拿出 BYOK 方案的细则。
上量后的 10 个合规和稳定性陷阱(包括”99.99% SLA 怎么读”、“子账号和 Key 治理”),有更全的清单:企业级 AI API 选型避坑指南。
痛点四:客户问”为什么这次这么慢”,你打开后台只能靠人工 grep
线上 AI 服务跑久了一定遇到追问:
- 某次响应变慢
- 某天账单偏高
- 某接口间歇报错
客户要说法,你打开后台只有一堆原始日志,靠人工 grep 和猜。
答不出来就是信任流失;故障只能”事后复盘”,无法”实时拦截”。SLO 不是 PPT 上画的数字,是每一次 incident 之后客户问的那句”上次那个问题修了吗”。
解法:每条请求都能查到来龙去脉 + 上游挂了自动切下一家
可观测层的能力直接决定故障定位时间。ofox 控制台目前支持按以下维度筛选请求数据:
- 调用方 Key、模型、上游供应商
- 输入/输出 token 用量
- 费用合计、按 Key/模型分摊
- HTTP 状态码、延迟分布
- 缓存命中情况(如果开了 prompt caching)
这是基础。再往上叠两件事:
- 主动告警。实时盯 RPS、P95/P99 延迟、错误率,越阈值直接推飞书或 Slack,不等人巡查。这块多数聚合平台还不开箱告警通道,需要自己接 webhook 或者用 LiteLLM、Portkey 的告警模块。系统化的 SLO 设计参考企业级 AI API 可观测性与 SLO。
- 按供应商健康自动路由。某家上游抖了自动切下一家,用户端无感。ofox 的 provider routing 和 fallback 两份文档说得清,简单说就是给 model ID 配一个 fallback 列表,主供应商 5xx 或超时就自动换。这条线和故障演练一起做,落地姿态参考企业 AI API 混沌演练与 failover。
直击文案:客户问”这次为什么慢”,你不用人工 grep——按 Key/模型/时段筛一下,数据就说话了。
按这个顺序补:6 个动作,从今天就能开始动手
如果你团队还在裸奔阶段,按下面顺序补:
| 优先级 | 动作 | 验收信号 |
|---|---|---|
| P0 | 把所有模型调用收敛到一把 Key,走聚合平台 | 工程师不再维护”哪把 Key 走哪家”的表格 |
| P0 | 每一把 Key 都设硬性日额上限 | 写错参数能在 5 分钟内被拦截 |
| P1 | 请求日志接入观察台,按 Key/模型维度排序 | 客户问”上次为什么慢”能在 2 分钟内答上 |
| P1 | 主链路配 fallback,至少 1 主 1 备 | 主供应商 5xx 时业务无感 |
| P2 | 数据留存策略和 BYOK 写进商务合同 | 法务和采购评审一次过 |
| P2 | 主动告警接到飞书/Slack | P95 延迟越线 1 分钟内推到群里 |
P0 是底线,P1 是上量门槛,P2 是上市/出海/接金融政务客户的门槛。
结语:模型每月被刷新,但企业要的这 4 件事是稳定的
这四个痛点有个共同点:它们都不在 POC 阶段暴露。跑 demo 时大家比模型聪不聪明、快不快;一旦真上生产、接多个团队、面对客户和法务,决定项目能不能活下去的是另外四件事——接得进、管得住、合得规、看得清。
模型每隔几个月被刷新一轮,谁强谁弱是动态的。但企业要的这套底座是稳定的刚需。先把底座搭好,换模型才只是改一个参数的事。
一句话行动:如果你团队此刻还在 4 个平台之间切 Key,今天就把所有调用收敛到一把走 ofox.ai。新账号首充享 ofox 折扣价,控制台支持按 Key 设额度、按 Key/模型/用户维度筛费用——P0 两项当天就能落到位。