LLM API Cache Hit Math: Why Your DeepSeek Bill Says $4 But the Pricing Says $50
The official DeepSeek V4 Flash price is $0.14 per million input tokens. The bill on a real coding workload is closer to $0.005. The 28x gap is cache hit math, and almost nobody calculates it correctly. Here is the worked math across DeepSeek, Claude, and OpenAI in 2026.
TL;DR: Real LLM bills run 3 to 50 times lower than the headline per-million-token price because most input tokens come from cache. DeepSeek’s deepseek-v4-flash cache read is $0.0028 per million versus $0.14 cache miss — a 50x discount. Claude Opus 4.6 cache read is $0.50 per million versus $5.00 input. OpenAI GPT-5.5 cached input is $0.50 versus $5.00 cache miss. If you’re paying full price, you’re either streaming a moving target into your prompt prefix or your hit rate audit is wrong.
The 90% Discount Nobody Calculates Correctly
Open any LLM pricing page in May 2026 and the headline number is the cache miss price, not the price you actually pay. If your prompt has a timestamp anywhere near the top, your cache hit rate is zero and you’re paying the cache-write tax for nothing.
This is the gap behind every confused Slack thread that starts with “we’re spending $4 a day, the calculator said $50, what’s going on?” Pricing pages quote miss prices. Real workloads are mostly hits. The arithmetic is straightforward once you put the numbers in one table, but providers don’t, because the big number is what drives sticker shock and the small number is what drives migration intent.
The Three Pricing Models Compared (May 2026)
There are exactly three ways the major providers price prompt caching today. They look similar on a slide and are very different on a bill.
DeepSeek — Disk caching, automatic, no write premium
| Model | Cache hit input | Cache miss input | Output | Hit / miss ratio |
|---|---|---|---|---|
| deepseek-v4-flash | $0.0028 / M | $0.14 / M | $0.28 / M | 50x cheaper |
| deepseek-v4-pro (list) | $0.0145 / M | $1.74 / M | $3.48 / M | ~120x cheaper |
| deepseek-v4-pro (75% off promo, through May 31 2026) | $0.003625 / M | $0.435 / M | $0.87 / M | ~120x cheaper |
DeepSeek introduced disk-based context caching in mid-2024 and the V4 generation made the cache discount dramatic — Flash cache reads are 50x cheaper than misses. Prices above are the standard rates from the official pricing page. There is no separate “cache write” line item; first-time tokens bill at miss price and identical prefixes on later requests bill at hit price. Note: the legacy aliases deepseek-chat and deepseek-reasoner are scheduled for deprecation on 2026-07-24 and route to V4 Flash today; use the V4 model IDs for new integrations.
Anthropic — Explicit cache_control blocks, write premium, two TTLs
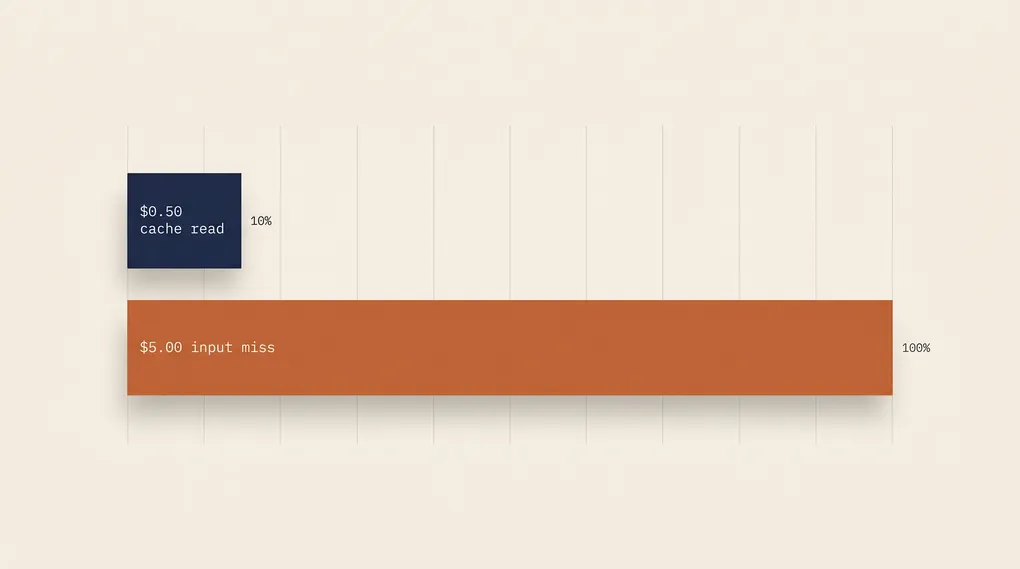
For Claude Opus 4.6 (base input $5 per million):
| Operation | Multiplier | Rate |
|---|---|---|
| Base input | 1x | $5.00 / M |
| 5-minute cache write | 1.25x | $6.25 / M |
| 1-hour cache write | 2x | $10.00 / M |
| Cache read | 0.1x | $0.50 / M |
These are the exact multipliers documented in Anthropic’s prompt caching docs. Minimum cacheable block is 2,048 tokens for Sonnet 4.6 and 4,096 tokens for Opus 4.6.
The 5-minute TTL silently became the default in early 2026, replacing the previous 1-hour default. A widely-cited Dev Community analysis reported that the change inflated effective costs 30 to 60 percent for production workloads that depended on the 1-hour cache surviving across slow human turns.
OpenAI — Automatic, free to write, ~10x discount
OpenAI documents prompt caching as automatic on prompts of 1,024 tokens or longer, with no code change and no write premium. For GPT-5.5, the 2026 API pricing page lists $5.00 per million for cache-miss input and $0.50 per million for cached. Flat 10x discount, no math required.
The Three Workflows That Get Billed Three Different Ways
The same model running the same total token volume can produce wildly different bills depending on what your traffic shape looks like. These are the three recurring patterns.
Workflow A — Long stable system prompt, many short user turns (RAG, support bot)
Imagine a customer-support bot with a 5,000-token system prompt and policy reference, plus a 200-token user question and 300-token answer per request, doing 10,000 requests per day on Claude Sonnet 4.6 ($3 input / $15 output base, $0.30 cache read).
Without caching: 5,200 input × 10,000 = 52M tokens × $3 = $156/day input With caching, after the first 12 requests the system prompt is hot: 5,000 × 10,000 = 50M cached at $0.30 = $15, plus 200 × 10,000 = 2M fresh at $3 = $6, plus a handful of write premiums. Total ~$21/day input.
An 86 percent input-cost cut on a workload you weren’t planning to refactor. This is why serious RAG deployments treat cache hit rate as a top-line metric. Du’An Lightfoot’s writeup tracks the same pattern from the other direction: $720 down to $72 monthly on Anthropic, no other changes.
Workflow B — Iterative coding session (Claude Code, Cursor)
In a coding agent the system prompt, tool definitions, and the read-back of recently opened files dominate the input. Each turn appends a few hundred tokens of new tool output. A real audit of 100.9M tokens through Claude Code reported an 84 percent cache hit rate, with 84.2M of 100.3M input tokens served from cache (BSWEN). Anthropic’s own engineering team wrote in April 2026 that they declare an internal SEV when cache hit rate drops, because the entire $20/month Claude Code Pro economics depends on it.
An r/DeepSeek user posted a real bill: 88.9M input tokens at a 98.07 percent cache hit rate on deepseek-v4-flash, billed at $0.642 (input + output combined). Pencil it out and 87M of those input tokens were $0.0028/M reads ($0.24), only 1.7M were $0.14/M misses ($0.24), with the rest going to output. The math only looks insane until you notice the prefix never moved.
Workflow C — Parallel batch document processing (the trap)
This is the workflow that produces the surprised Slack message. A team has 1,000 documents to summarize, each with the same 8,000-token instruction header. They naively fire all 1,000 in parallel.
Cache writes take 2 to 4 seconds for large prefixes. Before the first write completes, the next 50 requests have already arrived — all of them misses. The result is described well in an analysis by AI Transfer Lab: “10 cache writes, 0 cache reads, and a bill 5–10x what you expected.” The fix is to send a single warm-up call first, wait for the cache to land, then unleash parallelism.
Hidden Costs That Surprise People
Reading the docs once is not enough. These are the four leaks that trip up production deployments, in rough order of frequency.
1. Timestamps and UUIDs near the top of the prompt. This is the single most common bug. The top-voted comment on the Hacker News thread on prompt caching (306 points, user duggan) is verbatim: “It was a real facepalm moment when I realised we were busting the cache on every request by including date time near the top of the main prompt.” Moving timestamps to the user message instead of the system prompt took their cached ratio from 30–50 percent to 50–70 percent.
2. Cache writes are billed even when nothing reads them. On Anthropic, a one-shot batch job that never repeats the same prefix pays the 1.25x write premium on every request and gets nothing back. Caching is a loss in that workload. The break-even on Anthropic’s 5-minute cache is one read; on the 1-hour cache it is two reads.
3. Anthropic’s TTL silently dropped to 5 minutes. A still-open GitHub issue tracks the regression. If your interactive workflow has 10-minute pauses (you’re reading code, getting coffee), every resume eats a fresh write premium.
4. Parallel fan-out before the first write lands. Discussed above under Workflow C. The fix is a sequential warm-up call, not changing your concurrency model.
How to Actually Measure Your Cache Hit Rate
All three providers expose cache token counts in the response object. Stop trusting the dashboard summaries and read them yourself.
# OpenAI / OpenAI-compatible (works on ofox.ai too)
resp = client.chat.completions.create(model="openai/gpt-5.5", messages=[...])
cached = resp.usage.prompt_tokens_details.cached_tokens
total_in = resp.usage.prompt_tokens
hit_rate = cached / total_in if total_in else 0
# Anthropic
resp = client.messages.create(model="claude-opus-4-6", ...)
hit = resp.usage.cache_read_input_tokens
write_5m = resp.usage.cache_creation_input_tokensAggregate across a day, plot a histogram, treat anything under 60 percent on a stable agent or RAG workload as a bug. The HN commenter weird-eye-issue flagged that a unique prefix-prompt_cache_key pair above 15 requests per minute can overflow the OpenAI cache. One more knob to watch if you partition heavily by user.
Per-Provider Quirks Worth Knowing
A short table of the things that catch people off-guard, none of which are on the pricing page:
| Provider | Quirk |
|---|---|
| Anthropic | Default TTL is 5 minutes since early 2026. Pay 2x for 1-hour TTL. Minimum cacheable block 2,048 tokens (Sonnet 4.6) / 4,096 (Opus 4.6). |
| DeepSeek | Cache is keyed on a 64-token prefix chunk. No write premium. Cached prices apply automatically. |
| OpenAI | Caching kicks in only for prompts ≥ 1,024 tokens. Free to write. Cache key is per organization, not per API key. |
| Gemini 3.1 Pro | Explicit cache requires a separate cachedContent resource and has a per-second storage fee. Different mental model entirely; budget separately. |
Bottom Line
The economics of running an LLM in production in 2026 are not what the pricing page suggests. A coding agent talking to deepseek-v4-flash at 95 percent cache hit rate runs at $0.0098 per million effective input tokens, not $0.14. A RAG pipeline on Claude Sonnet 4.6 with a stable system prompt runs at $0.30 per million effective input, not $3.00. The price card is the menu. The cache hit rate is the bill.
If you’re routing across multiple providers (say, fast iteration on DeepSeek, hard refactors on Opus), a single OpenAI-compatible endpoint like ofox.ai keeps the measurement code identical, since usage.prompt_tokens_details.cached_tokens is the same field on every model behind it. Tracking that one number across a week tells you more about your real spend than any pricing comparison.
Related reading on this site: Claude API Pricing Complete Breakdown, DeepSeek API Pricing Guide, Claude Code Hybrid Routing Pattern, Claude Code Token Optimization: 5 Strategies, How to Reduce AI API Costs, and AI API Aggregation: One Endpoint, Every Model.