Qwen 3.7 Max 完全ガイド:$2.50/$7.50・Code Arena 4位・Claude Opus比較
Qwen 3.7 Max はElo 1541でCode Arena WebDev 4位、Claude Opus 4.6 Thinkingと1ポイント差。料金はOpus 4.7の約1/3($2.50/$7.50 per 1M)。Terminal-Bench 69.7%、SWE-Pro 60.6%の実測値とハイブリッド運用戦略を解説。

TL;DR — アリババの Qwen 3.7 Max が 2026 年 5 月 19 日に商用 API として公開され、1 週間で Code Arena WebDev リーダーボードの 4 位に着地しました。Elo 1541 — Claude Opus 4.6 Thinking と 1 ポイント差、Sonnet 4.6 や Kimi K2.6 の上です。料金は $2.50/$7.50 per 1M トークン、Opus 4.7 のおよそ 1/3。クローズドウェイト、出力が冗長気味、という 2 点が実運用上の注意点。多くのチームには「日常コーディングを Qwen に流し、難しいケースだけ Opus にエスカレーション」というハイブリッド構成が現実的な落とし所です。
公開投票ベースのリーダーボードで Claude Opus 4.6 Thinking と Elo 差 1 ポイント、料金は 1/3。これがいま起きている「価格対性能フロンティア」の現実です。
なにがリリースされたか
アリババは 5 月 20 日杭州の Cloud Summit で Qwen 3.7 Max を発表しましたが、商用 API は 1 日先行して Model Studio(百錬)で 5 月 19 日にひっそり稼働を始めていました。仕様は 100 万トークンの長文コンテキスト、クローズドウェイトのフラッグシップ。Qwen 3.6 世代までは Apache 2.0 でオープンに公開されていた流れが、ここで明確に方針転換されています。3.7 系は当面 API 限定です。
注目すべきは仕様表ではなく、リーダーボードでの位置です。公開からわずか 1 週間で、Qwen 3.7 Max は Code Arena WebDev — フロントエンド & エージェント型コーディングの実戦タスクに人間が投票するボード — のトップ 4 に滑り込みました。
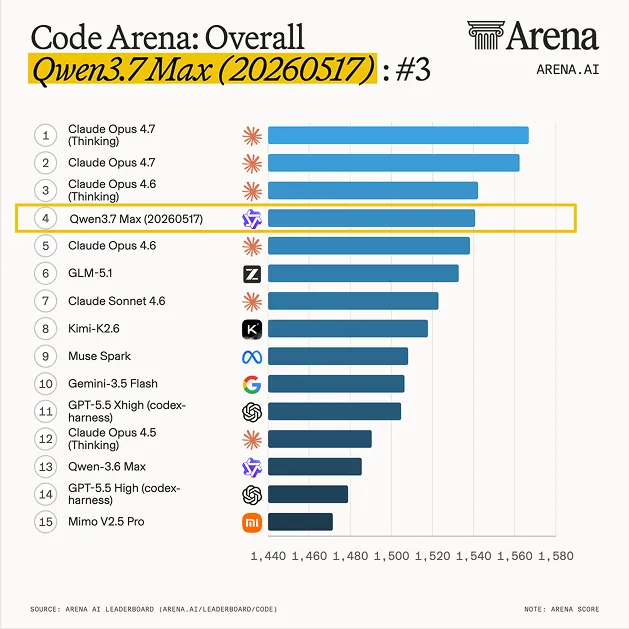
5 月 24 日時点の Code Arena WebDev スナップショット(328,594 票、81 モデル):
| 順位 | モデル | Elo | 価格(入力 / 出力 per 1M) | コンテキスト |
|---|---|---|---|---|
| 1 | claude-opus-4-7-thinking | 1567 | $5 / $25 | 1M |
| 2 | claude-opus-4-7 | 1562 | $5 / $25 | 1M |
| 3 | claude-opus-4-6-thinking | 1542 | $5 / $25 | 1M |
| 4 | qwen3.7-max-20260517 | 1541 | $2.50 / $7.50 | 1M |
| 5 | claude-opus-4-6 | 1538 | $5 / $25 | 1M |
| 6 | glm-5.1 | 1533 | $1.40 / $4.40 | 202.8K |
| 7 | claude-sonnet-4-6 | 1523 | $3 / $15 | 1M |
| 8 | kimi-k2.6 | 1518 | $0.95 / $4 | 262K |
リストには preliminary タグがついています。Qwen 3.7 Max の投票数 1,522 に対し Opus 4.6 は 8,889。Elo 信頼区間も ±16 で広め。ですが悲観側でも Opus 4.6(thinking なし)と肩を並べる位置で、価格はその半分。楽観側なら Opus 4.7 の背中に届きます。
35 時間ノンストップの自律最適化
リリース資料に静かに書かれていた話:アリババの自社カスタムチップ向けカーネル最適化タスクで、Qwen 3.7 Max を 35 時間連続稼働させ、1,158 回のツールコールを経て、対象ワークロードで幾何平均 10 倍の高速化を達成した、と。
「10 倍」という数字を額面どおりに受け取るかどうかは別として、エンジニアリング的に面白いのは「35 時間、1,000 回超のツール呼び出しを破綻なく回し切った」という事実です。多くの先端モデルは長尺の agent loop で、コンテキストが崩れる、目標を見失う、ツール呼び出しのフォーマットがズレてループが止まる、のどれかで脱落します。Qwen 3.7 Max はそこを耐え切った。
この能力に対応するベンチマーク:
| Benchmark | Qwen 3.7 Max | Claude Opus 4.6 | DeepSeek V4 Pro | Kimi K2.6 |
|---|---|---|---|---|
| Terminal-Bench 2.0 Terminus | 69.7 | 65.4 | 67.9 | 66.7 |
| SWE-Bench Pro | 60.6 | — | 59.0 | 59.5 |
| SWE-Bench Verified | 80.4 | 80.8 | 80.6 | — |
| MCP-Atlas | 76.4 | 75.8 | — | — |
| GPQA Diamond | 92.4 | 91.3 | 90.1 | — |
特に効いているのが Terminal-Bench 2.0 — サンドボックス端末で実際のソフトウェアエンジニアの作業を模す、5 時間タイムアウトのベンチマーク。Qwen 3.7 Max は 69.7 で Opus 4.6、DeepSeek V4 Pro、Kimi K2.6 をすべて上回りました(Opus 4.7 のみ Anthropic 報告で 77 と上)。SWE-Bench Verified は Opus 4.6 と 0.4 ポイント差で、統計的にはほぼ並走です。
第三者評価としては DataCamp のレビュー が同じ傾向を示しています。
価格計算
Claude Opus 4.7 は入力 $5、出力 $25(Anthropic 公式価格表)。Qwen 3.7 Max は Ofox で入力 $2.50、出力 $7.50、キャッシュヒット入力 $0.25 per 1M トークン。
コーディングエージェントでよくある 2:1 の入出力比でブレンドすると:
- Claude Opus 4.7: ($5 × 2 + $25 × 1) / 3 = $11.67 / M tokens
- Qwen 3.7 Max: ($2.50 × 2 + $7.50 × 1) / 3 = $4.17 / M tokens
Qwen は Opus の 36%。チームが現状 Opus に月 30 万円使っているなら、ルーティング層を入れて 80% を Qwen、難所の 20% を Opus に残す構成で、ブレンド月額はおおむね 14〜15 万円 — ほぼ半額に落ちる計算です。
正直な注意点:Qwen 3.7 Max は出力が冗長気味。DataCamp の長尺評価では中央値 2,400 万トークンに対し Qwen は 9,700 万トークンを生成しました — 約 4 倍。トークン単価のレートカードで線形に試算すると実請求額より低く出る可能性があります。プロンプトに「簡潔に」を明示する、もしくは 1 週間の実 traffic で A/B したうえで月次見込みを立てるのが安全です。
Ofox 経由での呼び出し
既存の OpenAI SDK のままで動きます。修正するのは 2 行:
from openai import OpenAI
client = OpenAI(
api_key="sk-of-...", # Ofox の API キー
base_url="https://api.ofox.ai/v1",
)
response = client.chat.completions.create(
model="bailian/qwen3.7-max",
messages=[
{"role": "user", "content": "この Python 関数を読みやすくリファクタしてください…"}
],
)同じキーで Claude Opus 4.7、GPT-5.5、Gemini 3.1 Pro も呼べるので、routing 層を 1 本化できます。モデル仕様・課金・キャッシュ条件は ofox.ai/ja/models/bailian/qwen3.7-max で確認できます。
日本の開発チームに関係する部分として、Ofox は日本円建ての請求書と適格請求書(インボイス)対応に標準対応しているため、経理・税務側の追加作業は基本的に発生しません。詳細は 日本企業向け AI ゲートウェイと JPY 請求書ガイド のほうにまとめています。
Opus 4.7 を残しておくべきケース
Qwen 3.7 Max は Opus 4.7 の全置き換えではありません。Opus を残したほうがよいケース:
- 30 分を超える長尺 agent タスク。Qwen の 35 時間自律実行はアリババが調整済みのベンチマーク条件下です。オープンエンドな顧客 agent ワークフローではまだ Opus 4.7 のほうが状態維持に強く、Code Arena 上の 21 Elo 差(1562 vs 1541)は長尺タスクで増幅されます。
- セキュリティレビュー、新規アルゴリズム設計、形式検証のような分布外推論。GPQA Diamond は 92.4 対 91.3 で僅差ですが、ベンチマーク外のタスクに踏み込むと Opus 4.7 の xhigh thinking モードのほうが伸びます。
- IDE 内のインタラクティブ補完のようなレイテンシ敏感ワークロード。Qwen は冗長気味 = 最初の有意義なトークンが出るまでが遅め。Cursor / Zed / Claude Code でタイピング感を保ちたい場面ではむしろ簡潔なモデルのほうが体感がよいです。
- 日本語の長文クリエイティブライティング。Qwen の日本語は十分使えますが、文学的なトーンや小説執筆の細やかな調整は Opus 系のほうがまだ得意です。
実運用上の落とし所はハイブリッドルーティング — Qwen 3.7 Max を主力に、Opus 4.7 を escalation に。Claude Code vs Codex CLI vs Cursor vs DeepSeek TUI 比較 で、エディタ側からこの構成をどう仕込むかを具体的に書いています。
まとめ
率直に 3 点:
- コーディングモデルのトップ層は、もうアンソロピックの独占ではない。公開投票のリーダーボードで Opus Thinking との差が 1 Elo、料金は 1/3 — これは 2026 年中盤の景色を確実に変えた数字です。
- Qwen のクローズド化はアリババの戦略転換。3.6 はオープン、3.7 はクローズド。オンプレや fine-tuning が必要なら 3.6 系、純粋に能力天井を取るなら 3.7、と用途で分ければよい。
- 判断材料は読むより試すほうが早い。月の Opus 請求が 5 万円を超えるチームなら、同じプロンプト群を Qwen 3.7 Max と Opus 4.7 に並走させて 1 週間で合格率とコスト曲線の交点が見えます。
より広い俯瞰は Claude / GPT / Gemini フラッグシップ比較 と 日本企業向けクロスモデル ベンチマーク を併読すると、いま自社にどの組み合わせが効くか整理しやすいはずです。
関連記事
- Claude Opus 4.7 API レビュー — 4.6 からのアップグレード判断 — Qwen 3.7 Max がもっとも直接競合する Opus 系の最新世代
- Claude / GPT / Gemini フラッグシップ比較 2026 — 主要 3 社のいまの立ち位置
- 日本企業向け AI ゲートウェイと JPY 請求書ガイド — Ofox 経由で経理・税務側を回す方法
- Claude Code vs Codex CLI vs Cursor vs DeepSeek TUI — ハイブリッドルーティングを編集環境に仕込む
- 日本語 LLM ベンチマーク - Claude / GPT / Gemini 国内モデル比較 — 日本語タスクに絞った評価


