Qwen3.7-Max 实测:Code Arena 第4、Elo 1541,价格是 Claude Opus 三分之一
Qwen3.7-Max 定价 $2.5/$7.5 per 1M tokens,Code Arena WebDev 榜单第4名,距 Claude Opus 4.6 Thinking 仅差1分。本文拆解真实跑分、vs Claude Opus 4.7横评,以及 80/20 混用策略与 API 接入方式。

TL;DR — 阿里 Qwen3.7-Max 5 月 19 日上线,一周内冲到 Code Arena WebDev 榜单第 4 名,Elo 1541,比 Claude Opus 4.6 Thinking 少 1 分、压在 Sonnet 4.6 和 Kimi K2.6 上头。价格 $2.5/$7.5(输入/输出 per 1M tokens),相当于 Opus 4.7 的三分之一左右。闭源、偏冗长是两个真实槽点。最实际的玩法:日常编码流量 80% 走 Qwen3.7-Max,剩下 20% 难题 escalate 到 Opus 4.7。
一个在公开投票榜单上跟 Claude Opus 4.6 Thinking 只差 1 个 Elo 点的国产模型,价格是它的三分之一——这才是 2026 年中国模型真正的拐点。
这次到底发布了什么
阿里在 5 月 20 日杭州云栖大会上正式介绍了 Qwen3.7-Max,但其实 5 月 19 日 API 就已经悄悄在百炼平台上线了。规格上是 100 万 token 上下文、闭源的旗舰模型——这点跟之前 Qwen 3.6(27B、35B-A3B 都还是 Apache 2.0)开源的路线明显分家了。3.7 这一代,至少近期,只走 API。
有意思的不是参数表,是榜单位置。上线一周不到,Qwen3.7-Max 就出现在了 Code Arena WebDev(前端 + agentic 编码任务)的前 4。
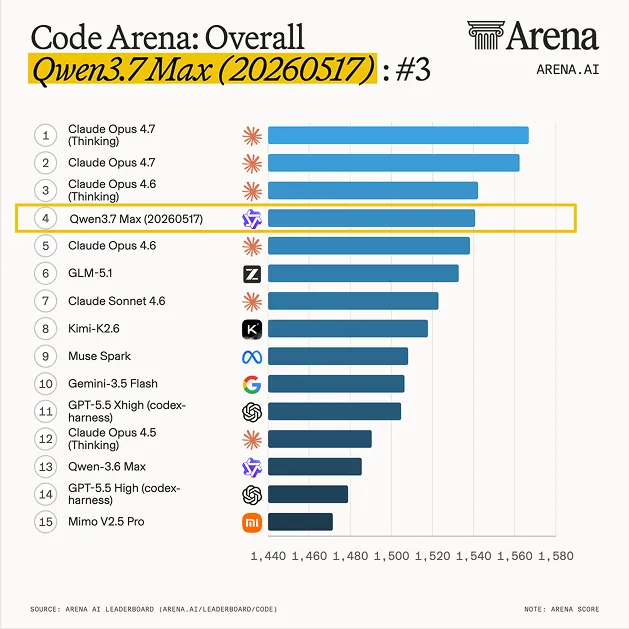
5 月 24 日 Code Arena WebDev 快照(328,594 票、81 个模型):
| 排名 | 模型 | Elo | 价格(输入/输出 per 1M) | 上下文 |
|---|---|---|---|---|
| 1 | claude-opus-4-7-thinking | 1567 | $5 / $25 | 1M |
| 2 | claude-opus-4-7 | 1562 | $5 / $25 | 1M |
| 3 | claude-opus-4-6-thinking | 1542 | $5 / $25 | 1M |
| 4 | qwen3.7-max-20260517 | 1541 | $2.5 / $7.5 | 1M |
| 5 | claude-opus-4-6 | 1538 | $5 / $25 | 1M |
| 6 | glm-5.1 | 1533 | $1.40 / $4.40 | 202.8K |
| 7 | claude-sonnet-4-6 | 1523 | $3 / $15 | 1M |
| 8 | kimi-k2.6 | 1518 | $0.95 / $4 | 262K |
榜单标了 Preliminary——Qwen3.7-Max 才 1522 票,Opus 4.6 已经 8889 票,置信区间还有 ±16 Elo。即便取保守下限,它也跟 Opus 4.6(不带 thinking)打平,价格只有一半;乐观上限,是直接咬住 Opus 4.7 后尾。
35 小时连续优化:硬实力的间接证据
发布资料里埋了一个细节:Qwen3.7-Max 在阿里自研芯片的 kernel 优化任务上,一次性跑了 35 小时、1158 次工具调用,几何平均加速 10 倍。
不管你信不信”10 倍”这个数字,工程上能撑住 35 小时单任务 agent loop、上千次 tool call 不跑偏,这件事本身就很硬——目前绝大多数前沿模型在这种长链路任务上要么 context 崩、要么忘了目标、要么 tool call 格式漂移让循环死掉。Qwen3.7-Max 没死,这是关键。
跟这个能力对应的硬指标:
| Benchmark | Qwen3.7-Max | Claude Opus 4.6 | DeepSeek V4 Pro | Kimi K2.6 |
|---|---|---|---|---|
| Terminal-Bench 2.0 Terminus | 69.7 | 65.4 | 67.9 | 66.7 |
| SWE-Bench Pro | 60.6 | — | 59.0 | 59.5 |
| SWE-Bench Verified | 80.4 | 80.8 | 80.6 | — |
| MCP-Atlas | 76.4 | 75.8 | — | — |
| GPQA Diamond | 92.4 | 91.3 | 90.1 | — |
最有说服力的是 Terminal-Bench 2.0——模拟真实工程师在沙盒终端里干活、5 小时超时,Qwen3.7-Max 拿到 69.7,把 Opus 4.6、DeepSeek V4 Pro、Kimi K2.6 全部压一头,只输给 Opus 4.7(Anthropic 报数 77)。SWE-Verified 上跟 Opus 4.6 差 0.4 分,统计意义上等于打平。
第三方评测的数据 DataCamp 这篇 给出的画面跟阿里官方一致。
Qwen3.7-Max 价格与 API 接入
Qwen3.7-Max 在 Ofox 上的官方定价(同阿里百炼):
| 项目 | 价格 (per 1M tokens) | 说明 |
|---|---|---|
| 输入 | $2.5 | 约 ¥18 |
| 输出 | $7.5 | 约 ¥54 |
| 缓存命中(输入) | $0.25 | 1/10 单价,prompt caching 必开 |
| 上下文窗口 | 1M tokens | 同 Claude Opus 4.7 / 4.8 |
| 模型 ID | bailian/qwen3.7-max 或锁版本 bailian/qwen3.7-max-20260517 | 后者是 Code Arena 榜单上挂的快照 |
跟 Claude Opus 同价位对比的横向价目表:
| 模型 | 输入 (per 1M) | 输出 (per 1M) | 2:1 综合 | 上下文 |
|---|---|---|---|---|
| Claude Opus 4.8 / 4.7 | $5 | $25 | $11.67/M | 1M |
| Qwen3.7-Max | $2.5 | $7.5 | $4.17/M | 1M |
| Claude Sonnet 4.6 | $3 | $15 | $7/M | 1M |
| DeepSeek V4 Pro | $0.27 / $0.55 | $1.10 / $2.20 | ~$0.95/M | 128K |
| GLM-5.1 | $1.40 | $4.40 | $2.40/M | 202.8K |
按编码任务常见的 2:1 输入输出比例(喂大堆代码、回小段 patch):
- Claude Opus 4.7 / 4.8:($5 × 2 + $25 × 1) / 3 = $11.67/M tokens
- Qwen3.7-Max:($2.5 × 2 + $7.5 × 1) / 3 = $4.17/M tokens
Qwen 大约是 Opus 综合价的 36%。如果你团队当前每月 Opus 4.7 烧 2 万元在编码 agent 上,按 80/20 路由迁移(80% 流量走 Qwen、20% 留给 Opus 处理硬骨头),综合账单大约能压到 9500-10000 元——差不多对半砍,硬题还是走 Opus。
诚实的提醒:Qwen3.7-Max 偏冗长。DataCamp 那次长 agentic 评测里它生成了 9700 万 token,而所有参评模型的中位数是 2400 万——4 倍。如果你按 token 计费、且 prompt 不带”简洁回答”约束,实际账单会比 rate card 推算的更高。要做 A/B 验证以你自己的 prompt 模式为准,不要直接拿单价乘旧用量。
国内开发者关心的接入路径:Ofox 是 OpenAI 协议兼容网关,支持支付宝、微信、USDT 充值,不需要海外信用卡、不需要 VPN。模型详情、计费规则、缓存策略可以在 ofox.ai/zh/models/bailian/qwen3.7-max 直接看到。
怎么在 Ofox 上调
如果你的代码已经在用 OpenAI SDK,两行就能切:
from openai import OpenAI
client = OpenAI(
api_key="sk-of-...", # Ofox 的 Key
base_url="https://api.ofox.ai/v1",
)
response = client.chat.completions.create(
model="bailian/qwen3.7-max",
messages=[
{"role": "user", "content": "把这段 Python 函数重构得清楚一点……"}
],
)同一个 Key 还能直接切 Claude Opus 4.7、GPT-5.5、Gemini 3.1 Pro,做混合路由不用再换鉴权层。模型详情、定价、缓存策略可以在 ofox.ai/zh/models/bailian/qwen3.7-max 看到。
国内开发者关心的支付问题:Ofox 支持支付宝、微信、USDT,不需要海外信用卡,不用翻墙;和 硅基流动 vs ofox 平台对比 那篇里写的接入路径一致。
什么时候还是该用 Opus 4.7
Qwen3.7-Max 不是 Opus 的全场景替代品。下面这几种情况,溢价仍然值得:
- 30 分钟以上的连续 agent 任务。Qwen 在阿里基准里撑了 35 小时是真的,但那是阿里调好的场景。开放式的客户 agent 工作流跑长链路时,Opus 4.7 状态保持更稳——Code Arena 上 21 分 Elo 的差距(1562 vs 1541)会随任务长度放大。
- 安全审查、新颖算法设计这类硬推理。GPQA Diamond 92.4 vs 91.3 看着相近,但跑到 benchmark 分布外的题(新漏洞分析、形式化验证、架构 critique),Opus 4.7 的 xhigh 思考模式优势比榜单数字要明显。
- IDE 内交互式补全这类延迟敏感场景。Qwen 偏冗长 → 首 token 输出时间变长。如果你在 Cursor / Zed / Claude Code 里追的是手感跟手,反而要选更简洁的模型。
- 强中文文学创作不是 Qwen 主战场。它的中文很好,但写作风格更偏说明文;要文学性还得另选。
实际的玩法基本统一:Qwen3.7-Max 兜底日常编码流量,Opus 4.7 当 escalation。Claude Code 混合路由实战 里有具体怎么在工具链里切的写法。
写在最后
三个我觉得最值得记的点:
- 国产编码模型这次真的进了第一梯队。不是”价格便宜”四个字打发——是公开投票榜单上跟 Opus Thinking 差 1 个 Elo 点的真实位置。
- Qwen 这次走闭源是个分水岭。3.6 那一代还是开源旗舰,3.7 起阿里把”性能天花板”留给 API。需要本地化部署的团队,路径还在 Qwen 3.6 系列上;只要 API 能力的,直接看 3.7。
- 要不要切,A/B 一周就有答案。如果你每月 Opus 流量超过 5000 元,把同一批 prompt 同时跑 Qwen3.7-Max 和 Opus 4.7,看通过率和成本曲线在哪里交叉。比读任何 benchmark 文章都准。
更宽视角的对比可以看 AI 模型排行 2026 选型指南 和 Claude Opus 4.7 vs DeepSeek V4 Pro 旗舰对比。
延伸阅读
- Claude Opus 4.7 vs DeepSeek V4 Pro 国内开发者旗舰选型 — 国产旗舰跟 Claude 顶配的硬碰硬
- AI 模型排行选型指南 2026 — 中场模型排位的全景
- Claude Code vs Codex CLI vs Cursor vs DeepSeek TUI — 把 Qwen 接进编码工具链的几种主流方式
- 硅基流动 vs Ofox vs OpenRouter 中转站对比 — 国内调 Qwen/Claude 的接入路径对比