Qwen 3.7 Max vs Claude Opus 4.7: Code Arena #4 at 1/3 the Price
Qwen 3.7 Max hits Elo 1541 (#4 WebDev) at $2.50/$7.50 per 1M tokens — a third of Claude Opus 4.7. Where Opus 4.8 pulls ahead and when Qwen wins on price-performance.

TL;DR — Alibaba’s Qwen 3.7 Max shipped on May 19 2026 and a week later landed at #4 on the Code Arena WebDev leaderboard with an Elo score of 1541, one point behind Claude Opus 4.6 Thinking and ahead of every non-Anthropic model in the top tier. It’s priced at $2.50/M input and $7.50/M output — roughly a third of what Claude Opus 4.7 charges for the same kind of work. The catch: it’s closed-weight, and it’s verbose. The pragmatic move is to route the daily coding grind through Qwen 3.7 Max and keep Opus 4.7 for the calls that justify the premium.
A model that lands one Elo point off Claude Opus 4.6 Thinking on a public coding leaderboard, at a third of the per-token price, is the kind of release that quietly rewrites the routing layer in a lot of stacks.
What actually shipped
Alibaba previewed Qwen 3.7 Max at the May 20 2026 Cloud Summit in Hangzhou, but the commercial API quietly went live on Model Studio a day earlier. The model is a 1M-token context, closed-weight flagship — a notable departure from Alibaba’s earlier Qwen 3.6 line, which still ships open under Apache 2.0. The 3.7 generation is API-only, at least for the foreseeable future.
What makes it interesting isn’t the spec sheet, it’s the leaderboard placement. Within the first week of public availability, Qwen 3.7 Max showed up at the top of Code Arena’s WebDev category — the front-end web development track that scores models on agentic coding workflows requiring multi-step reasoning and tool use.
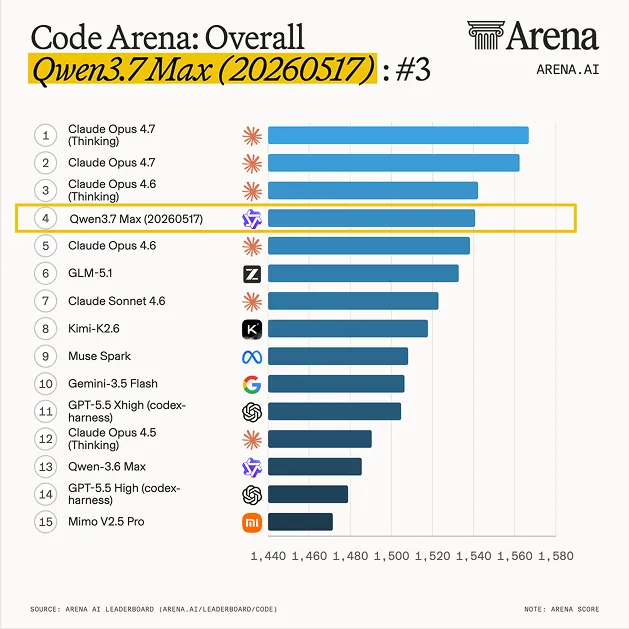
The May 24 snapshot of Code Arena WebDev (328,594 votes, 81 models):
| Rank | Model | Elo | Price (in/out per 1M) | Context |
|---|---|---|---|---|
| 1 | claude-opus-4-7-thinking | 1567 | $5 / $25 | 1M |
| 2 | claude-opus-4-7 | 1562 | $5 / $25 | 1M |
| 3 | claude-opus-4-6-thinking | 1542 | $5 / $25 | 1M |
| 4 | qwen3.7-max-20260517 | 1541 | $2.50 / $7.50 | 1M |
| 5 | claude-opus-4-6 | 1538 | $5 / $25 | 1M |
| 6 | glm-5.1 | 1533 | $1.40 / $4.40 | 202.8K |
| 7 | claude-sonnet-4-6 | 1523 | $3 / $15 | 1M |
| 8 | kimi-k2.6 | 1518 | $0.95 / $4 | 262K |
The position is still marked preliminary — Qwen 3.7 Max has 1,522 votes against Opus 4.6’s 8,889, and the listed rank spread is 2–8 with 16 Elo of uncertainty. That’s real wiggle room. But even on the pessimistic end of that spread, it’s tied with vanilla Opus 4.6 at less than half the per-token price. On the optimistic end, it’s nipping at Opus 4.7’s heels.
The 35-hour autonomous run
The detail that hints at where Qwen 3.7 Max actually earns its placement is buried in Alibaba’s release material: a sustained 35-hour autonomous run optimizing a kernel for one of Alibaba Cloud’s custom chips. The model issued 1,158 tool calls without losing the plot, and reportedly hit a 10× geometric mean speedup on the target workloads.
You don’t need to take the headline at face value to find the engineering interesting. A 35-hour single-task agent loop with over a thousand tool calls is the kind of duration that breaks most current frontier models — context windows collapse, the model forgets what it’s optimizing for, or the tool-call format drifts and the loop dies. Qwen 3.7 Max held the thread.
The benchmark numbers that line up with this hold up reasonably well:
| Benchmark | Qwen 3.7 Max | Claude Opus 4.6 | DeepSeek V4 Pro | Kimi K2.6 |
|---|---|---|---|---|
| Terminal-Bench 2.0 Terminus | 69.7 | 65.4 | 67.9 | 66.7 |
| SWE-Bench Pro | 60.6 | — | 59.0 | 59.5 |
| SWE-Bench Verified | 80.4 | 80.8 | 80.6 | — |
| MCP-Atlas | 76.4 | 75.8 | — | — |
| GPQA Diamond | 92.4 | 91.3 | 90.1 | — |
Terminal-Bench 2.0 is the one that matters here — it simulates a real software engineer working in a sandboxed terminal with a five-hour ceiling, and Qwen 3.7 Max tops every other published flagship except Opus 4.7 (which scored 77 on the same benchmark per Anthropic’s own reporting). On SWE-Verified the gap to Opus 4.6 is statistical noise — 80.4 vs 80.8.
The numbers reported by DataCamp confirm the same picture from a third-party evaluation perspective.
The pricing math
Claude Opus 4.7 is $5/M input and $25/M output (Anthropic’s pricing page). Qwen 3.7 Max on Ofox is $2.50/M input, $7.50/M output, with cached input at $0.25/M.
For a 2:1 input-to-output ratio — about what most coding agents run when they’re feeding back diffs and getting smaller patches in return — the blended cost works out to:
- Claude Opus 4.7: ($5 × 2 + $25 × 1) / 3 = $11.67/M tokens
- Qwen 3.7 Max: ($2.50 × 2 + $7.50 × 1) / 3 = $4.17/M tokens
That’s 36% of Opus’s blended rate. If your team currently burns $3,000/month on Opus 4.7 for coding traffic, routing 80% of that to Qwen 3.7 Max and keeping the hard 20% on Opus gets you to roughly $1,500/month — about half the bill, with the tough queries still on the flagship.
The honest caveat: Qwen 3.7 Max is verbose. DataCamp observed it generating 97M tokens on a long agentic evaluation where the median across models was 24M. If your traffic is verbosity-sensitive (you’re paying per token, not per task), measure before you migrate. The arithmetic still favors Qwen comfortably, but the spread is narrower than the rate-card delta suggests.
Calling it from your code
If you’re already on the OpenAI SDK, the migration is two lines. Ofox exposes Qwen 3.7 Max behind an OpenAI-compatible endpoint, so the request shape, streaming, and function calling all stay identical.
from openai import OpenAI
client = OpenAI(
api_key="sk-of-...",
base_url="https://api.ofox.ai/v1",
)
response = client.chat.completions.create(
model="bailian/qwen3.7-max",
messages=[
{"role": "user", "content": "Refactor this Python function for clarity..."}
],
)The same key also gets you Claude Opus 4.7, GPT-5.5, Gemini 3.1 Pro, and the rest. Switching models for a single call is a string change — useful when you want to escalate a tough query without re-plumbing your auth layer.
For a deeper walkthrough of the OpenAI SDK migration pattern, the OpenAI SDK to Ofox migration guide covers the edge cases (custom headers, retry behavior, streaming differences).
Qwen 3.7 Max vs Claude Opus 4.8: what changes with the new flagship
Anthropic shipped Claude Opus 4.8 on May 28, 2026 — one day after Qwen 3.7 Max settled at #4 on the Code Arena WebDev board. The headline isn’t a price cut: Opus 4.8 ships at the same $5/$25 per 1M as 4.7. What changed is that Opus 4.8 now scores 69.2% on SWE-bench Pro (Qwen 3.7 Max sits at 60.6%) and tops the independent GDPval-AA leaderboard at 1890 Elo, +137 over Opus 4.7. So on raw quality the gap to Qwen widened. On per-token cost, nothing moved.
The arithmetic with Opus 4.8 in the mix:
| Model | Strength | Price (in/out per 1M) | 2:1 blended | When to pick it |
|---|---|---|---|---|
| claude-opus-4-8 | SWE-Pro 69.2%, GDPval-AA 1890 Elo, ~35% fewer output tokens than 4.7 | $5 / $25 | $11.67/M | Hard 20% — agentic loops, security review, novel reasoning |
| claude-opus-4-7-thinking | Code Arena Elo 1567 | $5 / $25 | $11.67/M | Production stability if you’ve already tuned prompts for 4.7 |
| qwen3.7-max | Code Arena Elo 1541, Terminal-Bench 2.0 69.7%, SWE-Pro 60.6% | $2.50 / $7.50 | $4.17/M | Volume coding traffic |
| glm-5.1 | Code Arena Elo 1533, cheapest in top 10 | $1.40 / $4.40 | $2.40/M | Cost-floor experiments, 200K context fine |
If you’re swapping the escalation target from Opus 4.7 to Opus 4.8, two API-level changes will break naive callers:
- Adaptive thinking — the old
thinking: {type: "enabled"}no longer applies. Usethinking: {type: "adaptive"}(see Anthropic’s adaptive thinking docs). Extended-thinking budgets are still unsupported on 4.8; the interleaved-thinking beta header is now ignored. - Effort default is high. On Claude Code, on the API, on the apps — Opus 4.8 defaults to high effort everywhere. If you were calling 4.7 with default settings and tuning for cost, your 4.8 bill per call will look different until you set effort explicitly.
On Ofox, both models sit behind the same OpenAI-compatible endpoint, so the model swap is still a string change:
# Volume coding traffic
response = client.chat.completions.create(model="bailian/qwen3.7-max", ...)
# Escalation to flagship
response = client.chat.completions.create(model="anthropic/claude-opus-4.8", ...)For the full Opus 4.8 review — Fast Mode, dynamic workflows in Claude Code, and the migration checklist from 4.7 — see Claude Opus 4.8: Benchmarks, Fast Mode, and What Actually Changed.
Where Opus still earns the premium
Qwen 3.7 Max doesn’t replace Claude Opus 4.7 for everything. The cases where the premium pricing still pays back:
- Hard agentic loops past the 30-minute mark. Qwen 3.7 Max held a 35-hour run on a single optimization task — impressive — but that was a benchmark scenario tuned by Alibaba. In open-ended customer agentic workflows, Opus 4.7 still maintains state more reliably across 1,000+ tool calls. The Code Arena gap of 21 Elo points (1562 vs 1541) compounds on long tasks.
- Security review and novel reasoning. GPQA Diamond is 92.4 vs Opus 4.6’s 91.3 — close — but on tasks that lean on reasoning beyond the benchmark distribution (novel exploits, formal verification, architectural critique), Opus 4.7’s xhigh thinking mode still pulls ahead more than the benchmark gap suggests.
- Latency-sensitive interactive editing. Qwen 3.7 Max is verbose, which means longer time-to-first-useful-output. If you’re using AI in tight IDE autocomplete loops, the latency profile of a less chatty model matters.
- English-first writing tasks. Qwen is comfortably bilingual and strong at Chinese, but for pure English prose generation Opus still has the edge for some teams.
The pattern most experienced teams settle into is hybrid routing: Qwen 3.7 Max as the default for volume coding traffic, Opus 4.7 as the escalation target for the hard 20%. The LLM API selection decision matrix walks through how to wire that routing if you don’t already have it.
What this actually means
Three honest takeaways:
- The “best coding model” tier no longer belongs exclusively to Anthropic. Qwen 3.7 Max joining the top five on a public, vote-driven leaderboard at a third of the price is a meaningful shift in the price-performance frontier — bigger than benchmark blog posts usually let on.
- Closed-weight Qwen is a strategic departure for Alibaba. Qwen 3.6 still ships open, which means the open-weight option remains live for teams that need it. But the bleeding-edge capabilities are now API-only.
- The right move for most production teams is not “rip out Claude and switch to Qwen” — it’s “add Qwen to the router and watch where the cost-of-quality curve actually bends.” If you’re spending $1,000+/month on Opus traffic, an A/B with Qwen 3.7 Max on the same prompts will tell you within a week whether the routing math holds up for your specific workload.
For the broader landscape of how the coding model field looks in mid-2026, the best LLM for coding (ranked by real use) is the companion piece. For where Qwen sits in the larger model family, the Qwen3 access guide via Ofox is the practical starting point.
The hard part of evaluating a new model release isn’t reading the benchmark table — it’s running your own prompts through it and seeing how it compares on the queries that actually matter to you. With Qwen 3.7 Max sitting one endpoint swap away on Ofox, that experiment is a five-minute setup.
Related reading
- Claude Opus 4.8 Release Review: Benchmarks, Fast Mode, and What Actually Changed — Opus’s response to the Qwen 3.7 Max pressure, the model you’d escalate the hard 20% to
- Claude Opus 4.7 API Review and Upgrade Guide — the price-class comparison Qwen 3.7 Max disrupts most directly
- Qwen 3.6 27B vs Claude Opus 4.6 for Coding — the open-weight Qwen sibling head-to-head
- Best LLM for Coding Ranked by Real Use — the full mid-2026 coding model landscape
- Qwen3 API Guide via Ofox — how to access the broader Qwen family on one key
- OpenAI SDK Migration to Ofox — the migration pattern that gets Qwen, Claude, and GPT behind one endpoint


