Qwen 3.7 Max: #4 в Code Arena, $2,50/1M токенов — треть цены Claude Opus
Qwen 3.7 Max занял 4 место в Code Arena WebDev (Elo 1541) — в 1 пункте от Claude Opus 4.6 Thinking. Цена $2,50/$7,50 за 1M токенов. Бенчмарки, сравнение с Opus и подключение через ofox.ai без VPN.

TL;DR. Alibaba выпустила Qwen 3.7 Max 19 мая 2026, и за неделю модель вышла на 4 место в Code Arena WebDev — Elo 1541, в одном пункте от Claude Opus 4.6 Thinking, выше всех неантропик-моделей в топе. Тариф $2,50/$7,50 за миллион токенов, то есть примерно треть от Opus 4.7. Минусы — закрытые веса и заметная многословность вывода. Рабочая схема: гибридная маршрутизация, повседневный кодинг на Qwen, тяжёлые задачи на Opus 4.7. Через ofox.ai всё это идёт с одним ключом, без VPN и зарубежных карт.
Когда модель из Китая отстаёт от Claude Opus 4.6 Thinking всего на 1 пункт Elo и стоит втрое дешевле — это уже не “конкурент”, это сдвиг ценового потолка по всему рынку коммерческих агентов кодинга.
Что именно выпустили
Alibaba официально представила Qwen 3.7 Max на саммите Cloud Summit в Ханчжоу 20 мая 2026, но коммерческое API на Model Studio тихо ушло в прод днём раньше — 19 мая. Спецификация: 1 миллион токенов контекста, закрытая модель — заметный разворот от линейки Qwen 3.6, которая до сих пор открыта под Apache 2.0. Линейка 3.7 — пока только API.
Интересное здесь не лист тех-параметров, а позиция в рейтинге. Через неделю после релиза Qwen 3.7 Max попадает в топ-4 Code Arena WebDev — категории, где люди голосуют за результаты моделей на реальных задачах фронтенда и агентного кодинга с multi-step рассуждениями и tool-use.
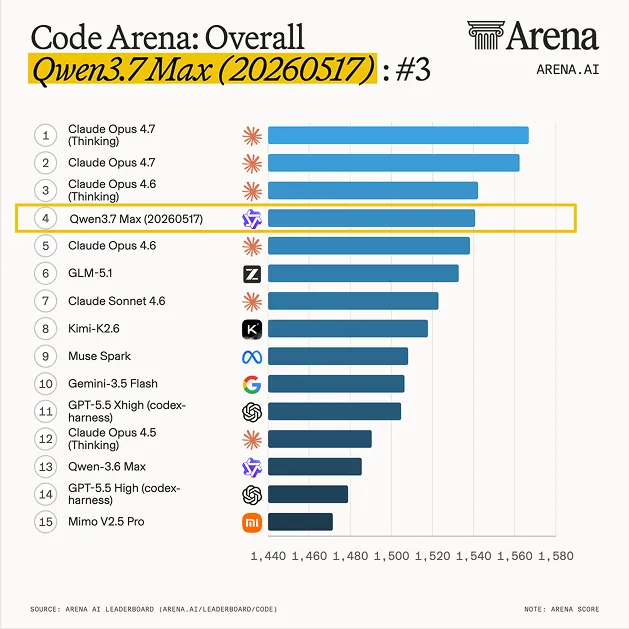
Снимок Code Arena WebDev на 24 мая (328 594 голосов, 81 модель):
| Ранг | Модель | Elo | Цена (вход / выход за 1M) | Контекст |
|---|---|---|---|---|
| 1 | claude-opus-4-7-thinking | 1567 | $5 / $25 | 1M |
| 2 | claude-opus-4-7 | 1562 | $5 / $25 | 1M |
| 3 | claude-opus-4-6-thinking | 1542 | $5 / $25 | 1M |
| 4 | qwen3.7-max-20260517 | 1541 | $2,50 / $7,50 | 1M |
| 5 | claude-opus-4-6 | 1538 | $5 / $25 | 1M |
| 6 | glm-5.1 | 1533 | $1,40 / $4,40 | 202,8K |
| 7 | claude-sonnet-4-6 | 1523 | $3 / $15 | 1M |
| 8 | kimi-k2.6 | 1518 | $0,95 / $4 | 262K |
Лист помечен как preliminary. У Qwen 3.7 Max пока 1 522 голоса против 8 889 у Opus 4.6, доверительный коридор ±16 Elo. Даже на пессимистичной нижней границе модель уже идёт вровень с обычным Opus 4.6 — при половинной цене. На оптимистичной — наступает Opus 4.7 на пятки.
35 часов автономной оптимизации
Деталь, спрятанная в материалах релиза: Qwen 3.7 Max непрерывно работал 35 часов над задачей оптимизации kernel под собственный кастомный чип Alibaba Cloud, сделал 1 158 tool-calls и, по отчёту, дал геометрическое среднее ускорение 10× на целевых workload.
Принимать “10×” на веру не обязательно. Инженерно важнее факт, что модель удержала контекст 35 часов и более тысячи вызовов инструментов без срыва — а это сценарий, на котором ломается большинство фронтирных моделей: либо рушится контекст, либо забывается цель, либо формат tool-call дрейфует и цикл умирает. Qwen 3.7 Max это выдержал.
Бенчмарки, которые подтверждают тот же тренд:
| Бенчмарк | Qwen 3.7 Max | Claude Opus 4.6 | DeepSeek V4 Pro | Kimi K2.6 |
|---|---|---|---|---|
| Terminal-Bench 2.0 Terminus | 69,7 | 65,4 | 67,9 | 66,7 |
| SWE-Bench Pro | 60,6 | — | 59,0 | 59,5 |
| SWE-Bench Verified | 80,4 | 80,8 | 80,6 | — |
| MCP-Atlas | 76,4 | 75,8 | — | — |
| GPQA Diamond | 92,4 | 91,3 | 90,1 | — |
Самый показательный — Terminal-Bench 2.0: симуляция реального инженера в sandbox-терминале с лимитом 5 часов. Qwen 3.7 Max выдаёт 69,7 — выше Opus 4.6, DeepSeek V4 Pro и Kimi K2.6. Опередил только Opus 4.7 (по отчёту Anthropic — 77). На SWE-Bench Verified отставание от Opus 4.6 — 0,4 пункта, статистически это паритет.
Независимая оценка от DataCamp показывает ту же картину со стороны.
Считаем деньги
Claude Opus 4.7: $5/M вход, $25/M выход (тарифы Anthropic). Qwen 3.7 Max на ofox: $2,50/M вход, $7,50/M выход, кэшированный вход — $0,25/M.
При типовом для кодинг-агентов соотношении 2:1 (много кода на вход, маленький патч на выход) усреднённая стоимость:
- Claude Opus 4.7: ($5 × 2 + $25 × 1) / 3 = $11,67/M tokens
- Qwen 3.7 Max: ($2,50 × 2 + $7,50 × 1) / 3 = $4,17/M tokens
Qwen стоит ≈ 36% от Opus. Команда, которая сегодня тратит 200 000 ₽/мес на Opus 4.7 на агентский кодинг, после маршрутизации 80% траффика на Qwen и оставшихся 20% сложных задач на Opus приходит к усреднённым 95 000–100 000 ₽/мес — примерно вдвое ниже исходного счёта.
Честная оговорка: Qwen 3.7 Max многословный. В длинной агентской оценке DataCamp модель сгенерировала 97 миллионов токенов при медиане в 24 миллиона по всем моделям — примерно в 4 раза больше. Если вы платите за токены и не задаёте в промпте “отвечай кратко”, фактический счёт окажется выше линейного расчёта по тарифу. Прежде чем мигрировать — A/B на неделю реального траффика, не на калькуляции.
Подключение через ofox
Если у вас уже стоит OpenAI SDK — миграция в две строки:
from openai import OpenAI
client = OpenAI(
api_key="sk-of-...", # ключ ofox
base_url="https://api.ofox.ai/v1",
)
response = client.chat.completions.create(
model="bailian/qwen3.7-max",
messages=[
{"role": "user", "content": "Отрефактори эту функцию на Python для читаемости..."}
],
)Тот же ключ открывает Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro — удобно для гибридной маршрутизации без перетряхивания auth-слоя. Подробности модели, цены и кэш — на странице ofox.ai/ru/models/bailian/qwen3.7-max.
Для российских разработчиков актуальный кусок: ofox оплачивается USDT и другими крипто-методами, российские карты не требуются, VPN не нужен. Подробнее логику доступа разобрали в Claude API в России — подключение Opus / Sonnet — для Qwen маршрут идентичный.
Где Opus 4.7 всё ещё оправдывает свою цену
Qwen 3.7 Max — не полная замена. Случаи, где премия за Opus продолжает работать:
- Агенские цикл-задачи длиннее 30 минут. 35-часовой автономный прогон Qwen реален, но был тюнингован под конкретный benchmark Alibaba. На открытых клиентских workflow Opus 4.7 удерживает состояние стабильнее — 21 Elo разрыва (1562 vs 1541) на Code Arena масштабируется на длинных цепочках.
- Security-review, новые алгоритмы, формальная верификация. GPQA Diamond 92,4 vs 91,3 — статистически близко, но за пределами benchmark-распределения (новые эксплойты, formal verification, архитектурная критика) xhigh thinking у Opus 4.7 даёт больше, чем подсказывает табличка.
- Latency-чувствительные сценарии в IDE. Многословность Qwen → дольше до первого полезного токена. В Cursor / Zed / Claude Code, где важна “скорость под пальцами”, лаконичная модель ощущается лучше.
- Русский литературный текст. Qwen прилично работает по-русски, но для художественного текста и тонкой стилистики Opus всё ещё уверенней.
Рабочая практика — гибрид: Qwen 3.7 Max на повседневный кодинг, Opus 4.7 на escalation. Как именно прошить такую маршрутизацию в IDE и CLI — в сравнении Cursor / Claude Code / Cline с custom API и в обзоре мульти-модельной стратегии оптимизации стоимости.
Вывод
Три важные мысли:
- Топ-уровень по кодингу больше не принадлежит только Anthropic. На публичном голосовательном рейтинге китайская модель идёт через 1 Elo от Opus Thinking при цене в 1/3. Это не маркетинг — это сдвиг ценовой границы.
- Закрытие весов Qwen 3.7 — стратегический поворот Alibaba. 3.6 ещё доступна под Apache 2.0, 3.7 — только API. Если нужен on-prem, fine-tuning и контроль данных, путь — Qwen 3.6 series. Если нужна вершина возможностей — Qwen 3.7 Max через API.
- Решение проще проверить, чем читать. Если ваш счёт на Opus сейчас от 50 000 ₽/мес — запустите тот же набор промптов параллельно на Qwen 3.7 Max и Opus 4.7. За неделю реального траффика станет видно, где у вашего workload пересекаются кривые качества и стоимости.
Контекст шире можно посмотреть в сравнении китайских моделей через российские шлюзы и в многомодельной стратегии оптимизации стоимости.
Связанное чтение
- Claude API в России — подключение Opus / Sonnet — основной конкурент Qwen 3.7 Max и как к нему получить доступ из РФ
- Китайские модели ИИ — Qwen / DeepSeek / MiniMax через API в России — где Qwen 3.7 Max стоит в семействе китайских моделей
- Мультимодельная стратегия оптимизации стоимости — как реально маршрутизировать траффик между Qwen и Claude
- Cursor / Claude Code / Cline — настройка custom API — как вписать Qwen 3.7 Max в редактор
- GPT-5.4 mini & nano — обзор бюджетных моделей для России — ещё один уровень “цена/качество” для сравнения


